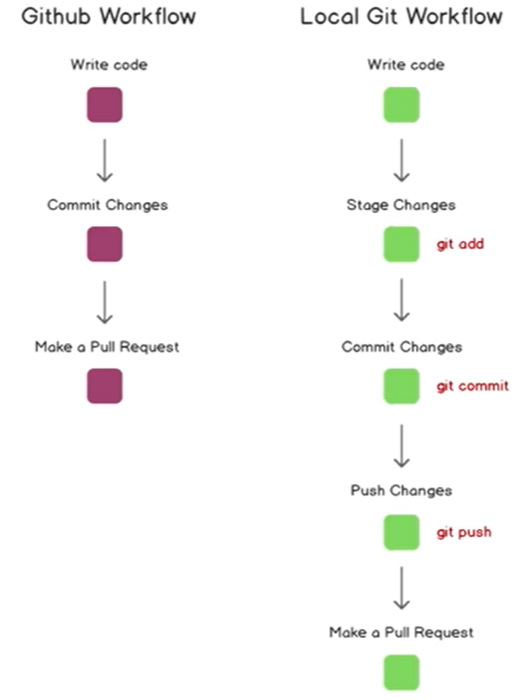
- Distribuited workflow
- Git Server
- Git Client
- Come funziona Git
- Configurazione e preparazione di repository Git (config, init, clone)
- Salvare modifiche (add, commit, diff, stash)
- Annullare modifiche (checkout, restore, clean, revert, reset, rm)
- Ispezionare un repository (status, log, show, tag, blame, shorlog, bisect, describe)
- Riscrivere lo storico (rebase, cherry-picking, commit –amend)
- Collaborazione (fetch, push, pull, merge, remote)
- Lavorare con i rami (branch, switch)
- Aggiungere un progetto esistente a github tramite linee di comando
- Recap comandi Git
- Risorse
Distribuited workflow
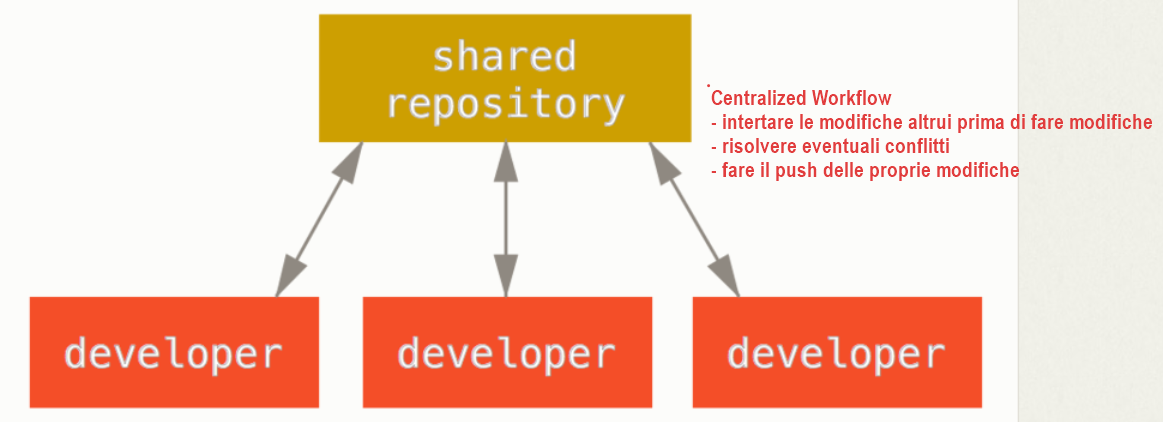
- Modello di collaborazione centralizzato (Centralized workflow)
- Centralized system (CVCS)
- In un sistema centralizzato ogni sviluppatore è un nodo che intergagisce più o meno nello stesso modo con un hub centrale o repository.
- Il ‘centralized workflow’ è generalmente l’unico modello di collaborazione In un sistema centralizzato.
- Come funziona
- Unico repository => L’ hub centrale accetta codice da tutti gli sviluppatori e tutti sincronizzano il proprio lavoro con esso.
- Gli sviluppatori (contributor) iniziano facendo un clone del repository centrale sul proprio computer cosi di avervi accesso diretto tramite push e pull
- Primo contributor (push)
-
-
- Apporta delle modifche e ne fa il push
- Secondo contributor (merge + eventuale gestione dei conflitti + push)
- Un secondo sviluppatore per non sovrascrivere le modifiche del primo sviluppatore deve farne il merge
- Se ci sono dei conflitti mentre fa un pull, deve risolverli e fare il push delle modifiche necessarie.
- Solo dopo può apportare le proprie modifiche e farne il push
- Un secondo sviluppatore per non sovrascrivere le modifiche del primo sviluppatore deve farne il merge
-
- Questo modello può funzionare perfettamente anche in Git.
- Settare un solo repository
- Dare a tutti i membri del team l’accesso al push
- Ovviamente Git non permetterà che gli utenti sovrascrivano il lavoro degli altri obbligandoli a fare un merge prima di proseguire con il loro push
- E’ ipotizzabile per piccoli gruppi di sviluppo
- Centralized system (CVCS)
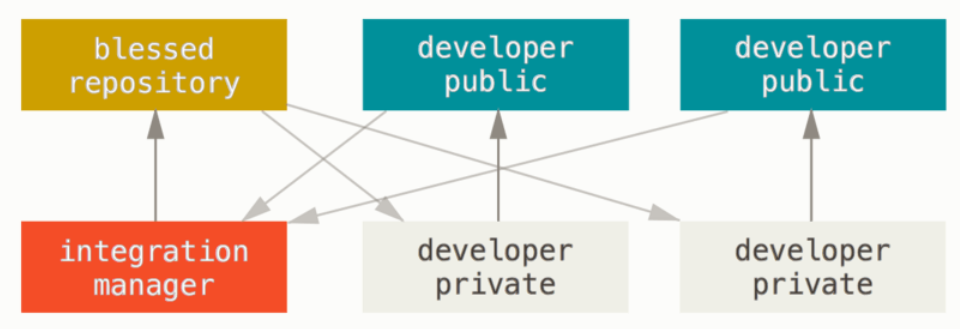
- Modello di collaborazione Integration-manager (Intergration manager workflow)
- Distribuited System
- Ogni utilizzatore può essere potenzialmente sia un nodo che un hub
- Molti repository =>
- In un sistema distribuito è possobile creare molti repository e gestirne le autorizzazioni (di lettura e scrittura)
- E’ possibile quindi creare diversi tipi di workflow o modelli di collaborazione
- Come funziona
- Repository ufficiale
- Viene creato un ‘repository ufficiale’ che conterrà la versione ufficiale e più aggiornata del nostro progetto.
- Normalmente gli sviluppatori (contributor) non hanno diritto di push su di esso
- Fork
- Un nuovo contributor per poter contribuire al progetto non avendo accesso diretto al repository ne fa un fork
- Crea cioè un repository pubblico clone di quello ufficiale (snapshot) dove avrà diritto di push
- Simultaneamente clona il progetto anche sul proprio computer.
- Push nel proprio Fork
- Ogni sviluppatore può fare il push delle sue modifiche nel proprio fork
- Pull request
- Dopo aver fatto il push nel proprio fork è possibile inviare una richiesta di pull al maintainer
- Nel frattempo posso continuare eventualmente a sviluppare lo stesso file. Le nuove modifiche faranno parte anch’esse della pull request
- In altre parole, la pull request resta collegata e sincronizzata con il ramo che l’ha create.
- Mantainer
- ll mantainer riceve le richieste di pull
- Aggiunge il repository dello sviluppatore che ha fatto la richiesta come remoto
- Verifica la bontà del codice scritto dal contributor integrandolo nel repository sul suo proprio computer
- Ne fa il push nel ‘repository ufficiale’
- Repository ufficiale
- Distribuited System
Git Server
- Cosa offre un Git Server =>
- Version control
- Il server è ospita il repository che verrà distribuito ai vari collaboratori
- Gestione dei progetti e dei task
- Revisione del codice
- CI/CD
- Gestione dei packaging
- E’ possibile ospitare e condividere packages e immagini (Nuget, Npm, Docker)
- Code security scanning
- Esistono diversi tools che possono scorre un repository e trovare delle vulnerabilità al codice sviluppato
- Version control
- Lista principali Git Server =>
- Azure DevOps
- AWS CodeCommit
- BitBucket
- GitHub
- Cosa è =>
- VCS git => GitHub è una piattaforma web che incorpora il VCS (Version Control System) git e lo rende più semplice
- Hosting => GitHub fornisce un hosting per repository git e strumenti per la gestione dei progetti
- Github implementa l’integration manager workflow (vedi sopra)
- Memorizzare credenziali =>
- Se si lavora trami SSH si utilizza un token di sicurezza.
- Se si dialoga con il server github remoto tramite HTTP bisogna fornire le credenziali ad ogni iterzione. Per facilitare la cosa è possibile salvare le credenziali in locale
- Salvare le credenziali
- per 15 minuti =>
-
git config --global credential.helper cache
-
- permanentemente ma in chiaro =>
-
git config --global credential.helper store
-
- usando l’helper git credential manager core
- Dopo aver eseguito correttamente l’autenticazione, le tue credenziali vengono archiviate in Gestione credenziali di Windows
- Verranno utilizzate ogni volta che cloni un URL HTTPS.
- Git non ti richiederà di digitare nuovamente le tue credenziali nella riga di comando a meno che tu non modifichi le tue credenziali
-
git credential-helper-selector
- per 15 minuti =>
- Aggiungere collaboratori =>
- Normalmente anche se abbiamo creato un progetto su github come public nessuno tranne il maintainer può farne dei push.
- Il maintainer può tramite invito aggiungere dei collaboratori:
- Settings => Collaborators => Add people => Inserire email e validare la mail di conferma.
- Attività principali =>
- Fork =>
- da fare solo la prima volta
- copiare il repository ufficiale (upstream repository) per poterlo poi clonare e modificare in locale.
- Clone =>
- da fare solo la prima volta
- una volta che si è fatto il fork (dal sito github.com) è possibile copiare il progetto in locale recuperandone l’indirizzo HTTPS o SSH e usando il comando clone .
- Fork =>
- Cosa è =>
-
-
-
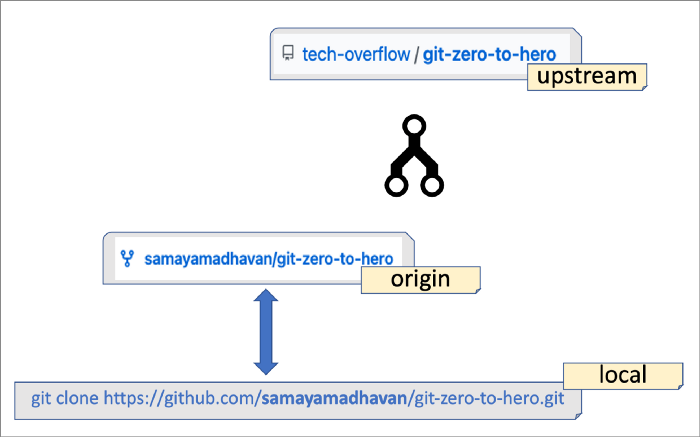
- Origin:
- E’ il puntatore al repository fork che abbiamo clonato in locale.
- Il contributor non può interagire direttamente con esso.
- Fetch
- E’ come update di SVN
- Permette di sincronizzare nel proprio repository locale il puntatore origin/master
- Dopodichè è possibile fare il merge delle modifiche (gestendo eventuali conflitti prima).
- Pull (Fetch + Merge)
- Il comando pull sincronizza il repository locale con le modifiche fatte nel repository remoto.
- senza rebase: nel repository locale viene creato un nuovo commit con l’unione delle modifiche presenti in locale e quelle fatte in remoto (three-way merge).
- con rebase: sposta la base del puntatore master locale allineandolo al puntatore master remoto.
- Push
- Sincronizza il repository remoto con le modifiche che abbiamo fatto in locale
- Riposiziona i puntatori in remoto e in locale.
- L’operazione può fallire se nel frattempo qualcuno ha messo delle modifiche in remoto,
- nel caso prima di procedere bisogna fare il pull (e gestire eventuali conflitti).
- Le prima volta che si fa il push di un ramo in remoto è necessario usare il comando -u .
- Tag
- I tag creati in locale non sono subito visibili nel repository fork, bisogna esplicitamente farne il push (vedi capitolo riservato ai tag)
- Release =>
- In github è possibile creare delle release (associate a dei tag) che includono l’ultimo commit ed eventuali file binari con la versione compilata della nostra release.
- Branch =>
- Come per i tag, i rami che creo in locale per essere condivisi con gli altri contributor devo fare in modo che il sistema remoto li conosca e inizia a farne il tracking (vedi capitolo riservato al branching)
- Origin:
- Attività aggiuntive =>
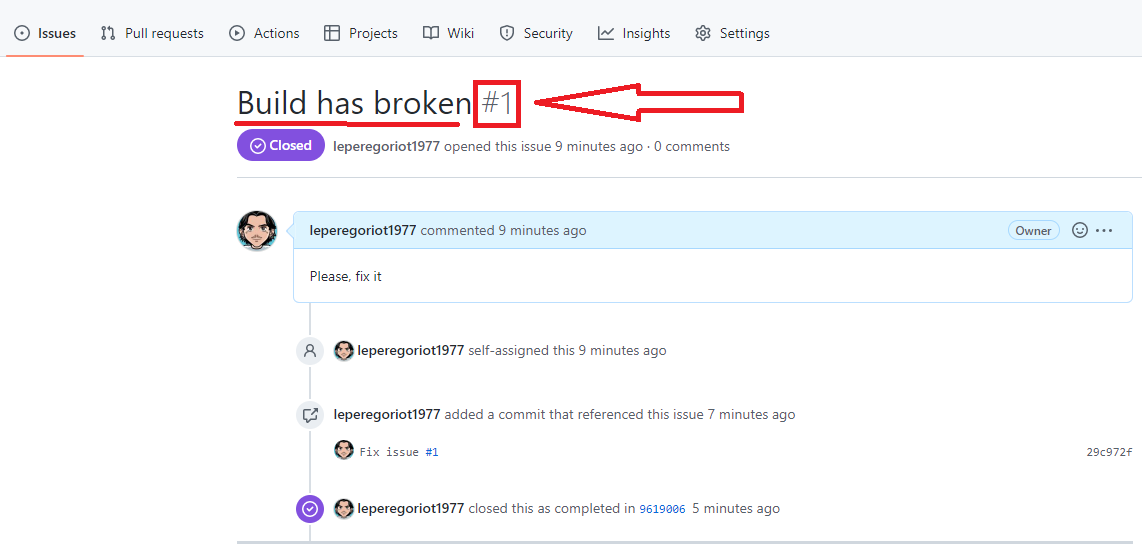
- Issue =>
- è possibile creare un issue ed eventualmente trasformarlo in pull request.
- E’ possibile legare automaticamente un issue e il commit che lo risolve semplicemente aggiungendo al messaggio l’identificativo del issue più la parola ‘resolves’
- Issue =>
-
-

-
-
-
- Label => è possibile customizzare le label da assegnare poi agli issue o ai commit
- Milestone => è possibile creare delle milestone e associarle agli issue e visualizzare lo stato di avenzamento degli issue collegati alla particolare milestone.
- Aprire le cartelle in Visual Studio Code online
- Esempio di workflow:
- Contributor 1
-
//Crea un ramo direttamente su github e lo importa nel suo repository locale
git fetch [opzionale origin] [faccio sapere al git locale che in remoto (nel fork) è stato aggiunto un ramo
(remote tracking branch)]
git switch -C <ramo_nome_locale> <ramo_nome_remoto_da_mappare> [creo un ramo locale che mappa il ramo che creato su github]
-
- Contributor 2 deve lavorare su quel ramo.
-
//Clona il progetto
git clone <url_repository_remoto>
//Mappa un ramo locale con il remo remoto
git switch -C <ramo_nome_locale> <ramo_nome_remoto_da_mappare> [creo un ramo locale che mappa il ramo che creato su github]
//Dopodiché crea una modifica e ne fa il commit nel fork
git commit -m "nuova modifica
-
- Mantainer
-
//Il mantainer fa il pull delle modifiche fatte dal contributor sul suo repository locale
git pull [il maintainer copia nel sul locale le modifiche fatte dal contributor.
Si trova un ramo nuovo]
//Le controlla e poi le aggiunge al ramo master.
git switch master [poi passa al ramo master in locale]
git merge <ramo_nome_locale> [poi allinea nel suo repository il ramo master con il ramo che ha appena importato]
//Infine le mette sul fork (github)
git push [allinea il repository fork con il suo, aggiungendone le modiche fatte dal contributor]
//una volta apportate le modifiche sul fork
//il maintainer può eliminare il ramo sul fork e nel suo computer
git push -d origin <ramo_nome_locale> [elimina il dato ramo nel repository origin]
git branch -d <ramo_nome_locale
-
- Contributor 2
-
//Deve allineare il suo repository locale con il tracking remoto
//Eliminare il ramo usato per le modifiche ormai presenti nel fork
git pull
git branch -d <ramo_nome_locale>
git remote prune origin [eliminare il ramo remoto che non esiste più ed è untracked perciò il solo fetch non basta]
-
- Contributor 1
-
- GitLab
- Consente di memorizzare il codice (in repository) e utilizzare le funzionalità di controllo della versione di git.
- Include l’integrazione continua (CI) che elimina la necessità delle ‘pull request’ utilizzate in GitHub
- Pull Request
- Permettono di integrare un nuovo ramo al ramo principale dopo una verifica da parte delle persone che gestiscono il repository
- Si crea così un meccanismo di revisione del codice prima di integrarlo sul ramo principale su cui gli altri contributori stanno lavorando.
- Permette così di contribuire ad un repository di cui non si ha il permesso di accesso.
-
Git Client
- Esistono almeno 3 possibilità quando si cerca un Git client
- CLI (Command Line Interface)
- Scelta migliore se si conosce già Git
- E’ possibile automatizzare le operazioni
- IDE
- Ospitano delle versione di Git client semplificate
- Ottimi per le operazioni ordinarie di tutti i giorni
- GUI (Graphical User Interface)
- Ottimi se si è in fase di apprendimento di Git
- CLI (Command Line Interface)
- Lista principali Git Client
- Merge tools Kdiff / P4Merge / WinMerge
Come funziona Git
- Cosa è Git =>
- Version control =>
- Git è un sistema di controllo della versione (CVS) distribuito gratuito e open source.
- Single point failure =>
- I sistemi distribuiti risolvono il problema che hanno i sistemi di versioning centralizzati (come SVN, TFS) del single point of failure dando a ogni utente l’intero storico del progetto (come Mercurial)
- Branching =>
- E’ possibile creare un o più branch in modo facile e senza alcun problema
- File container =>
- Permette di memorizzare il codice dei propri progetti
- Documenti e presentazioni (Markdown)
- Meglio evitarlo per file di grandi dimensioni (usare al posto Git LFS)
- Supporta la collaborazione in un team decentralizzato
- Archivia una copia del tuo codice su server remoti
- Ognuno ha una copia dell’intero repository
- Consenti a più persone di contribuire facilmente alle modifiche
- Version control =>
- Principali attività svolte
- Creare snapshot
- Browsing l’history del progetto
- Branching and merging
- Rewrite dell’history
- Collaborare con Github
- Repository =>
- E’ uno speciale database dove sono memorizzate tutte le modifiche.
- remote repository:
- E’ il repository originale (per esempio su GitHub o BitBucket) che tutti i membri del gruppo di lavoro usano per scambiarsi le modifiche.
-
- local repository :
- La directory di lavoro sulla macchina locale. Per poter allineare il fork con il repository remoto posso allineare il mio repository locale e poi fare il push nel repository fork
-
git fetch upstream [permette di riallineare il repository locale con il repository remoto]
git merge upstream/master [permette di importare nel repository locale tutte le modifiche nel repository remoto]
git push [opzionale origin] [permette di allineare il reposotory fork con le modifiche che c'erano
nel repository remoto dopo aver importare in locale]
-
- La directory di lavoro sulla macchina locale. Per poter allineare il fork con il repository remoto posso allineare il mio repository locale e poi fare il push nel repository fork
- Forking workflow =>
- Molti git workflow utilizzano un solo repository ‘centrale’ lato server.
- Questo forwflow offre anche a ogni sviluppatore un proprio repository lato server.
- Ciò significa che ogni contributore non ha uno, ma due repository Git:
- uno privato locale
- uno pubblico lato server.
- Usato spesso nei progetti open source pubblici.
- Esistono 2 repository remoti =>
- upstream or base (the forked)
- E’ il puntatore al repository originale remoto (una volta eseguito il fork).
- Da utilizzare per mantenere la copia locale sincronizzata con il progetto remoto (scambio monodirezionale)
-
// abilita il tracking di <upstream> per tenere sincronizzato <origin>
// il comando clone non aggiunge automaticamente questo repository remoto, va aggiungo manualmente:
git remote add upstream git://github.com/<aUser>/<aRepo.git>
git pull upstream [sincronizza il repo locale con le modifiche fatte sul progetto originale
dagli altri contributors]
- origin (the fork)
- E’ il puntatore al repository fork in remoto (scambio biridezionale)
- upstream or base (the forked)
- local repository :
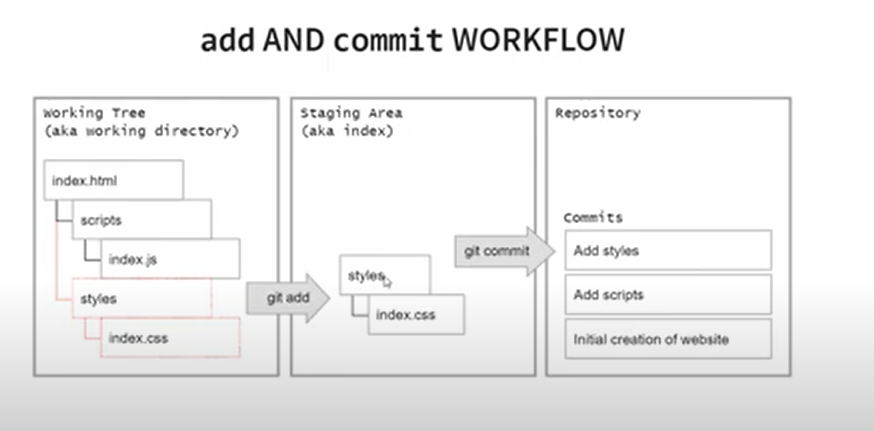
- Add and commit workflow
- Stage =>
- prima di poter eseguire il commit delle modifiche in Git, è buona prassi farne lo stage: ciò dà la possibilità di preparare il tuo codice prima di aggiungerlo formalmente al tuo progetto (ad esempio è possibile scegliere di far il commit di una sola parte di un file mettendola appunto in stage).
- Commit =>
- ll comando utilizzato per salvare le nuove modifiche al tuo progetto nel repository. Ogni commit contiene:
- ID (revision number generato automaticamente da git)
- Messaggio
- Data/ora
- Autore
- Snapshot completo del progetto => (1) git non memorizza solo le modifiche ma il contenuto completo perciò è molto veloce fare delle attività di restore da snapshot precedenti.
- ll comando utilizzato per salvare le nuove modifiche al tuo progetto nel repository. Ogni commit contiene:
- Stage =>
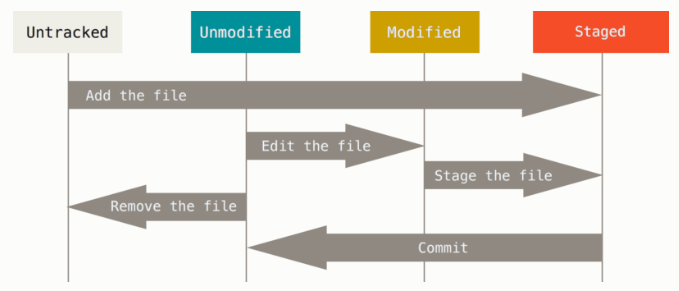
- Stato dei file
- Untracked =>
- I file untracked sono quelli non ancora versionati da git (i nuovi file aggiunti nel ripositori locale).
- A questo punto esiste ancora la possibilità di ritornare ritornare al precedente stato e apportare nuove modifiche ai file.
- Staged =>
- I file staged sono quelli messi in staging quindi aggiungi al tracking ma non ancora committati.
- add fa passare un file da Untracked => Staged. . .
- Modified =>
- I file modified sono quelli che hanno subito delle modifiche dopo che sono stati committati un prima volta
- modificare un file precedentemente committato fa passare da Unmodified => Modified
- Unmodified =>
- sono i file su cui ho lavorato e che hanno creato un nuovo shapshot che è stato memorizzato permanentemente del git repository locale.
- commit fa passare da Staged -> Unmodified
- Untracked =>
- History =>
- E’ possibile navigare l’albero di tutte le modifiche effettuate ai file traccati in git
- Remote =>
- In un ambiente collaborativo normalmente un repository locale è strettamente collegato ad un repository remote (ospitato su un Git server)
- E’ possibile far puntare un cartella locale a più di un repository remote (per esempio ospitati su differenti git server)
- Stato ‘detached’
- Quando da locale ci si connette ad un ramo remoto, questo avviente in modo detached per motivi di sicurezza
- Infatti non è possibile fare dei commit diretti sul ramo remoto.
- I rami remoti si aggiornano solo per riflettere le modifiche fatte nel repository remoto (non si posso fare commit!)
- Use cases => Sincronizzare una cartella locale già esistente con un repository remoto
- Posizionarsi con la shell nella cartella locale
- Lanciare il comando Init
- Collegare manualmente il repository git locale con quello remoto (git remote add)
- Fare il push per trasferire i file locali nel repository remoto
- Branch =>
- Fare il branch permette di avere versioni differenti dello stesso repository contemporaneamente.
- Concettualmente un branch può essere inteso come un workspace isolato e separato.
- Buona prassi =>
- I rami sono molto veloci da creare e eliminare, quindi è buona prassi usarli per isolare le modifiche
- All’inizio di ogni modifica creare un <nuovo_ramo> su cui lavorare. Dopodiché solo alla fine della modifica se ne farà il merge sul ramo <main>
- Non tutti i rami creati verranno sincronizzati con il repository remoto facendone il push. Ma molti verranno semplicemente eliminati una volta concluso lo sviluppo dello stint.
- Funziona in modo completamente diverso e più rapido degli altri programmi di versioning =>
- Creare un nuovo branch (2) non significa copiare l’intero progetto ma semplicemente creare un nuovo puntatore all’ultimo commit
- Tale nuovo puntatore resterà legato alle modifiche fatte nel nuovo branch senza modificare il ramo master.
- Git conosce l’ultimo commit in ogni ramo.
- head => identifica il ramo corrente
- master/main => indentifica il ramo principale (che punta all’ultimo commit effettuato)
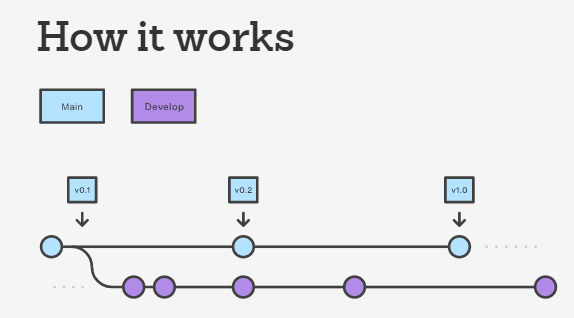
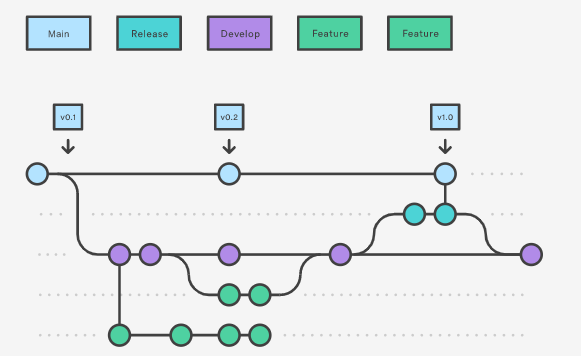
- Possibili strategie di branching =>
- GitHub flow
- Ho un ramo long-running (main) e tanti rami con lo sviluppo di nuove features
- I commit sono più lunghi
- Ideale per gruppi di lavoro più piccoli
- GitHub flow
-
-
- GitFlow
- Ho 2 o più rami long-running (production, integration, develop) + rami con lo sviluppo di nuove features + rami per il rilascio
- I commit sono più brevi
- GitFlow
-
- Merge (applicare le modifiche di un ramo ad un altro) =>
- Buona prassi =>
- Per evitare di dover gestire un numero troppo grosso di eventuali conflitti è indicato fare il merge delle proprie modifiche spesso
- La mattina è bene fare il merge nel ramo <main> nel ramo su cui sto lavorando (per allinerami con le modifiche che la giornata precedente i miei colleghi hanno apportato)
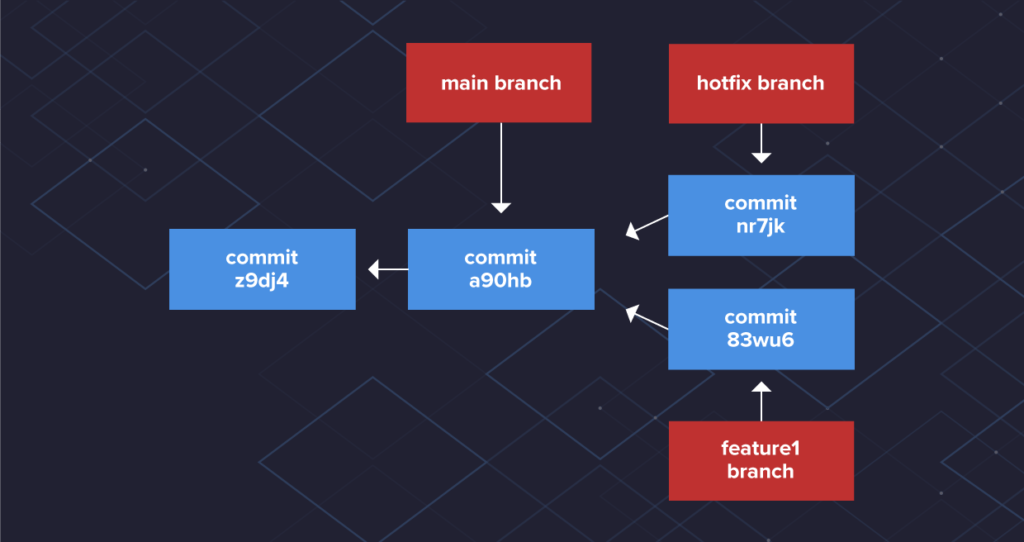
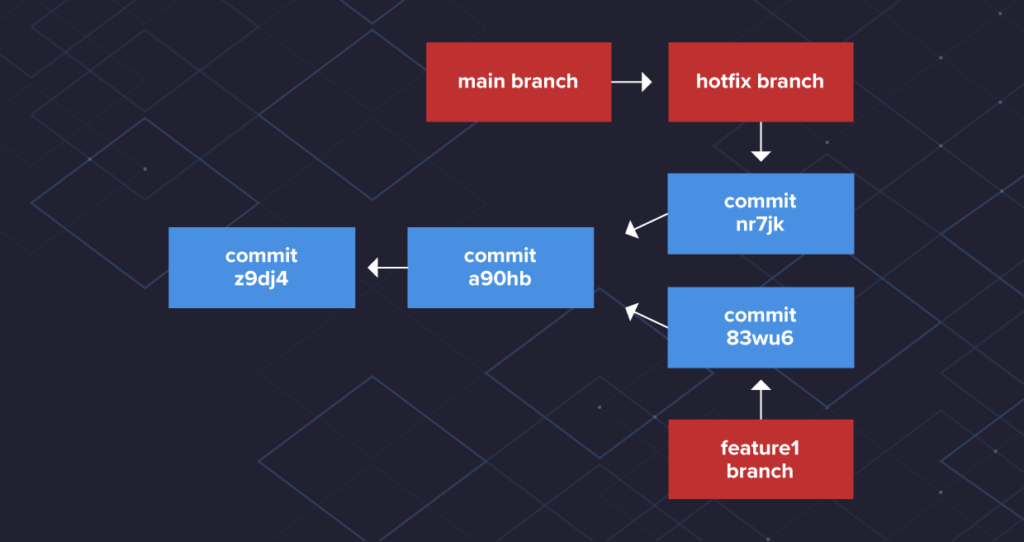
- Fast-forward:
- I due rami da mergiare non si sono discostati
- Se non c’è nessun commit aggiuntivo nel ramo d’origine (cioè le uniche modifiche sono quelle che ho apportato nel ramo da mergiare su cui ho lavorato)
- allora (3) l’unica cosa da fare è spostare il puntatore del ramo in cui voglio apportare le modifiche all’ultimo commit del ramo dove ho apportato le modifiche.
- Esempio =>
- Quando si fa il merge del ramo hotfix nel ramo principale, Git sposta il puntatore del ramo principale in avanti per inglobare il commit nr7jk.
- Git esegue questa operazione perché il ramo dell’hotfix condivide un commit diretto predecessore con il ramo principale ed è direttamente prima del suo commit.
- I due rami da mergiare non si sono discostati
- Buona prassi =>
-
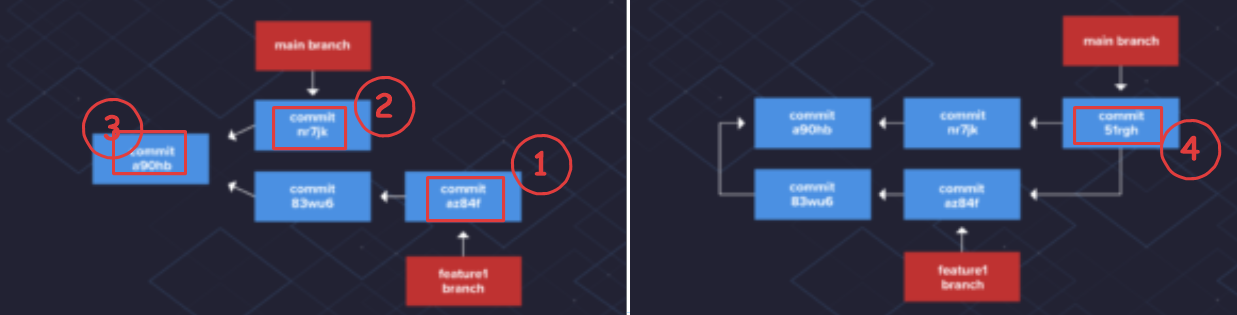
- Three-way:
- I due rami da mergiare si sono discostati
- Se il ramo d’origine è stato modificato dopo aver creato il ramo su cui ho apportato le mie modifiche, Git crea un nuovo commit (51trgh) in cui vengono inclusi 3 diversi commit
- Creazione nuovo commit che comprende =>
- l’ultimo commit attuale del ramo originale (nr7jk)
- l’ultimo commit del ramo con le mie modifiche (az84f)
- l’ultimo commit del ramo originale quando ho creato il ramo con le mie modifiche (a90hb)
- I due rami da mergiare si sono discostati
- Three-way:
-
-
- Git non è in grado di spostare il puntatore all’ultimo commit come in un commit veloce.
- Per portare il ramo feature1 nel ramo principale, Git esegue un’unione a tre vie.
- Git acquisisce uno snapshot di tre diversi commit per crearne uno nuovo
-
- Undoing in Git =>
- E’ possibile pensare a Git come ad una utility per la gestione della timeline.
- Un commit non è altro che un’istantanea del nostro progetto in un certo punto della timeline.
- E’ possibile inoltre gestire più timeline del nostro progetto tramite i branch e farle evolvere separatemente.
- Quando si “annulla” in Git, di solito si torna indietro nel tempo o si passa in un’altra timeline (nella quale ad esempio non si sono verificati errori).
- E’ possibile ripristinare il nostro progetto a partire da un precedente snapshot. Tramite il comando checkout/restore
- In questo caso il ramo corrente head punterà allora allo shapshot selezionato mentre il ramo master punterà ancora all’ultimo commit effettuato finora.
- Object_Id =>
- Un commit ha un codice hash univoco
- Quando si lavora con un commit è possibile riferirsi a esso tramite il suo object_id
Configurazione e preparazione di un repository GIT (config, clone, init)
- config command =>
- Durante l’installazione di GIT vengono richieste alcune configurazioni
- File di config => c:\users\richlab\git\.git\config\
- Visualizza e modifica settings
-
git config --list --show-origin
git config [--global] --edit
-
- Livelli di settaggio
- system (applica i settaggi a tutti gli utenti)
- global (applica i settaggi a tutti i repository dell’utente corrente)
- local (applica i settaggi al repository corrente)
- Name (per l’autenticazione)
-
git config --global user.name "My name"
git config --global --unset-all user.name [azzera l'impostazione]
-
- Email (per l’autenticazione)
-
git config --global user.email myemail@example.com
-
- Default editor:
-
git config --global core.editor <editor_path>
git config --global -e [apro nell'editor appena impostato il file di config]
-
- Line ending (gestisce l’eventuale differenza di gestione del carattere ‘a capo’ tra il sistema operativo degli utenti di git quando interagiscono sullo stesso repository):
-
git config --global core.autocrlf true [windows os]
git config --global core.autocrlf input [linux/macintosh osx after 2015]
-
- Difference tool (setta il programma di default per fare il difference tra 2 file)
-
git config --global diff.tool winmerge
git config --global difftool.winmerge.cmd "/c/Program\\ Files\\ \\(x86\\)/WinMerge/WinMergeU.exe"
-
- Merge tool (setta il programma di default per far il merge tra 2 file)
-
git config --global merge.tool winmerge
git config --global mergetool.winmerge.cmd "\"C:\Program Files (x86)\WinMerge\WinMergeU.exe\"
-e -u -dl \"Base\" -dr \"Mine\" \"$LOCAL\" \"$REMOTE\" \"$MERGED\""
git config --global mergetool.keepBackup false [or true] [false=dico al programma che mi aiuta a fare il merge
di non salvare file di back e inquinare così la mia
cartella di lavoro]
-
- Aliases (è possibile settare degli alias per richiamare più velocemente i comandi desiderati)
-
git config --global alias.<alias_name> "<alias_command>" [es: <alias_name>=ls, <alias_command>="log --pretty=format:'%an committed %H"]
git config --global alias.unstage "restore --staged ." [creo un alias per fare l'unstaging di tutti i file che ho in staging area]
git <alias_name> [per richiamare il comando di cui abbiamo creato l'alias]
-
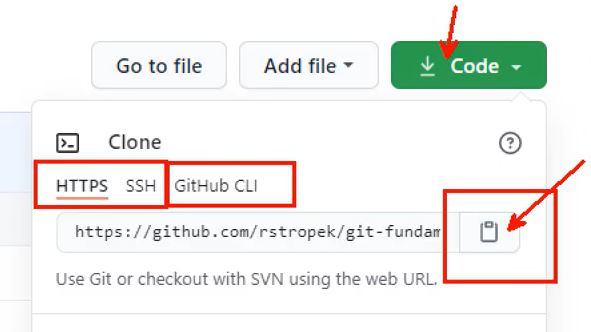
- clone command =>
- Crea una copia locale di un progetto che esiste in remoto. Include tutti i file di progetto, lo storico e i rami
-
git clone <remote_repo_url> [<nome_cartella_progetto>] [default=crea una cartella con lo stesso nome del repository
è possibile decidere un altro nome indicandolo espressamente]
]
<remote_repo_url> => https://github.com/<aUser>/<aRepo.git> [Https]
oppure
<remote_repo_url> => git://github.com/<aUser>/<aRepo.git> [GitHub CLI]
-
- Collegamento automatica del repository remote
- Normalmente il comando clone crea automaticamente l’alias ‘origin’ per riferirsi al repository remote senza dover lanciare esplicitamente il comando corrispondente (git remote add..)
- Collegamento automatica del repository remote
- init command =>
- Inizializza un nuovo repository git vuoto in locale. Può essere ovunque nel file system locale
-
//posizionarsi nella cartella dove si vuole aggiungere git
//è possibile eventualmente specificare un path differente da quello dove siamo con la shell
git init [<local_repository_path>] - Collegamento manuale del repository remote
- Per poter sincronizzare una cartella git locale con un repository remoto è necessario collegarla a tale repository manualmente (git remote add)
- git folder:
- Cartella di servizio => Il comando init aggiunge una subdirectory .git nascosta che ospita la struttura dati interna richiesta per il controllo della versione
- Non modificare => Non modificare questa cartella, è esclusivamente utilizzata dalla gestione interna di git
- Portabilità => Se si vuole spostare il proprio progetto, è sufficiente spostare con esso anche la cartella di servizio e tutto lo storico e le impostazioni finora settare in git rimarranno senza alcun problema
- Lo staging viene memorizzato nelle due strutture
.git/index(contiene i percorsi) e.git/objects(contiene le modifiche vere e proprie):
- .gitignore:
- Per evitare di fare il tracking di alcune cartelle/file non necessari è possibile aggiungere alla root del nostro progetto il file .gitignore e aggiungere una voce per ogni occorrenza (file o cartella) che non si vuole far gestire a git (es: file di log).
- https://github.com/github/gitignore => in questa pagina si trovano dei template di file gitignore per differenti tipi di progetti diversi (as es: java, C++, delphi)
- push.default
- File di configuratione per l’operazione di push
Salvare modfifiche (add, commit, diff, stash)
- add command (staging) =>
- Cosa fa:
- Mette in stage le modifiche effettuate nella working area (creazioni di nuovi file, modifiche e eleminazioni di file).
- GIT tiene traccia delle modifiche fatte da uno sviluppatore ma è necessario farne lo stage e un snapshot affinché tali modifiche vengano incluse nello storico del progetto.
- Inizia 2-step process:
- Add (staging) é la prima parte di un processo a 2-step (staging + committing)
- Offre in primis la possibilità di customizzare più facilmente ciò che sarà committato quando si deciderà di interrompere lo sviluppo
- Offre inoltre la possibilità interagire con il controllo di versone.
- Preparare snapshot:
- Ogni modifica che è stata messa in stage diventerà parte nel nuovo shapshot e dello storico del progetto.
-
git add <file_path> [i file eliminati in locale vengono tolti dall'area di staging]
git add <file_path1>..<file_pathN> [è possibile fare lo stage di più file alla volta
git add <folder_path> [mette in stage tutti i file della cartella specificata]
git add . [mette in stage tutt i file della la cartella corrente]
git add -u [sincronizza solo i file che erano già stati aggiunti alla staging area
e successivamente sono stati modificati o eliminati]
- Cosa fa:
- commit command (salvataggio shapshot)
- Cosa fa
- Registra le modifiche dalla area di staging al repository
- Completa 2-step process (change-tracking)
- Commit é la seconda e ultima parte di un processo a 2-step (staging + committing)
- Snapshot:
- Fare un commit è come prendere una foto, ogni cosa che è stata passata in stage diventerà parte di questo snapshot con il comando commit
- Best practice
- Fare commit 5/10 volte al giorno sul file che si sta modificando):
-
git commit -m "commenta qui" [-m => aggiunge un messaggio di una riga]
git commit -am [= git add -u + git commit]
[committa direttamente (non passando dallo staging) tutte le nuove
modifiche a file che erano già stati aggiunti alla staging area]
git commit [apre l'editor predefinito per digitare un messaggio e un dettaglio]
- Cosa fa
- diff commnad =>
-
git diff [visualizzo le modifiche non ancora messe in stage (M rossa, ?? rosso)]
git diff --staged or --cached [visualizzo modifiche che sono già state messe in stage (M verde, A verde)
git difftool | git difftool --staged [visualizza le modifiche nell'editor di difference di default, es: winmerge]
//Tra 2 commit (il più giovane a sx)
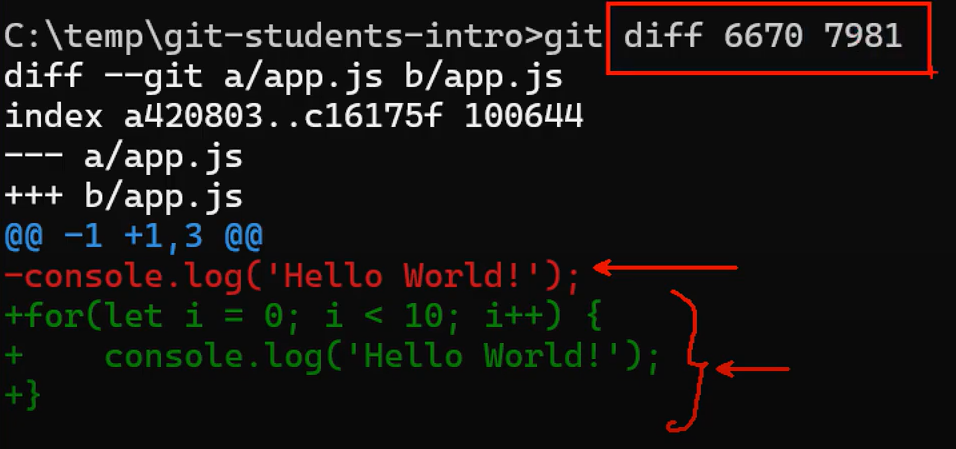
git diff HEAD~2 HEAD [--name-only or --name-status] [mostra le differenze tra i 2 commit specifiti]
git diff HEAD~2 HEAD <file_name> [mostra le differenze tra i 2 commit e il file specificati] - Nell’esempio sotto venongo mostrare le linee aggiunte (in verde) e eliminate (in rosso) nel commit 7981 rispetto al commit 6670
-
- stash command =>
- Archiviare temporaneamente le modifiche (file unstaged e staged) su cui si sta lavorando in modo da poter lavorare su qualcos’altro,
- Il file di cui ho fatto lo stash è sostiuito in locale con l’ultima versione stabile dello stesso temporaneamente
- Dopodiché posso tornare indietro e applicarle nuovamente in seguito.
- Ad esempio se è necessario lavorare su qualcos’altro ma si è a metà di una modifica del codice e non si è ancora pronti per eseguirne il commit).
-
//creazione nuovo stash
git stash push [-a] -m "metto in attesa modifiche" [nascondo momentaneamente le modifiche che stavo apportando.
-a=di default git non applica il comando stash ai
file untracked => usare l'opzione -a)]
//visualizzazione stash
git stash list [visualizzo gli stash presenti nel ramo corrente]
git stash show <#stash_sequence_number> [visualizzo le modifiche presenti un particolare stash]
//Ripristino stash
git stash apply <#stash_sequence_number> [ripristino le modifiche messe in stash senza eliminarle]
git stash pop <#stash_sequence_number> [ripristino le modifiche che avevo messo in stash e
eliminandole anche dallo stash stesso
//Elimino stash
git stash drop <#stash_sequence_number> [elimina lo stash indicato]
git stash clear [elimino tutti gli stash]
Annullare modifiche (checkout, restore, clean, revert, reset, rm)
- checkout command (rivedere un commit nello storico)
- Checkout => Switch + Restore.
- Dalla version 2.3 è deprecato e sostituito dai due comandi).
- Detached HEAD =>
- Il checkout permette di riportare lo stato attuale della working directory a come era in una versione precedente (dall’area di staging o dello storico del repository).
- Conseguentemente il puntatore HEAD sarà ‘detached’. Non punterà più a nessun ramo ma direttamente al commit selezionato.
- Si ottiene tale comportamento del comando checkout quando non si lavora esplicitamente su un file specifico.
- Commit orfani =>
- In uno stato distaccato, tutti i nuovi commit che eventualmente vengono eseguiti saranno ‘orfani’ (legati a nessun ramo)
- Tali commit verranno persi una volta che si ritornerà al ramo in cui si stava lavorando.
- I ‘commit orfani’ saranno distrutti definitivamente dal GC (garbage collector) di Git.
-
-
git checkout <commit_da_ripristinare_id> [<file_name>] [permette di far puntare il ramo HEAD a un
commit precedente. E' possibile indicare un file specifico]
git checkout main [E' il comando che riporta la working directory
allo stato 'corrente' del progetto facendo ripuntare
l'HEAD al ramo <main> oppure al ramo su cui si stava lavorando]
git checkout HEAD~<#_step_back> [#_step_back=1, ripristina il penultimo commit] - Use cases =>
- Ispezionare un vecchio commit (non un singolo file)
- Lanciare git log e recuperare il <commit_id> che si vuole ispezionare.
- Riportare la working directory nello stesso stato in cui era nel <commmit_id>
-
git checkout <commit_id>
-
- E’ possibile iniziare a ispezionare il codice, eseguire dei test, ecc..
- Essendo in stato ‘detached’ nessun eventuale commit verrà salvato nel ramo corrente.
- Continuare terminando l’ispezione =>
- Se si viuole ritornare a sviluppare è sufficiente tornare allo stato ‘corrente’ del progetto
-
git checkout main [main o il ramo su cui si stava lavorando]
-
- Se si viuole ritornare a sviluppare è sufficiente tornare allo stato ‘corrente’ del progetto
- Continuare ripristinando il vecchio commit =>
- Se invece si vuole salvare ciò che si è ispezionato prima di farne il commit è necessario assicurarsi di ritrovarsi su un ramo (si evitano i commit orfani)
-
git checkout -b <new_branch_without_crazy_commit>
-
- Tale comando creerà un nuovo ramo <new_branch_without_crazy_commit> e passerà a quello stato.
- In tal modo il repository è ora su una nuova timeline in cui il <commit_id> non esiste più.
- ATTENZIONE => Usare revert o reset
- Sfortunatamente, se abbiamo bisogno del ramo precedente su cui stavamo lavorando, tale strategia è inappropria.
- E’ necessario usare i comandi revert o reset per evitare di sovrascrivere sovrascriverlo
- Se invece si vuole salvare ciò che si è ispezionato prima di farne il commit è necessario assicurarsi di ritrovarsi su un ramo (si evitano i commit orfani)
- Ripristinare una vecchia versione di un singolo file
- Se il comando checkout lavora su un singolo file specifico il puntatore HEAD non viene spostato, evidanto di entrare nello stato ‘detached HEAD’.
- Perciò è possibile utilizzare questo comando come un modo per tornare a una vecchia versione di un singolo file.
- Dopodiché è sufficiente eseguire il commit del file ripristinato in una nuova istantanea come si farebbe con qualsiasi altra modifica
- Ispezionare un vecchio commit (non un singolo file)
-
- revert command (annullare le modifiche condivise)
- Annullare commit
- Il comando crea un nuovo commit con le modifiche necessario per invalidare quelle fatte nel/nei commit che voglio annullare
- A differenza del comando checkout, con revert è possibile continuare a utilizzare lo stesso ramo. Questa soluzione è perciò più soddisfacente.
- Adatto per commit già condivisi
- E’ il metodo di ‘undo’ ideale per lavorare con repository condivisi pubblici.
- Cattivo effetto sullo cronologia dello storico
- Se però si hanno requisiti per mantenere una cronologia Git curata e minima, questa strategia potrebbe non essere la più adeguata.
- Esempio:
-
//Si vuole annullare il commit <872fa7e>
git revert HEAD [oppure <872fa7e>]
//Tale comando crea un nuovo commit <e2f9a78> con le opportune modifiche per annullare quelle
//apportare nel commit che di cui si è voluto fare l'undo
-
- Annullare commit
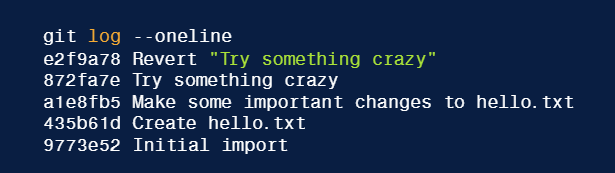
-
-
git revert [default --e] [--no-edit] -m 1 HEAD [annullo l'ultimo commit in cui ho fatto il merge.
1 significa che vado indietro di 1 commit]
git revert HEAD~3..HEAD [faccio il revert degli ultimi 3 commit. Il commit HEAD~3 non è incluso]
git revert --no-commit HEAD~3..HEAD [rimetto in stage i 3 nuovi commit. --no-commit=non crea il commit ma mette le
modifiche che inversano i commit precedenti in staging e nella directory locale
git revert --continue [confermo che accetto le modifiche presenti in stage.
--abort=non accetto le modifiche e annullo l'operazione
-
- reset command (annullare le modifiche private locali) =>
- E’ un comando completo con molteplici usi e funzioni
- Annullamento delle modifiche non committate =>
- Recap =>
- soft (repo locale) => annulla commit
- mixed (repo locale + area di staging => annulla commit + stage
- hard: (repo locale + area di stage + directory locale) => annulla commit + stage + elimina file nella directory locale
- Undo staging (unstaging)
-
//sposta tutte le modifiche pending dall'are di staging nella directory di lavoro
git reset [--mixed] [HEAD] <file-name> [ripristina il file dall'ambiente successivo]
git rm --cached <dir_or_file_path> [elimina il file in staging]
//Per file già conosciuti da git
git restore --staged <file-name> [faccio l'unstaging delle modifiche fatte su un file già committato
(in passato stato=modified)
-
- Recap =>
- Annullare commit =>
- Adatto per commit non condivisi
- Non è il metodo di ‘undo’ ideale per lavorare con repository condivisi pubblici. E’ utile per modifiche in locale non ancora condivise
- Buon effetto sulla cronologia dello storico
- Fare l’undo tramite il comando reset porterà ad avere una cronologia dello storico pulita
- Esempio:
- Adatto per commit non condivisi
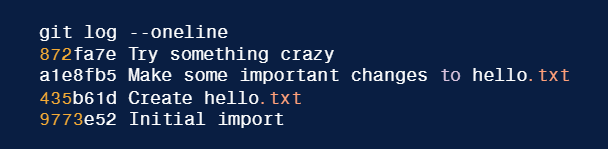
-
-
-
-
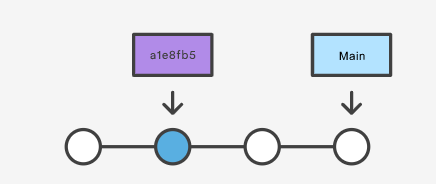
git reset --hard a1e8fb5
//Partendo dall'esempio dell'immagine sopra, tale comando ha per effetto
//di cancellare dalla cronologia il commit 872fa7e
-
-
-
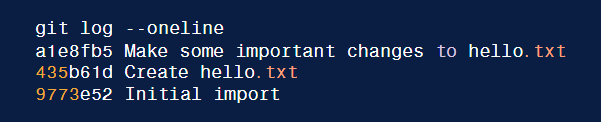
- restore command (da una versione precedente) =>
- Il checkout permette di riportare lo stato attuale della propria working directory a come era in un punto precedente:
-
git restore <file> [undo modifiche fatte in locale sui file specificati.
Copia file da area di staging in locale (undo local)]
//Per file già conosciuti da Git
git restore --staged <file-name> [unstaging delle modifiche fatte su un file già committato
(in passato stato=modified)]
git restore --source=HEAD~<#_step_back> <file_name> [posso ripristinare un file da un particolare
ambiente e specificando un particolare momento di riprisitno]
- clean command (undo local) =>
- Elimina untracked files
- E’ complementare ai comandi checkout e reset che loro invece lavora su file che git conosce (aggiunti almeno una volta all’area di stage
- Attenzione le modifiche vanno perse per sempre
-
//l'opzione -f è obbligatoria (Git la richiede per motivi di sicurezza)
git clean -n [simula cosa accadrebbe se al posto di -n ci fosse -f]
git clean -fd [<file_name>] [rimuove tutti i file untracked nella cartella locale (undo local)
se viene specificato un file, sarà eliminato quello]
git clean -i [mostra un prompt per scegliere tra diverse opzioni di cleaning]
- mv command => muovere o rinominare un file/directory/symlink
-
git mv -f <source> <destination> [rinomina il file in locale]
git mv <source> <destination> [rinomina il file in locale + area di staging]
-
- rm command => rimuovere un file/directory
-
git rm --cached <dir_or_file_path> [elimina il file in staging (unstaging)]
git rm -r <dir_or_file_path> [elimina il file in locale + staging.
-r (ricorsivo) elimina tutti i file della directory]
-
Ispezionare un repository (status, log, show, tag, blame, shorlog, bisect, describe)
- status command (visualizzazione stato modifiche) =>
- Mostra i file che hanno delle differenze (creati, modificati o eliminati) tra la working directory, la staging area e il repository
- Ti consente di vedere quali modifiche sono state messe in stage quali no e quali file non vengono ancora tracciati da Git.
- Mostra lo stato delle modifiche come
- colonna SX => repository locale
- collonna DX => staging area
- M rossa => file modificato in locale (ma non ancora nell’area di stage)
- M verde => file modificato in locale + area di stage
- M rossa + M verde => ci sono modifiche apportare al file in locale e anche in staging + modifiche apportate solo in locale
- ?? rossa => file aggiunto in locale (untracked)
- A verde => file aggiunto in locale + area di staging
- D verde => file eliminato in locale + area di staging
-
git status
git status -s (version short, più leggibile
- log command (visualizza la lista dei commit eseguiti)=>
- Il comando git log mostra gli snapshot salvati.
- Consente di elencare la cronologia del progetto, filtrarla e cercare modifiche specifiche.
- Visualizzare commit =>
-
// Tramite il comando log visualizzo delle informazioni sui commit eseguiti:
// - ramo da -> ramo a
// - id del commit (commit hash, object_id)
// - autore
// - date/time
// - messaggio
git log [space=vai alla pagina successiva, Q=exit]
git log --oneline [--all] [--graph] [mostra una versione ridotta del comando log.
--all permette di vedere tutti i commit presenti nel ramo master
in caso sia stato fatto un restore e gli altri rami
--graph rappresenta graficamente eventuali divergenze tra i diversi rami]
git log --stat [mostra la lista dei file modificati]
git log --patch [mostra le modifiche correnti, patchs]
git log --reverse [mostra i commit al contrario, dal più vecchio al più giovane]
git log --branches=* [è possibile vedere i log di tutti i rami]
-
- Customizzare output dello storico (lista placeholders: https://git-scm.com/docs/git-log ) =>
-
git log --pretty=format:"%Cgreen%an%Creset committed %H on %cd" [posso customizarre la visualizzazione dei log,
%Cgreen=text color verde, %an=autore, %H=commit_hast,
%h=short_commit_hast, %cd=date]
-
- Filtrare storico =>
-
git log -3 [mostra le ultime 3 entries]
git log --author="Mosh"
git log --before or --after ="2020-08-17" [after=yesterday, after=one week ago]
git log -- <file_name> [visualizzo i commit per il dato file]
git log --grep=“GUI” [visualizzo i commit con 'GUI' nel loro messaggio]
git log -S"<string_to_search>" [visualizzo tutti i commit che hanno aggiunto o modificato la stringa spec.]
git log --online <commit_id_from>..<commit_id_to> [visualizzo tutti i commit nel range specificato]
git log --online [--patch] [--stat] <file_name> [visualizzo tutti i commit legati al file specificato.
Se git dice che il file è ambiguo, bisogna aggiungere -- prima del nome del file]
-
- show command (show commit content) =>
- Mostra il contenuto del commit specifico
-
git show HEAD~<#_step_back> [mostra le differenze di un dato commit.
<#_step_back>=0 x l'ultimo commit. <#_step_back>=1 x il penultimo commit]
git show HEAD~<#_step_back>:<nome_file> [mostra la versione presente nell'ultimo commit per uno specifico file]
git ls-tree HEAD~<#_step_back> [mostra tutti i file presenti ad un dato commit, BLOB=file, TREE=cartelle
// - commits (visualizza 1 commit specifico recuperando l' object_id grazie al comando log)
// - blobs (files)
// - trees (cartelle)
// - tags
git show <object_id> [visualizzo il contenuto di un oggetto dal suo ID univoco nel repository]
git show HEAD~2 --name-only [visualizza solo il nome dei file presenti nel terzultimo commit]
or --name-status [ne visualizza lo stato (A,M or D)
- tag command =>
- I tag sono riferimenti/bookmark che puntano a punti specifici (commit) nella cronologia di Git.
- Viene generalmente utilizzato richiamare un punto nello storico contrassegnato con una certa versione
- Per esempio per marcare uno ‘sprint’ agile.
-
git tag <nome-tab> [creo nuovo tag e lo associa all'ultimo commit]
git tag [-n] [-d] [visualizzo tutti i tag creati ad ora.
-n=visualizzo i messaggi di tutti i commit legati al tag o la descrizione del tag
se non ci sono ancora commit associati.
-d=elimino il tag]
git tag [-a] <nome_tag> [-m "desc. tag"] [<commit_id>] [associo l'ultimo commit (o il commit specificato) al tag.
-a e -m servono per aggiungere una descrizione al tag che sto creando]
git checkout <nome_tag> [una volta associato un commit a un tag, possiamo usare questo tag
per riferirci al commit]
-
- I tag creati in locale non sono subito visibili nel repository fork, bisogna esplicitamente farne il push:
-
git push origin <nome_tag_creato_in_locale> [allinea il repository fork con i tag creati in locale.
Crea automaticamente uno snapshot dei file del progetto al momento
in cui il tag è stato importato nel fork]
git push origin --delete <nome_tag_creato_in_locale> [elimina nel repository fork il tag specificato]
-
- I tag creati in locale non sono subito visibili nel repository fork, bisogna esplicitamente farne il push:
- blame command =>
- La sua principale funzione è la visualizzazione dei metadati dell’autore legato a specifiche righe committate in un file.
- Opera necessariamente su un unico file
- Viene utilizzato per esaminare punti specifici della cronologia di un file e ottenere =>
- chi fosse autore che ha modificato una data riga.
- oppure rispondere a domande su cosa, come e perché il codice è stato aggiunto a un repository.
-
git blame [-e] [-w] [-L 1,3] <file_name> [-L=posso limitare la visualizzazione a un range di linee
-e=mostra la email invede dello username dell'autore
-w=ignora le modifiche legate solo a spazi bianchi]
Per ogni linea del file specificato vedo
- commit_id
- autore
- timestamp (data di modifica)
- numero della line
- shortlog command (storico degli autori) =>
-
git shortlog -n -s -e [<nome_file>] [visualizzo gli autori delle modifiche.
E' possibile usare gli stessi filtri del comando log]
-
- bisect command =>
- Se uno degli ultimi commit ha introdotto un bug nel progetto allora devo trovare quale snapshot ripristinare per togliere il bug.
- Marco lo snapshot attuale come bad e ne trovo uno precedente che posso indicare come good. Il ramo master punterà allo snapshot bad e il ramo head si posizionerà a metà tra lo snapshot bad e good.
- A questo punto testo l’applicazione e se il bug persiste significa che è in uno degli snapshot precedenti a quello attualmente legato al ramo head.
- All’opposto se l’applicazione non ha il bug significa che questo sarà in uno degli snapshot successivi.
- Il comando bisect implementa l’algoritmo ‘divide et impera’.
-
git bisect start [lancio la modalità bisect]
git bisect good [<commit_id>] [marco come good lo snapshot legato al ramo HEAD o quello indicato.
A questo punto il ramo HEAD si sposta nella metà successiva degli
snapshot se ho già indicato un ramo bad]
git bisect bad [<commit_id>] [marco come bad lo snapshot legato al ramo HEAD o quello indicato.
A questo punto il ramo HEAD si sposta nella metà precedente degli
snapshot se ho già indicato un ramo good]
git bisect reset [<commit_id>] [attacco il ramo master al ramo attuale o a quello indicato]
- describe command =>
-
git describe [<object_id>] [Se non indico nessun <object_id>, il punto di partenza del describe
sarà l'attuale HEAD]
Il risultato del commando è la seguente stringa:
<tag>_<numCommitTag>_g<hash>
- <tag>: è il tag più vicino risalendo lo storico dei commit partendo da HEAD o da <object_id>
- <numCommitTag>: è il numero di commit con quel tag
- g<hash> : è l'<object_id> del commit descritto
-
- Use cases =>
- Trovare cartelle git in locale
-
Get-ChildItem . -Recurse -Hidden .git [windows powershell]
-
- File presenti nella staging area
-
git ls-files
-
- Trovare cartelle git in locale
Riscrivere lo storico (rebase, cherry-picking, commit –amend)
- Rebase command
- Cosa fa =>
- Obiettivo del rewriting è rendere lo storico più leggibile e significativo
- Attenzione: la regola d’oro è mai riscrivere un repository pubblico .
- Può invece essere importante riordinare e rendere leggibile e significativo il repository locale prima di condividerlo con gli altri
- Da usare solo in locale prima di aver fatto il push nell’upstream.
- Rebase iterativo =>
- Con l’opzione .[-i] git apre un’interfaccia grafica che mi aiuta nelle selezione di quali commit faranno parte del rebase tra tutti quelli raggiunti dal puntatore utilizzato nel comando
- Tramite l’interfaccia grafica aperta da Git posso decidere come comportarmi con ogni singolo commit facente parte del mio rebase usando le seguenti parole chiave =>
- Edit
- Consente di modificare il commit durante l’operazione di rebase.
- Drop
- Voglio eliminare il commit.
- Pick
- Semplicemente voglio mantenere integralmente il commit.
- Reword
- Come <Pick> ma posso modificare il messaggio del commit.
- Squash
- Consente di combinare due o più commit in un unico commit.
- Un commit viene compresso nel commit sopra di esso. Git ti dà la possibilità di scrivere un nuovo messaggio di commit che descrive entrambe le modifiche
- Fixup
- Come <Squash> ma utilizza solo il messaggio del primo commit del gruppo di commit di cui abbiamo fatto lo squash
- Edit
- Rebase con squash (unire commit piccoli e riguardanti lo stesso argomento) =>
-
//Unire commit piccoli e riguardanti lo stesso argomento
git rebase -i <commit_da_riordinare>^ [^=puntatore al commit padre scelgo l'opzione squash o fixup del comando rebase
per unire i dato commit con il precedente e concludere il rebasing]
-
- Rebase con split (dividere commit troppo grandi) =>
-
//dividere commit troppo grandi
git rebase -i <commit_da_riordinare>^ [^=puntatore al commit padre scelgo l'opzione edit del comando rebase
sul commit che voglio splittare e interrompere il rebasing]
git reset [--mixed] HEAD^ [successivamente fare l'unstaging dell'ultima operazione, dove avrò le modifiche fatte
nel commit di cui ho fatto l'edit con il comando reset. Ora sono libero di committarle
in 2 o 3 commit separatamente. Concludere l'operazione di rebasing
-
- Rebase con sort (riordinare i commit) =>
-
git rebase -i <commit_da_riordinare>^ [^=puntatore al commit padre spostare i commit come desiderato e concludere il rebasing]
-
- Modificare messaggi legati ai commit =>
-
git rebase -i <commit_da_modificare>^ [^=puntatore al commit padre scegliere poi l'opzione reword del comando rebase e concludere il rebasing]
-
- Esempio di rebase puntuale:
-
//il comando fa passare la situaizone dall'immagine a sx all'immagine a dx
//il ramo <bugFix> prima puntava a C1 ora la sua base è stata modificata e punta C2
//l'operazione crea un nuovo commit c3* che contiene le modifiche del commit C2 del ramo <main>
git rebase <main>
-
- Cosa fa =>
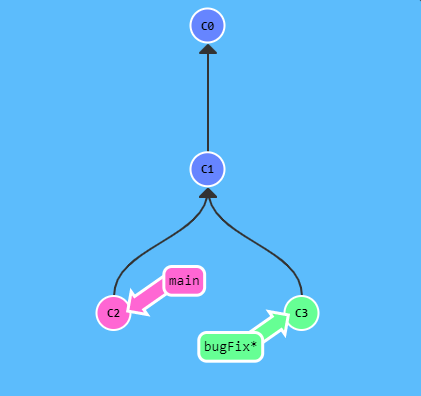
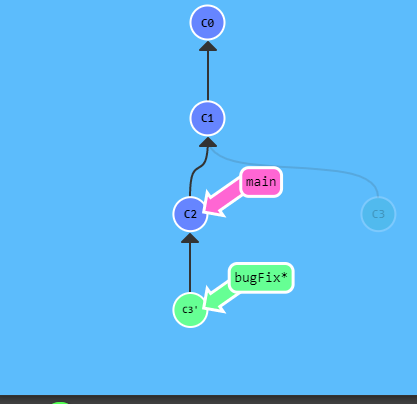
-
- Esempio di rebase iterativo:
- Con l’opzione .[-i] git apre un’interfaccia grafica che mi aiuta nelle selezione di quali commit faranno parte del rebase tra tutti quelli raggiunti dal puntatore utilizzato nel comando
-
//il comando fa passare dalla situazione nell'immagine a SX a quella a DX
//nell'interfaccia aperta da git dopo il lancio del comando ho selezionato di tenere (skip) i commit C3 e C5
//mentre per i commit C2 e C4 non li ho presi in considerazione per il rebase
git rebase -i HEAD~4
- Esempio di rebase iterativo:
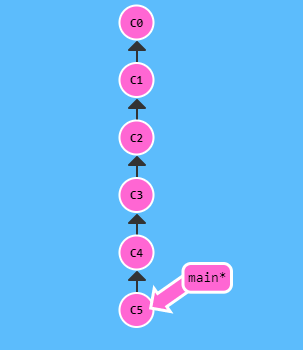
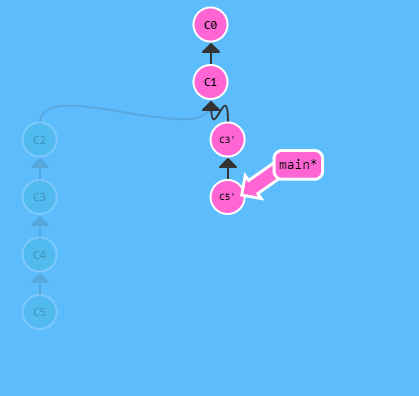
-
- Use cases =>
- Rimetto “in linea” due rami non in conflitto tra loro
- Nel caso un ramo si sia discostato dal master e siamo sicuri che sono state fatte modifiche non in conflitto tra loro è allora possibile rimetterlo “in linea”.
- Fare il rebase del ramo in questione significa farlo puntare all’ultimo commit del ramo master e non al commit in cui era stato creato che era la sua base in precedenza
- Dopodiché fare un normale fast-forward merge,
-
//passo1
git rebase master [da lanciare nel ramo target. Riposiziona il ramo
target all'ultimo commit nel ramo master]
//passo2
git switch master
//passo3
git merge <ramo_target> [lancio il fast-forward merge]
oppure
git rebase <ramo_targer>
- Rimetto “in linea” due rami non in conflitto tra loro
- Use cases =>
- cherry-picking command =>
- Spostare un particolare commit da un ramo a un altro senza fare per forza il merge che invece tratterebbe tutti i commit del ramo da mergiare.
- Nel caso di conflitti li risolvo e poi continuo con l’operazione di cherry-picking
-
git cherry-pick <commit_id> [applica il dato commmit al ramo attuale]
git cherry-pick <commit_id1> <commit_id2> [è possibile fare il cherry picking di più
commit contemporaneamente]
git commit -m "ho fatto il cherry-pick" - merge di un file (è possibile portare le modifiche fatte su un particolare file in un ramo ad un altro) =>
-
git restore --source=ramo_da_cui_prendere_il_file <nome_file>
git add <nome_file>
git commit -m "ho recuperato un file da ramo desiderato"
-
- esempio =>
-
//applicando questo comando alla situazione illustrata dalla prima immagine
//si arriva alla situazione illustrata dalla seconda immagine
git cherry-pick C3 C4 C7
-
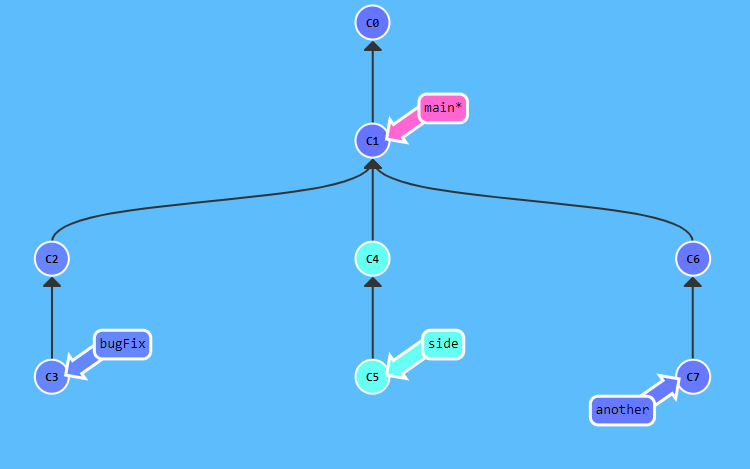
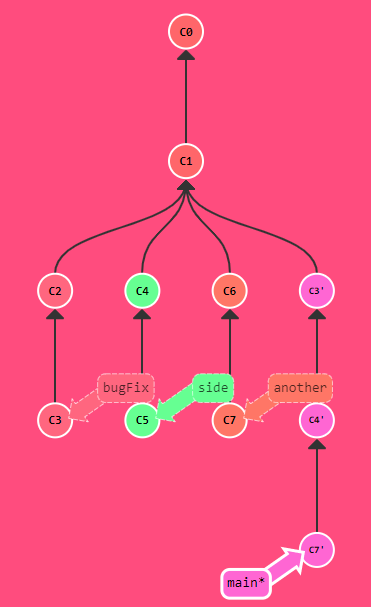
- Use cases =>
- Modificare l’ultimo commit (ad es: aggiungere un file dimenticato)
-
//Se ci si accorge che abbiamo sbagliato qualcosa nell'ultimo commit
//allora è sufficiente fare le modifiche necessarie, mettere il stage e lanciare il seguente comando
//Git modificherà il commit aggiungendo le nostre nuove modifiche
git commit --amend -m "nuovo messaggio" [modifica l'ultimo commit aggiungendogli le modifiche presenti in stage]
oppure
git reset --mixed HEAD [un altro modo è unstaging l'ultimo commit, fare le modifiche desiderate e ricommittare]
git commit -m "nuovo messaggio"
-
- Modificare l’ultimo commit (ad es: aggiungere un file dimenticato)
-
- Modificare un vecchio commit
- Ad es: aggiungere un file dimenticato => tutte le modifiche che apporterò a questo vecchio commit saranno aggiunte a ognuno dei commit che lo seguono:
-
git rebase -i <precdente_commit_id> [faccio rebase al commit che precede quello che si vuole modificare. -i=interativo.
Cambio l'opzione pick on edit per i commit che voglio modificare.
Verrà creato un nuovo commit per ogni commit presente
nel range di rebase anche quelli non modificati]
git commit --amend [Per ogni commit che voglio modificare, faccio le modifiche in staging
e poi il commit con opzione amend]
git rebase --continue [or --abort] [concludo l'operazione di rebase o la annullo]
- Modificare un vecchio commit
-
- Recuperare commit perduti =>
-
git reflog [show HEAD] [visualizzo lo storico del puntatore specificato (HEAD per default)
e trovo il commit che mi serve per il ripristino]
git reset --hard HEAD@{1} [il ripristino indicando il commit desiderato]
-
- Recuperare commit perduti =>
Collaborazione (fetch, push, pull, merge, remote)
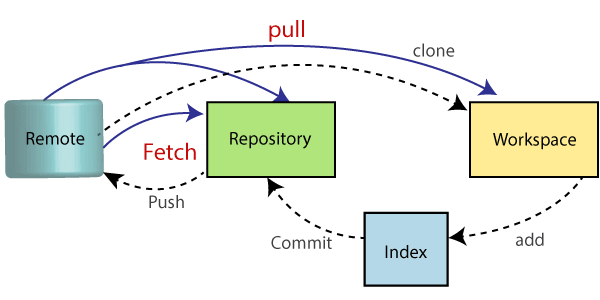
- fetch command (legge le modifiche presenti sui repository remoti) =>
-
- Cosa fa =>
- Contatta il repository remoto tramite Internet (usando il protocollo
http://oppuregit://) - Scarica i nuovi commit presenti in remoto (dall’ultima operazione di fetch eseguita)
- Dopodichè sincronizza nel repository locale i puntatori remoti (refs/remotes/<remote>/)
- Contatta il repository remoto tramite Internet (usando il protocollo
- Cosa non fa =>
- Non cambia niente nei rami locali
- Per avere le modifiche effettive in locale è necessario farne il merge
- Si comportamento similarmente a svn update in quanto consente di vedere come è progredita la cronologia remota senza obbligare a sincronizzare effettivamente il repository locale.
- Cosa fa =>
-
git fetch [opzionale <remote_repository>] [optional <branch>] [default <remote_repository>=origin, default <branch> = master/main]
git fetch -p [-p or --prune aggiornerà il database locale dei rami remoti
-
- push command =>
- Aggiorna il repository remoto con ogni nuovo commit fatto localmente per il ramo
- Visto che il repository remoto è cambiato a seguito del nostro push, in automatico nel repository locale venogno rieallineati i puntatori remoti (come nel comando fetch)
-
git push -u origin <branch_name> [origin = repository remoto, -u usare solo alla prima creazione del ramo in remoto]
- situazione di partenza foto a sx
- situazione dopo il comando push, foto a dx
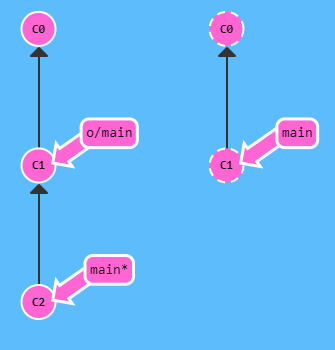
- pull command (fetch + merge) =>
- E’ una scorciatoia (syntax sugar) per i 2 comandi => fetch + merge
- Incorpora le modifiche da un repository remoto in locale.
- Generalmente si usa quando un compagno ha fatto dei commit su un ramo in remoto e si vuole vedere queste modifiche in locale.
- Modifica nel repository locale sia refs/remotes/<remote>/ che refs/heads/ :
-
$ git pull [opzionale --rebase]
-
- Esempio =>
-
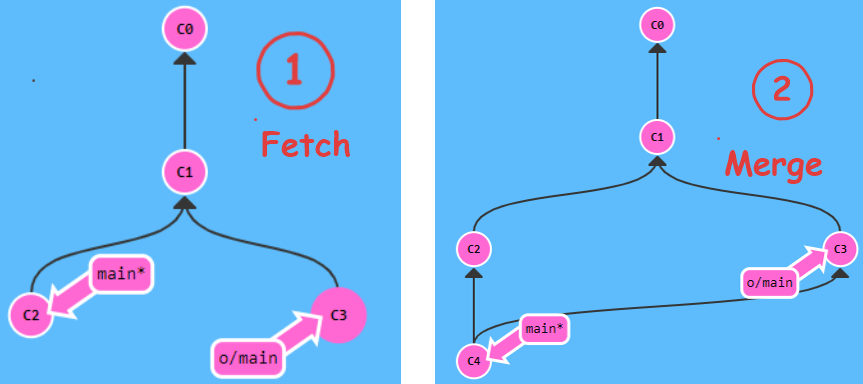
- Situazione di partenza =>
=> vedi prima immagine in basso
=> il repositoy remoto ha il nuovo commit C3 non presente in locale
//eseguo il comando
git pull (fetch + merge)
- Situazione finale in 2 step
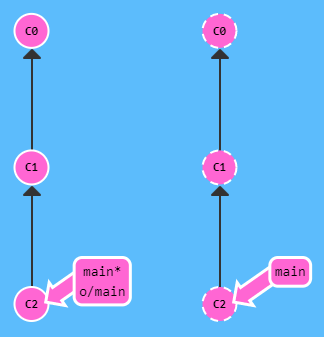
step 1 (foto 1) => fetch eseguito => il puntatore locale al ramo remoto riconosce la presenza del nuovo commit C3 e si allinea
step 2 (foto 2) => merge eseguito => viene creato il commmit C4 con il merge delle modifiche remote importate
=> viene spostato l'HEAD del ramo locale (main)
-
- Esempio =>

- merge command (fusione dei commit) =>
- Usato tipicamente per fondere modifiche fatte su due rami differenti
-
git merge <nome_ramo_con_modifiche_da_mergiare> [- spostarsi prima nel ramo target dove voglio essere
copiate le modifiche (es: <main>)
- questo comando implementa il merge di tipo fast-forward.
Viene semplicemente spostato il puntatore del ramo <main>
all'ultimo commit del ramo <nome_ramo_con_modifiche_da_mergiare>]
git merge --no-ff <nome_ramo_con_modifiche_da_mergiare> [forza il merging a non utilizzare la tecnica fast-forward perdendo
la linearità ma rispettando l'integralità dello storico dei commit]
git merge [--global] ff no [disabilità l'opzione fast-forward per il merge nel repository attuale
(o in tutti se si usa --global)]
git merge --abort [undo il comando merge nel caso ad esempio abbia dei conflitti e
non possa gestirli nell'immediato] - Gestioone conflitti =>
- Nel caso git non possa procedere in modo automatico con il merge ci chiederà tramite un prompt di risolvere il conflitto manualmente
- Nel prompt apparità il programma di gestione dei conflitti che abbiamo preventivamente configurato (vedi comando config)
- In questo momento possiamo decide di abortire il merge (se non siamo riusciti a risolverlo)
- In questo momento possiamo fare lo stage e il commit delle modifiche manuali cha abbiamo fatto e risolvere quindi il conflitto.
- merge con squash =>
- E’ possibile unire tra loro più commit su un ramo prima di mergiarlo con il ramo master
-
git merge --squash <nome_ramo_con_modifiche_da_mergiare>
git commit -m "prima di fare il merge ho fatto lo squash dei commit del ramo da mergiare"
[è possibile prima di fare il merge decidere di riunire tutti
i commit del ramo da mergiare in uno solo per rendere lo storico
più pulito]
git branch -D <nome_ramo_con_modifiche_da_mergiare> [visto che abbiamo fatto lo squash bisogna eliminare il ramo]
- Alternative al comando merge =>
- E’ possibile effeturare la fusione in locale di modifiche recuperate da rami remoti anche tramite altri comandi
- Vedi il comando cherry-picking
- Vedi il comando rebase
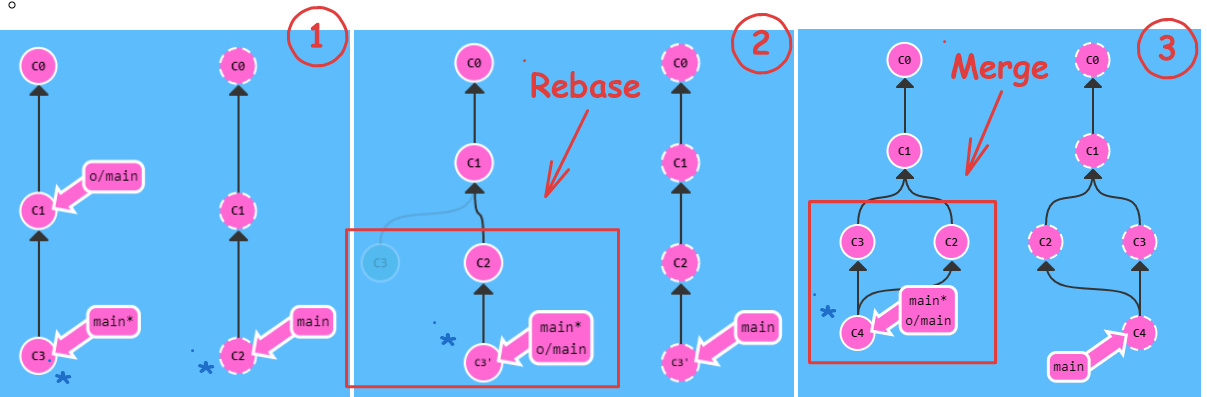
- Esempio rebase vs merge =>
- Nuovo commit C2 da importare in locale (1)
- la prima immagine visualizza il punto di partenza del ramo locale (sx) e del ramo remoto (dx)
- si vede in remoto è presente il commit C2 non ancora presente in locale
- Uso rebase (2)
-
git fetch;
git rebase o/main;
git push;
-
- Uso merge (3)
-
git fetch;
git merge o/main;
git push;
-
- Nuovo commit C2 da importare in locale (1)
- E’ possibile effeturare la fusione in locale di modifiche recuperate da rami remoti anche tramite altri comandi
{kind=link}
{kind=link}
- remote command
- Mi permette di interagire con i repository remote
-
//Visualizzazione repository remoti
git remote -v [-v: verbose] [lista dei repository remoti collegati
alla corrente directory locale]
git remote get-url <repo_name> [visualizza url dove il repository remoto risiede]
//Aggiungere, eliminare repository remoti
git remote add <repo_name> <url> [aggiungo una connessione a un repositoty remoto
- d'ora in poi sarà possibile riferirsi al repository remoto
tramite il <remote_name> scelto, senza la necessità di ricordarsi l'url
- esempio di url => git://github.com/<aUser>/<repo-name.git>]
git remote remove [or rm] <repo_name> [rimuovere un repository remoto]
git remote rename <repo_vecchio_nome> <repo_nuovo_rome> [posso eventualmente cambiare il nome che ho assegnato
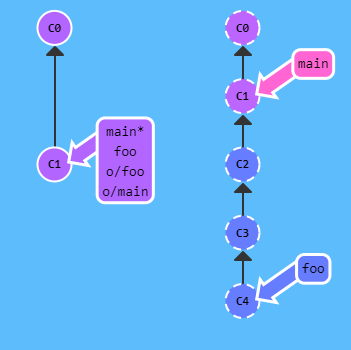
in locale ai repository remoti] - Esempio:
-
L'immagine sotto illustra =>
- un repository locale (a sx) con 2 rami locali e 2 rami remoti
- un repository remoto (a dx) con 2 rami
- il repository ramo 'foo' in remoto è 3 commit avanti rispetto all'ultimo fetch del ramo 'foo' in locale
- è necessario fare un nuovo fetch
-
- Mi permette di interagire con i repository remote
Lavorare con i rami (branch, siwtch)
- branch command =>
-
git branch [mostra i rami su cui si lavora in locale. Un * mostra il ramo attivo ora per l'utente]
git branch - a [mostra i rami in locale e in remoto]
git branch <new_branch_name> [crea un nuovo ramo]
git checkout -b <new_branch_name> [crea un nuovo ramo e fa passare il puntatore HEAD a tale ramo]
git branch -m <old_branch> <new_branch> [muovo/rinomino un ramo]
git branch -d <branch_name> [elimina il ramo se é già stato 'fully merged' nel suo ramo upstream]
git branch -D <branch_name> [elimina il ramo indipendentemente dal suo merged status (= --delete + --force)]
git branch --merged [--no-merged] [visualizza i rami che sono stati mergati nel ramo corrente]
git branch -f <name> HEAD~2 [forzo lo spostamento del ramo <name> di 2 commit indietro rispetto
a dove è adesso il puntatore HEAD]
-
- Creare un ramo da uno specifico commit
-
git log [visualizzo i commit e recupero l'<identifier> desiderato]
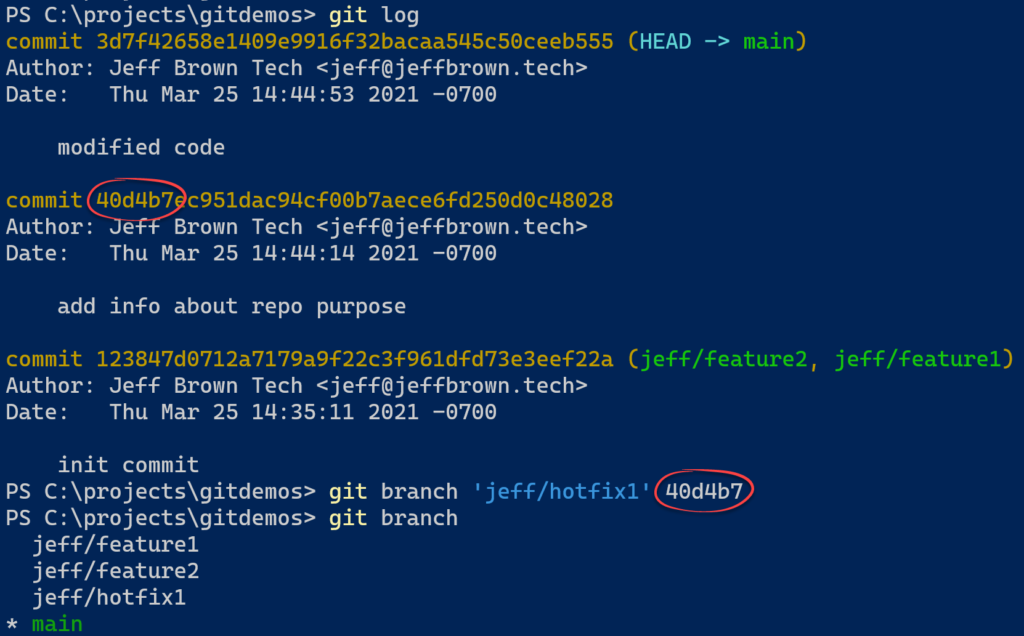
git branch '<nome-nuovo-ramo>' <identifier
-
- Confrontare rami =>
-
git log master..<ramo_da_confrontare> [visualizzo i commit nel secondo ramo non presenti in master]
git diff master..<ramo_da_confrontare> [visualizzo il sommario delle modifiche tra 2 rami]
git diff [--name-status] <ramo_da_confrontare> [posso indicare direttamente il ramo da confrontare]
-
- Tracking rami in remoto =>
- I nomi dei rami remoti devono obbligatoriamente seguire questo pattern =>
<nome del deposito distante>/<nome del ramo> - I rami che creo in locale per essere condivisi con gli altri contributor devo fare in modo che il sistema remoto li conosca e inizia a farne il tracking:
-
git branch -r [visualizzo tutti i rami 'tracked' in remoto (ad es: origin e upstream)]
git branch -vv [elenca tutti i rami sul sistema locale comprese le informazioni
sul rami remoti tracked (conosciuti in remoto)
git push -u <remoto_source_pointer> <branch_name> [aggiunge al repository remoto (ad es origin) il dato ramo.
-u è solo da usare la prima volta]
- I nomi dei rami remoti devono obbligatoriamente seguire questo pattern =>
-
- switch command => passa alla nodo indicato
-
git switch <branch> [fa passare il puntatore HEAD al ramo specificato]
git switch -c <new_branch> [crea un ramo e di fare lo switch nel puntatore HEAD direttamente]
-
- switch command => passa alla nodo indicato
Aggiungere un progetto esistente a Github tramite linee di comando (file sh)
-
#!/bin/sh
# ref: https://help.github.com/articles/adding-an-existing-project-to-github-using-the-command-line/
#
# Usage example: /bin/sh ./git_push.sh wing328 swagger-petstore-perl "minor update"
git_user_id=$1
git_repo_id=$2
release_note=$3
if [ "$git_user_id" = "" ]; then
git_user_id="GIT_USER_ID"
echo "[INFO] No command line input provided. Set \$git_user_id to $git_user_id"
fi
if [ "$git_repo_id" = "" ]; then
git_repo_id="GIT_REPO_ID"
echo "[INFO] No command line input provided. Set \$git_repo_id to $git_repo_id"
fi
if [ "$release_note" = "" ]; then
release_note="Minor update"
echo "[INFO] No command line input provided. Set \$release_note to $release_note"
fi
# Initialize the local directory as a Git repository
git init
# Adds the files in the local repository and stages them for commit.
git add .
# Commits the tracked changes and prepares them to be pushed to a remote repository.
git commit -m "$release_note"
# Sets the new remote
git_remote=`git remote`
if [ "$git_remote" = "" ]; then # git remote not defined
if [ "$GIT_TOKEN" = "" ]; then
echo "[INFO] \$GIT_TOKEN (environment variable) is not set. Using the git crediential in your environment."
git remote add origin https://github.com/${git_user_id}/${git_repo_id}.git
else
git remote add origin https://${git_user_id}:${GIT_TOKEN}@github.com/${git_user_id}/${git_repo_id}.git
fi
fi
git pull origin master
# Pushes (Forces) the changes in the local repository up to the remote repository
echo "Git pushing to https://github.com/${git_user_id}/${git_repo_id}.git"
git push origin master 2>&1 | grep -v 'To https'
Recap comandi Git
- Lista ufficiale dei comandi git: https://git-scm.com/docs
- Pdf con i comandi: Git Cheat Sheet
- Command Line Interface (CLI)
-
*most important
-- HELP
git --version
git --help -a (space-bare=continuare la lettura / q=abbandonare la visualizzazione)
git config --help (apre la pagina web ufficiale del manuale di git)
git config -h (visualizza nel prompt una versione short dell'help dei comand)
-- CREATE SNAPSHOT
-- stage
git add *.js | <file1> <file2> (stage file indicati)
git add . (stage tutti i file modificati in locale)
git add [-p] <file> (stage il file indicato, p= granularità per patch)
git add -u (stage solo dei file già conosciuti da git ma ora unstaged)
git reset (unstage tutti i file in stage)
-- commit
git commit -m "message" [-m "description"] (commit con messaggio su 1 linea)
git commit -am "message" (commit senza passare per lo stage)
git commit -p (p=patch, decido cosa committare modifica per modifica)
-- DELETE FILE
git clean -f (elimina i file untracked nella directory locale)
git clean -d (elimina le cartelle untracked nella directory locale)
git clean -x (elimina anche i file .gitignore)
git clean -n (simula l'eliminazione)
git rm <file> (elimina il file in locale)
git rm --cached <file> (untracking => elimina il file in area di staging, lo lascia in locale)
-- VIEW * git status [-s] git ls-files (file presenti nella staging area) -- differenze
git diff [<file>] (mostra modifiche non ancora in stage) git diff --cached | --staged [<file>] (mostra modifiche messe in stage)
git diff <branch> (mostra differenze tra ramo corrente e ramo specificato) git diff HEAD~2 HEAD [--name-only or --name-status] (mostra le diff tra i 2 commit)
git log master..<ramo_da_confrontare> (visualizzo i commit nel secondo ramo non presenti in master) -- singolo commit
git show 921aff (mostro il contenuto dell'oggetto dal suo ID univoco nel repo) git show HEAD (mostro l'ultimo commit)
-- collaboratore
git shortlog -n -s -e (visualizzo gli autori delle modifiche) git blame <file> (mostra gli autori di ogni linea del file)
-- storico
git log [--stat] (mmostra la lista dei file modificati) * git log [--all] [--oneline] [--graph] (mostra li lista dei file su una linea e graficamente.
--all mostra altri rami o taks) git log -3 (mostra le ultime 3 entries) git reflog [show HAED] (mostra lo storico di HEAD)
git reflog show bugfix (mostra lo storico del puntatore al ramo bugfix)
-- STASH git stash push -m "messaggio" (congela file unstaged + staged) git stash push -u (congela file unstaged + staged + untracked)
git stash push -a (congela file unstaged + staged + untracked + ignored) git stash list (visualizzo stash presenti)
git stash show <#stash_seq_num> (mostro lo stash indicato) git stash [pop] apply <#stash_seq_num> (ripristino le mod in stash senza eliminarle, pop=eliminandole)
git stash drop <#stash_seq_num> (elimino il dato stash)
-- BRANCH -- visualizzazione
git branch (vedo i rami in locale. * è quello corrente) [.git/refs/heads]
git branch -r (vedo rami remoto) [.git/refs/heads] [.git/refs/remotes]
git branch -a (vedo rami locale + remoto)
git branch -vv (vedo i rami e i rispettivi rami in remoto)
git branch --merged [--no-merged] (vedo i rami che sono stati mergati nel ramo corrente)
git branch -d | -D (elimino solo rami mergiati (-d). Elimino tutti i rami (-D))
git branch <branch_name> fe40594 (ripristino il commit indicato su un nuovo ramo)
git push origin --delete <branch> (elimino il ramo remoto <branch>) -- gestione
git branch <new-branch> (creo nuovo ramo)
git checkout -b <new-branch> (creo nuovo ramo + swiccio)
git switch -C <new-branch> (creo nuovo ramo + swiccio)
git checkout --track origin/<branch-to-copy> (creo in locale un new ramo identico a quello remoto <branch-to-copy>)
-- contronto con altri rami
git log <branch1..branch2> (lista dei commit in branch2 non presenti in branch1)
git diff <branch1> (contronto il ramo corrente con <branch1>)
git diff <branch1..branch2> (contronto i 2 rami indicati)
-- RESTORE git restore [-p] [<file>] (ripristino da stage => a locale, -p=granularità per patch)
git restore . (riprist. da stage => a locale tutti i file che stavo mod. in locale) git restore --staged [<file>] (unstaging del file specificato. Mantiene le modifiche in locale) git restore --source=HEAD~1 [<file>] (ripristino da snapshot indicato => a stage)
git checkout dad46rd (ripristino il dato commit)
git checkout master (ripristino il ramo master)
git revert 724747d (ripristina il dato commit)
git revert HEAD~3 (ripristina gli ultimi 3 commit)
git reset [--mixed] HEAD~ (annullo l'ulitmo commit + stage)
git reset --soft HEAD~ (annullo l'ulitmo commit, lascio le modifiche in stage)
git reset --hard HEAD~ (annullo l'ulitmo commit + stage + locale)
git commit --amend (modifico l'ulitmo commit)
git update-ref -d <branch-name> (questo comando fa l'undo dell'ultimo e unico commit)
-- MERGE
git merge <branch_with_changes> [--squash] (posizionarsi nel branch target, dopo il merge fare il commit
--squash=aggrega i commit da mergiare in 1 solo)
git merge --abort (undo l'ultimo merge, in caso di conflitti)
git rebase --abort (undo l'ultimo rebase, in caso di conflitti)
-- COLLABORATION git fetch origin master (recupero ramo master da origin)
git fetch [-p] [origin] (recupero tutti gli oggetti da origin, -p [--prune] aggiornerà
il db locale dei rami remoti)
git pull [--verbose] (fetch + merge)
git pull --rebase origin (questa opzione, invece di aggiungere in locale un nuovo commit
con le modifiche in remoto, fa il rebase delle modifiche
presenti in locale per intergrare le modifiche in remoto)
git push [origin master] (push master a origin)
git push -u [| -set-upstream] origin bugfix (push bugfix a origin, -u va usato solo la prima volta e
permette di collegare il ramo bugfix all'upstram in remoto)
git push -d origin bugfix (elimina bugfix da origin)
* git remote [-v] (lista dei repo remoti collegati alla corrente dir locale)
git remote show <remote_repo_url> (mostra info dettagliare sulla config. del ramo remoto spec)
git remote add origin <remote_repo_url> (collego il repo locale con il repo 'origin' in remoto)
-- USE CASES
-- SINCRONIZZARE LOCALE CON REMOTO git fetch --prune origin git reset --hard origin/master git clean -f -d
-- FARE IL PUSH NEL REPO REMOTO
git checkout main (aggiornare locale con remoto, prima di fare il push)
git fetch origin main
git rebase -i origin/main (!da usare per commit in locale, prima di farne il push in remoto)
git push origin main
-- REVERT L'ULTIMO PUSH IN REMOTO
git log --oneline --graph (decidere quale nodo ripristinare)
git rest --hard <commit_da_ripristinare>
[git clean -fd] (opzionale: elimino file e cartelle untracked in locale)
[git fetch] (opzionale: sincronizzo locale con remoto, per sicurezza)
git push <remote_branch> +<branch> (+: forzo il push da locale a remoto)
-
Risorse
- Git history (Visual Studio Code extension)
- GitHub actions (Visual Studio Code extension)
- Extension di Visual Studio Code utile per compilare il file di configurazione di GitHub Actions
- GitHub marketplace
- Learn git branching
- .gitignore codezombie (Visual Studio Code extension)
- Extension per creare il file .gitignore specifico per il proprio IDE o linguaggio di programazione
- .gitignore tempate (sito gitignore.io)
- Sito per recuperare il template del file .gitignore adattato all’environment che si desidera (es: VisualStudio)
- Sonarqube
- Permette di aggiungere dei controlli di qualità per verificare la bontà del nostro progetto
- Può essere usato installandolo localmente
- Può essere usato in Azure
- Può essere usato nelle ‘GitHub Action’ tramite la ‘sonarcloud-github-action’
- Connettere SonarCloud con il nostro forklow d’integrazione continua tramite ‘GitHub Actions’
- Sonarcloud
- E’ un servizio che permette di usare facilmente Sonarqube
- Free per progetti pubblici (usati per imparare)
- Direttamente dal sito Sonarcloud è possibile analizzare i nostri repository in Github (dopo essersi iscritti al sito)