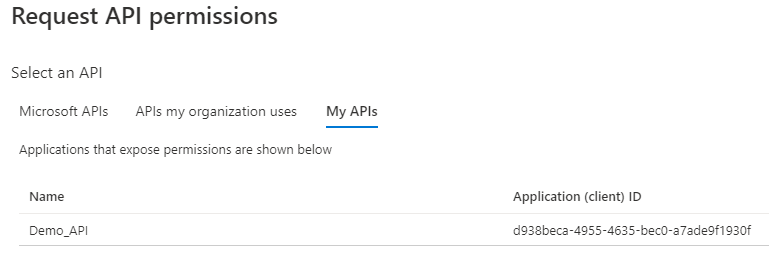
- Cloud Preview
- Github Actions
- Azure Preview
- Azure Portal
- Azure Compute Services (Virtual Machines, Cloud Services, App Services, AKS, Azure Functions)
- Azure Data Services (Azure Sql, DB on VM, Azure Storage, Cosmo DB, Redis Cache)
- Azure Fabric
- WebJob and background processing
- Azure DevOps
- Azure Networking (VNET)
- Azure Active Directory
Cloud Preview
- Cosa è il Cloud =>
- Cloud è utilizzare un servizio di computing, networking, storage ecc. gestito da qualcun altro
- Vantaggio principale del cloud =>
- Costo per il capitale (CapEx)
- L’approccio tradizionale del IT è orientato al pagamento del capitale (non ottimale e non flessibile)
- Costo per l’uso (OpEx)
- L’approccio del Cloud IT è piuttosto orientato al pagamento dei servizi realmente usati
- Costo per il capitale (CapEx)
- Principali caratteristiche di un servizio cloud =>
- On-Demand self service
- E’ possibile richiedere delle risorse in autonomia e secondo i miei bisogni semplicemente con un ‘click’.
- 24/7.
- Broad Network access
- E’ possibile accedere alle risorse da ovunque.
- Non è necessario nessun intervento fisico sulle apparecchiature.
- Resource pooling
- Le risorse fisiche sono condivise tra i differenti clienti del servizio.
- Non è possibile decidere esattamente quale apparecchiatura usare ma sarà la ‘cloud backbone’ a decidere .
- Servizi avanzati => Principalmente per motivi di sicurezza è possibile domandare apparecchiature dedicate.
- Rapid elasticity
- Le risorse possono essere aumentate o diminuite all’occorrenza in modo automatico.
- Servizi misurati
- Il pagamento è richiesto solo per le risorse realmente usate.
- Misure di pagamento
- Tempo del server in secondi
- DB Storage
- Numero di chiamate alle funzioni
- On-Demand self service
- Tipi di cloud =>
- Public (Il cloud è normalmente accessibile su Internet)
- Azure
- AWS
- GoogleCloud
- Private (Il cloud è installato nella Intranet aziendale)
- VMWare Cloud
- Azure Stack
- Red Hat OpenShift
- Hybrid (Il cloud è installato nella Intranet aziendale ma contiene una parte accessibile da Internet)
- Azure Arc
- AWS Outposts
- Public (Il cloud è normalmente accessibile su Internet)
- Cloud provider =>
- Hardware
- Fornisce prima di tutto tutto un’insieme di apparecchiature hardware (computer, networking, storage) che possono essere “affittate”.
- Esempio di servizi
- AI (Intelligenza artificiale).
- IOT.
- Kubernetes.
- Creare un server (autogestito) e pagare solo per quanto si usa.
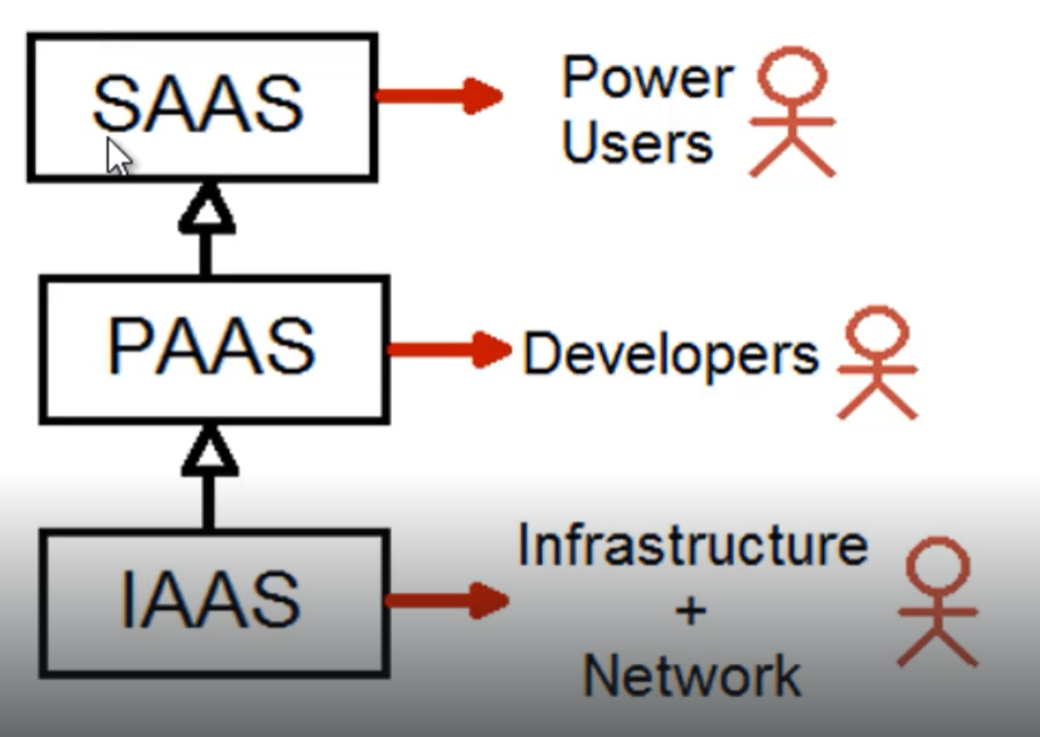
- Classificazione dei servizi =>
- Un cloud provider fornisce una serie di servizi che possono essere classificati in 3 tipi diversi
- Ognuno di queste 3 classificazioni è indirizzata a 3 categorie differenti di potenziali users
- Le operazioni fatte dagli utenti specializzati in uno di questi 3 livelli sono devono risultare trasparenti agli altri 2 livelli.
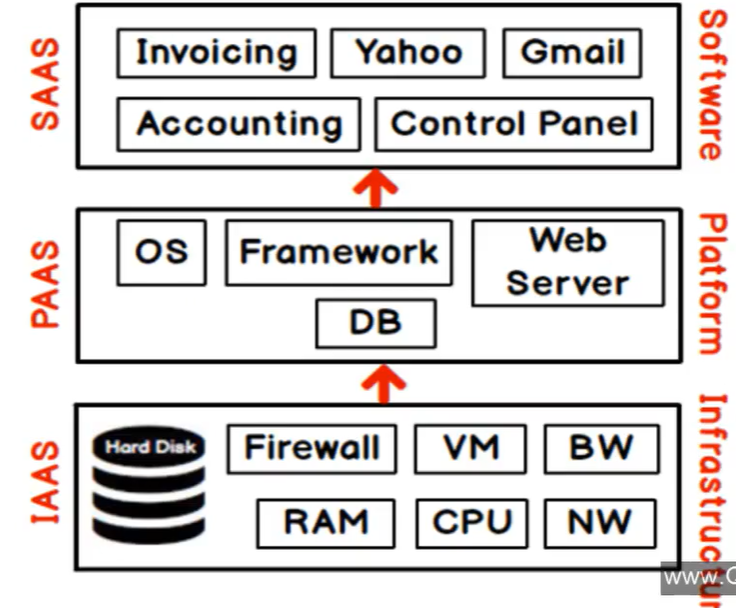
- IaaS (Infrastructure as a service) / Servizi di infrastruttura =>
- Il provider fornisce i requisiti fisici (metallo)
- Router, Hard disk, Network, Computer, Ram.
- Il cliente creare delle Virtual Machine e vi installa i software necessari.
- Servizi indirizzati ad esperti dell’ IT
- Il provider fornisce i requisiti fisici (metallo)
- PaaS (Platform as a service) / Servizi di piattaforma =>
- Il provider fornisce i framework/piattaforme che rendeno vivo il metallo (eseguono le applicazioni)
- Compute, Networking, Storage, Runtime environment, Scaling, Securiry
- Sistema operativo, RDBMS, .NET, Java, Web servers
- Il cliente ha il controllo delle applicazioni (crea il codice e ne fa l’upload sul cloud) e dei dati (es: web apps)
- Il cliente non ha accesso alle sottostanti Virtual Machines (sono responsabilità del provider) dove sono eseguite le web apps (e gli altri servizi di piattaforma)
- Servizi indirizzati a sviluppatori capaci di redigere script
- Il provider fornisce i framework/piattaforme che rendeno vivo il metallo (eseguono le applicazioni)
- SaaS (Software as a service) / Servizi software =>
-
- Applicazioni eseguite completamente sul cloud
- In questo caso il cliente semplicemente usa l’applicazione e non ha il controllo di nulla
- Un esempio significativo è Office365 o Salesforce
- Servizi indirizzati ad utenti finali skillati
-
- Altri tipi =>
- FaaS (Function as a service)
- DBaaS (DB as a service)
- IOTaaS (IOT as a service)
- AIaaS (AI as a service)
- Hardware

Github Actions
- Operazioni di rilascio centralizzate in un unico ambiente (es: CD in Github) =>
- Potenzialmente ogni membro del gruppo di sviluppo potrebbe dal proprio Visual Studio fare il deploy dell’applicativo tramite la funzionalità di ìpublish’
- In realtà questo non avviene in quando è preferibile centralizzare le normali operazioni di build, test e deploy dando la responsabilità sempre e unicamente ad un environment.
- Ciò che avviene è che ogni membro semplicemente fa il commit sul repository centrale in Github
- Sarà quindi responsabilità di Github fornire i necessari build servers (sempre disponibile, liberi da malware, ecc..) per svolgere tutte le operazioni necessarie per il rilascio (build, test, deploy) delle nostre modifiche
- Fare il deploy dal proprio computer non garantisce il massimo della affidabilità e sicurezza.
- Continous Deployment =>
- Affidabile
- Ripetibile
- Sicurizzato
- Gratis per repository pubblici
- Fare il build
- Linux
- Windows
- Mac
- File di configurzione (.yml) del workflow
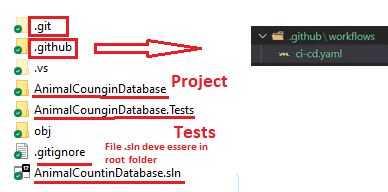
- Per poter utilizzare le Github actions è sufficiente aggiungere i seguenti file e cartella al nostro progetto
- Se si usa ‘Visual Studio Code’ è possibile installare l’extensions ‘GitHub Actions’ per agevolarci nella scrittura del file di configurazione della nostra action
- Aggiungere alla cartella radice del nostro progetto la nuova cartella <.gihub>
- Aggiungere a tale cartella la sottocartella <forkflows>
- Infine aggiungere a tale sottocartella un file .yml
{kind=link}
-
- Sezione on
- Descrivo quale azione attiva il nostro forkflow (nell’esempio sotto, sarà ogni push fatto nel repository)
- Sezione jobs
- Aggiungo le attività che il nostro forkflow andrà a fare
- Steps
- Ogni attività è composta da azioni (o steps) cje contengono nel dettaglio cosa verrà effettivamente eseguito dal nostro workflow
- Nel file di configurazione è possibile richiamare delle actions nella sezione steps per realizzare il workflow desiderato
- Nel sito GitHub marketplace è possibile trovare molte action
- esempio file .yml:
- Sezione on
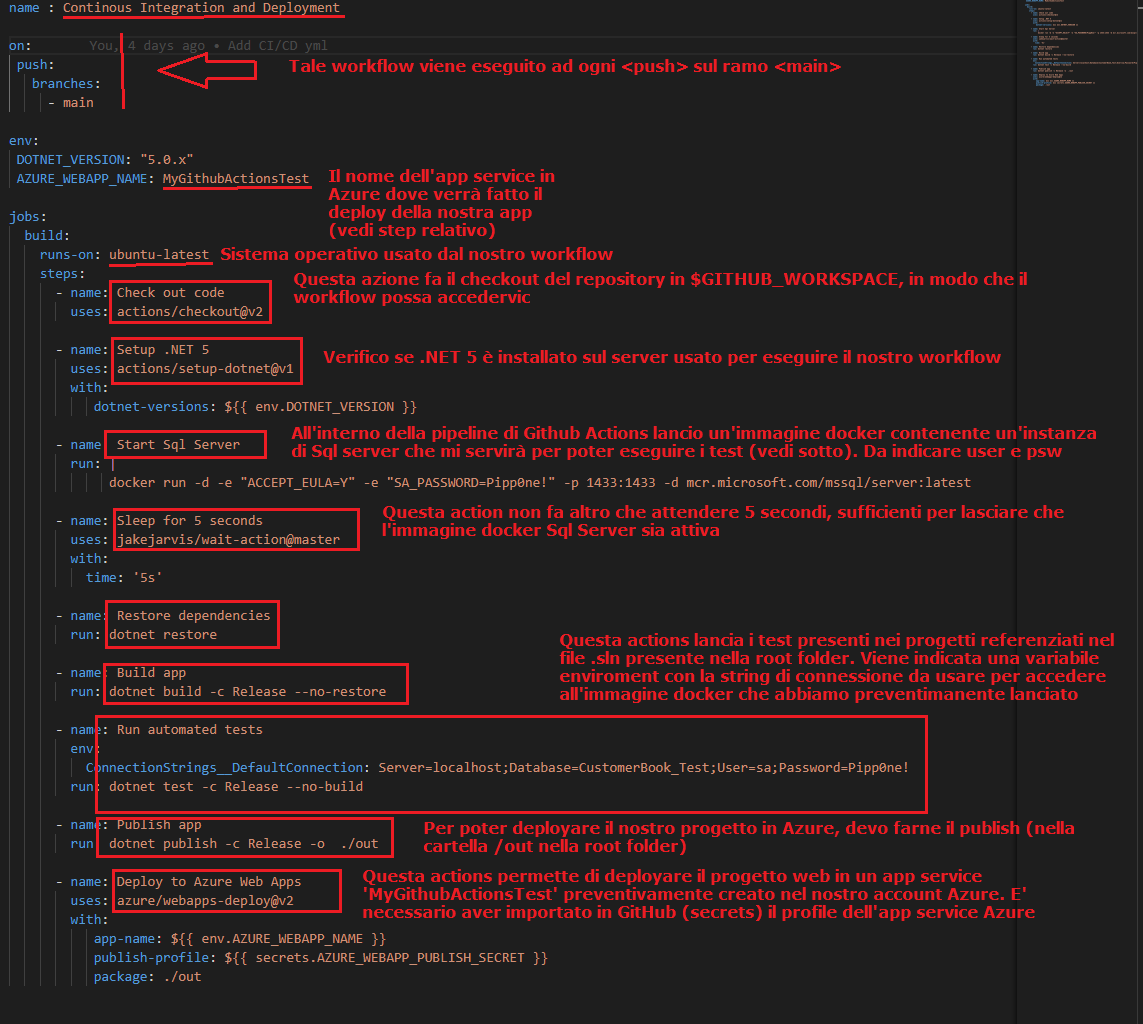
- Customizzare variabili d’ambiente
- Nella stesura del nostro workflow di GitHub Actions è possibile customizzare le variabili d’ambiente usate nei nostri progetti (file appsettings.json)
- E’ necessario però in essi modificare il codice che legge il file appsettings.json aggiungendo .AddEnvironmentVariables()
-
var configuration = new ConfigurationBuilder() .AddJsonFile("appsettings.json") .AddEnvironmentVariables() .Build();
- Connettersi a Azure (Continuous Delivery) =>
- Per potersi connettere ad Azure da Github Actions è necessario autenticarsi. Ci sono 2 possibilità per ottenere le credenziali necessarie per effettuare il deployment:
- Service principal (professional way) =>
- Registrare in Azure ‘Access Control (IAM)’ un nuovo ‘Service principal’, una sorta di account da dedicare al servizio ‘GitHub Actions’
- Publish profile (xml)
- Aprire il file profile in Azure (Vedi capitolo ‘Azure Console’)
- Importare il contenuto di tale file in un’azione ‘GitHub secrets’ così da non dovere inserire le credentials ad ogni operazione di deploy.
- Service principal (professional way) =>
- Per potersi connettere ad Azure da Github Actions è necessario autenticarsi. Ci sono 2 possibilità per ottenere le credenziali necessarie per effettuare il deployment:

-
- Impostare ‘GitHub secrets’ =>
- Nel sito GitHub aprire il tab ‘Settings’ => ‘Sercrets’
- Creare un nuovo ‘New Repository Secrets’
- Il nome deve essere interamente maiuscolo (es: AZURE_WEBAPP_PUBLISH_SECRET)
- Copiare il file contenuto del ‘Publish profile’ recuperato nell”app service’ che ospiterà il deploy della web app
- Riguardo all’immagine in alto, AZURE_WEBAPP_NAME = app service name
- Aggiungere lo step nel file .yml di configurazione dell’action forkflow per poter deployare verso una web app di Azure (che abbiamo precedentemente creato o che esiste già)
- Nel marketplace di GitHub è possibile trovare l’action ‘for deploying to Azure Web App’
- Impostare ‘GitHub secrets’ =>
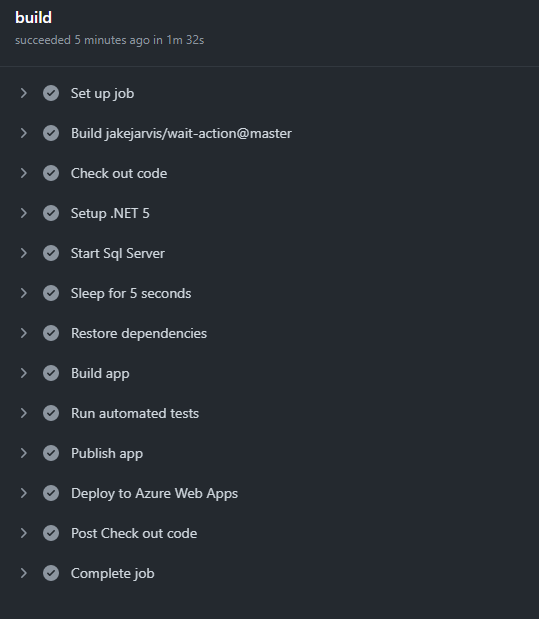
- Github ‘Actions tab’
- Usare il sito github e aprire il tab ‘Actions’
- E’ possibile verificare se il workflow che abbiamo scritto nel file di configurazione .yml e tutti i suoi step sono stati eseguiti con successo
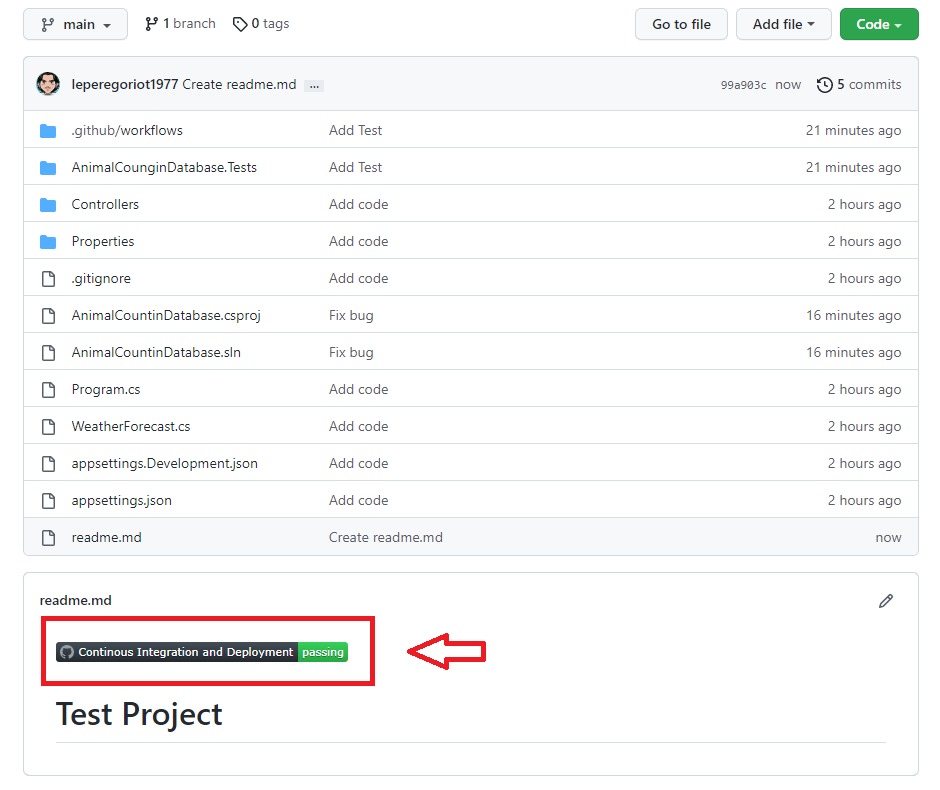
- Creare status ‘badge’ markdown
- Direttamente nell’interfaccia di gestione dei job legati al forflow è possiible recuperare lo snipper per poter visualizzare velocemente se i test falliscono o meno
- Tale snippet può essere piazzato nel file readme.md così da poter essere facilmente reperibile
Azure Preview
- Azure regions
- Quando si attiva un servizio in Azure è possibile scegliere una regione geografica (tra le 60 disponibili) dove cioè è situato fisicamente il data center di riferimento per il nostro servizio.
- Criteri scelta della region (come scegliere a quale ‘Region’ assegnare la risorsa che stiamo creando) =>
- La prossimità geografica con la propria prevista audience.
- La disponibilità del servizio che si sta creando (non tutte le ‘Region’ hanno tutti i servizi accessibili)
- La disponibilità dell’Avaibility Zones’, cioè il fatto che la ‘Region’ che stiamo scegliendo abbia più di una zone (data center).
- Le tariffe del servizio scelto possono variare da ‘Region’ a ‘Region’.
- Paired regions
- Alcune region hanno una regione accoppiata che è utile in caso di malfunzionamento di tutte le zone (data center) dell’intera region.
- Gli accoppiamenti tra regioni sono creati da Microsoft e non posso essere modificati dal cliente.
- Gli accoppiamenti tra regioni possono variare da servizio a servizio.
- Azure zones
- Ogni data center è chiamato zone.
- Availability Zones =>
- Quando una region dispone di più una zone (un data center) allora la regione ha Availability Zones.
- Alcuni servizi usufruiscono di tale possibilità che migliora le performance in caso di malfunzionamento di una zone.
- Azure Architecture Icons
- Aprire il link sottostante e cliccare su ‘Download SVG icons’
- Download Icons
Azure Portal
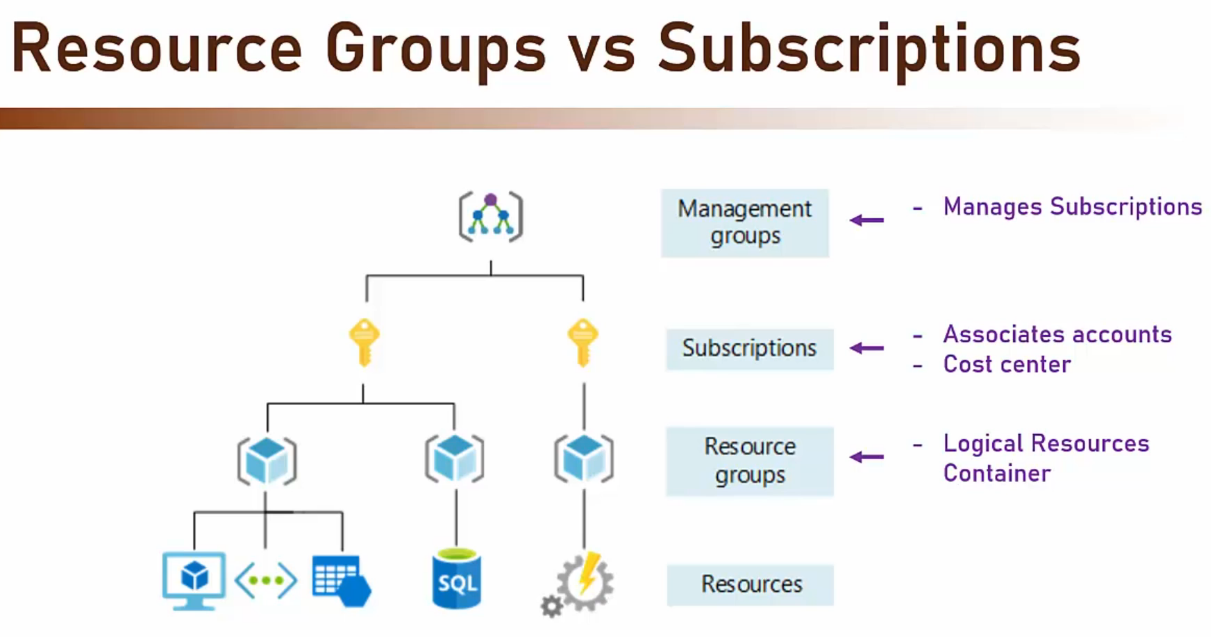
- Management groups =>
- Permette di gestire le differenti ‘Subscription’
- Subscription =>
- Per poter accedere ai servizi Azure è necessario registrarsi e scegliere un plan.
- E’ una sorta di ‘logical container‘ contenente le varie risorse che abbiamo scelto e tutti gli account creati.
- Centro dei costi => E’ il cost center di tutti le risorse contenute.
- Può essere collegato a molti account.
- Account =>
- E’ l’identity con la quale si accede alle risorse presenti nella ‘Subscription’.
- Può essere collegato a molte ‘Subscription’.
- Resource Group =>
- Un ‘Resource Group’ deve necessariamente fare riferimento ad una ‘Subscription’
- Un ‘Resource Group’ può essere inteso come una ‘Sotto-subscription’
- Prima di selezionare un servizio è necessario evidenziare in quale gruppo inserirlo
- Come nel caso delle ‘Subscription’, anche un ‘Resource Group’ è un ‘logical container’.
- La quasi totalità dei servizi offerti da Azure necessita di essere associato ad un ‘Resource Group’.
- I Resource Group permettono di gestire in modo migliore i vari servizi che si è scelto di attivare
- Ad esempio permettono più facilmente di eliminare le risorse non più desiderate senza paura di avere delle sovrapposizioni indesiderate.
- Sono gratuiti => E’ possibile crearne quanti se ne vogliono.
- Naming convention =>
- E’ buona norma usare il suffisso o prefisso ‘rg’ o ‘RG’ alla fine del nome scelto per un nuovo ‘Resource Group’.
- RG-Project-Dev oppure Project-Dev-rg
- E’ buona norma usare il suffisso o prefisso ‘rg’ o ‘RG’ alla fine del nome scelto per un nuovo ‘Resource Group’.
- Esempio di ‘Resource Group’ => Ogni ambiente di deploy ha le proprie risorse
- Development
- Test
- Production
- Esempio di ‘Resource Group’ => Ogni gruppo di lavoro ha delle proprie risorse
- Team A
- Team B
- Console =>
- Overview =>
- visualizzo informazioni come URL + FTP credentials
- Profile file (xml) =>
- Dal menù ‘overview’ è possibile downloadare (o copiare) il file profile (‘Get publish profile’)
- Importare tale file in V’isual Studio’ così da non dovere inserire le credentials ad ogni operazione di deploy.
- Attenzione => contiene importanti informazioni di sicurezza che ci parmettono di autenticarci in Azure
- Properties => visualizzo informazioni
- Deployment center => Gestisco le credenziali per fare il deploy (es: creo credenziali FTP)
- Overview =>
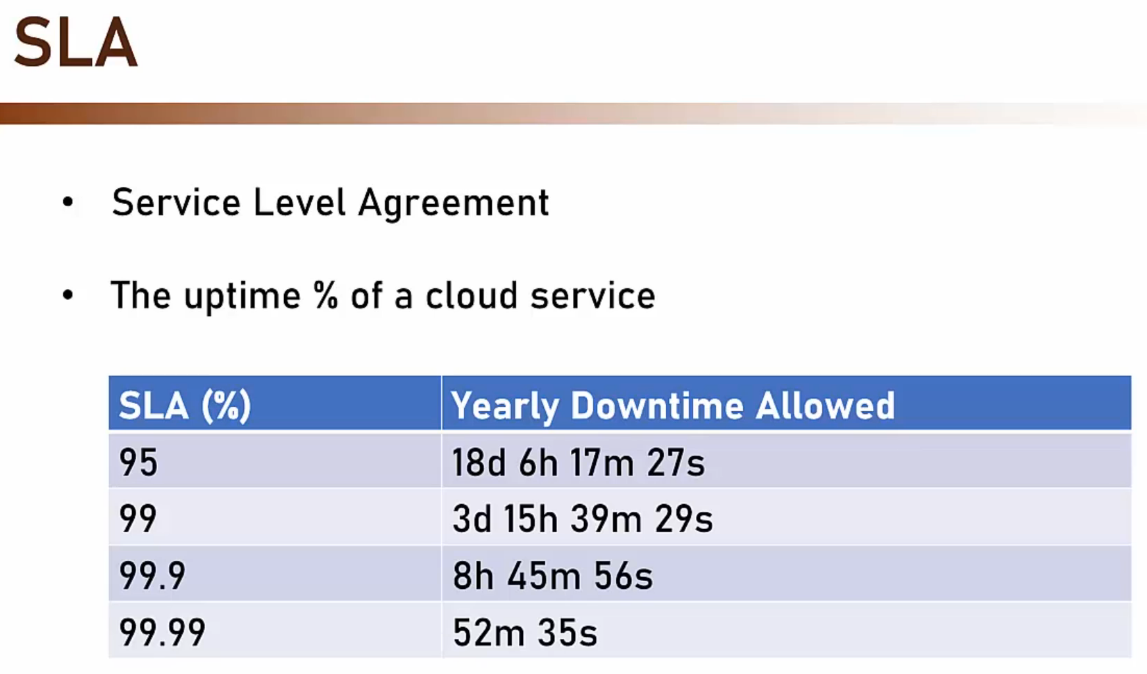
- SLA (Sevice Level Agreement)
- E’ il tempo in cui il servizio può essere down
- Tale valore è definito a livello contrattuale
- Quando si crea un servizio è molto importante avere nozione di quale SLA è associato
- Tool per calcolare SLA
- SLA Totale del nostro sistema
- Per calcolare l’SLA totale del nostro sistema è sufficiente moltiplicare i singoli SLA di tutti i servizi che ne fanno parte
- SLA servizio 1 * SLA servizio 2 * SLA servizo N
- Costi
- Quasi ogni risorsa creata ha un costo (‘Resource Group’ sono un’eccezione in quanto non hanno costo)
- Politiche dei costi =>
- Per risorsa
- es: Virtual Machine => Si paga al momento della creazione della VM scelta.
- Per consumo
- es: Function Apps => Non si paga alla creazione di una funzione ma solo quando questa è effettivamente usata
- Reservation
- Si paga in anticipo l’utilizzo di una risorsa per un dato periodo. Ottenendo cosi uno sconto.
- Quando un servizio permette la ‘Reservation’ tanto vale approfittarne
- Per risorsa
- Calcolatore dei costi
- Impostare un budget
- Selezionare ‘Cost management + billing’
- Selezionare ‘Cost management’
- Selezionare ‘Budget’
- Indicare una o più mail a cui Azure invia l’avviso di raggiunta soglia del budget.
- Indicare la soglia di costo
- Indicare la percentuale raggiunta la quale Azure mi avvisa
- Tecniche per ridurre i costi
- Auto shutdown
- E’ possibile impostare per esempio che le macchine di sviluppo o test possano spegnersi ad una data ora del giorno (ad esempio quando si sanno non utilizzate).
- I costi per lo storage e per l’IP (se statico) rimangono anche se la macchina è spenta.
- Fino a 50% di risparmio.
- Reserved instances
- Si paga per un periodo medio-lungo di tempo e in anticipo, così da ottenere uno sconto.
- I pagamenti possono essere mensile ma non è possibile interrompere anticipatamente il servizio.
- E’ utile per macchine di produzione (che sono pensate per funzionare in continuo).
- Fino a 62% di sconto.
- Spot instances
- Azure offre delle risorse che sono libere a prezzi scontatissimi ma può riprenderne il possesso in tempi molto brevi.
- Fino a 90% di sconto.
- E’ utile per delle macchine che ospitano task non continui e non critici (batch processes, long running calculations).
- Disk optimisation
- E’ possibile scegliere tra premium SSD o standard SSD.
- La scelta del disco può avere conseguenze sull’SLA (il tempo annuale garantito di funzionamento della risorsa).
- Varie
- Scegliere la giusta potenza della CPU in modo di non avere troppi momenti di non utilizzo o sotto utilizzo della stessa.
- Preferire Linux a Windows quando possibile.
- Verificare il prezzo nelle ‘Region’ adiacenti. Potrebbe essere inferiore per la stessa risorsa e settaggio.
- Auto shutdown
- Cloud Shell =>
- Permette l’accesso alla Azure CLI o alla Azure PowerShell
- AzureCLI – Bash (è più integrata e utilizzabile direttamente in applicazioni scritte in Java o per IPhone per esempio).
- Azure Powershell.
- E’ necessario creare uno ‘storage’ per memorizzare i file dei comandi shell.
- E’ possibile usare AzureCli o Azure Powershell direttamente dal ‘Cloud Portal’
- Oppure scaricare le 2 CLI direttamente sul proprio computer.
- In tale caso sarà necessario loggarsi indicando la propria ‘Subscription’. Cosa che usando l’Azure Portal’ non è richiesta.
-
Bash $ ai group create l westus n CliTest-rg [Creo il nuovo 'resource group' CliTest-rg] PowerShell >New-Azresourcegroup -Name PSTest-rg -Location westus [Creo il nuovo 'resource group' PSTest-rg]
- Permette l’accesso alla Azure CLI o alla Azure PowerShell
Azure Compute Services (Virtual Machines, Cloud Services, App Services, AKS, Azure Functions)
- Cosa è =>
- Insieme di servizi cloud per fare l’host ed eseguire applicazioni
- Permette di fare l’upload del proprio codice ed eseguirlo
- Offre diversi livelli di controllo e flessibilità
- Ne fanno parte servizi legati a IaaS e PaaS
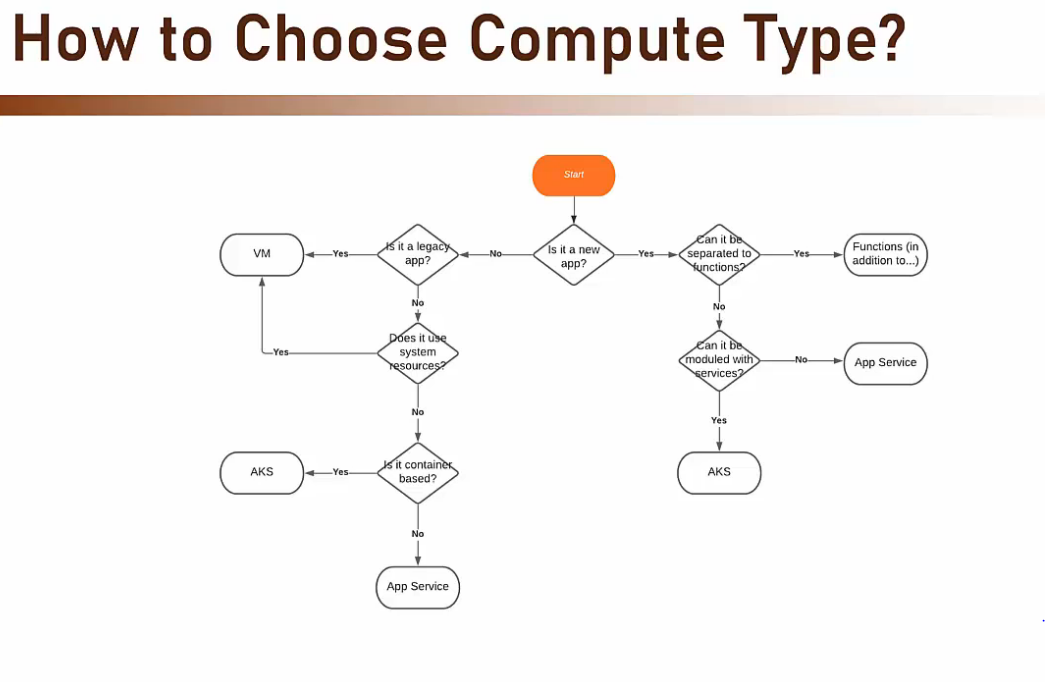
- Quale di questi servizi scegliere?
- ‘Legacy App’ significa un’applicazione scritta in linguaggi obsoleti (C++, classic ASP) che non sono supportati da nessuna piattaforma gestita presente n Azure.
- Allora l’unica scelta possibile è optare per ospitare la nostra app in una VM.
- ‘Use System Resource’ significa che l’app che voglio ospitare in Azure interagisce direttamente con risorse di sistema come’socket, registri del sistema operativo, ecc. ma nessuna soluzione gestita presente in Azure permette l’iterazione diretta con tali risorse di sistema.
- Allora l’unica scelta possibile è optare per ospitare la nostra app in una VM.
- ‘Legacy App’ significa un’applicazione scritta in linguaggi obsoleti (C++, classic ASP) che non sono supportati da nessuna piattaforma gestita presente n Azure.
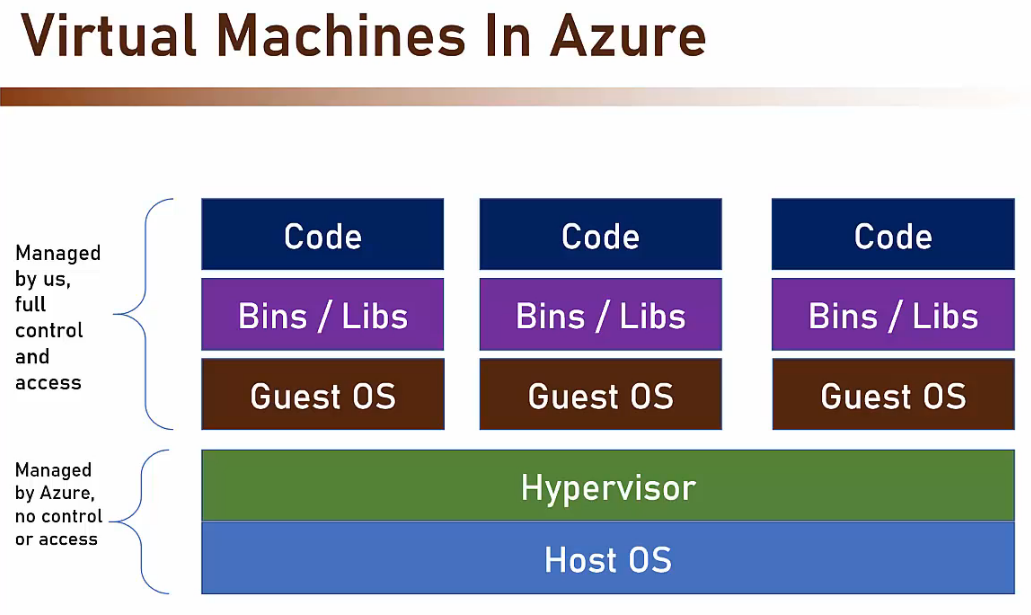
- Virtual Machine =>
- E’ un server non-reale che funziona su un server fisico.
- Possono essere create velocemente in quanto basate su un server fisico.
- Dal punto di vista dell’utilizzatore corrisponde ad un server fisico.
- Unmanaged service
- Azure non gestisce direttamente cosa accade all’interno di un VM.
- E’ responsabilità dell’utente finale.
-
- Creare una nuova Virtual Machine
- Selezionare la posizione
- Selezionare l’immagine (OS + sofware pre-installato)
- Selezionare la dimensione della memoria e della CPU
- Deployment task
- Ogni volta che si crea una nuova risorsa in Azure, viene creato un task per il deploy che crea tutte le risorse complementari
- Tale task viene eseguito all’Azure Controller che ne esegue tutti i passaggi.
- Resorse addizionali
- Alla fine del deploy della nostra nuova VM, in realtà Azure avrà creato almeno 4 risorse oltre alla VM vera e propria.
- Tutte queste risorse sono necessarie al funzionamento della VM stessa.
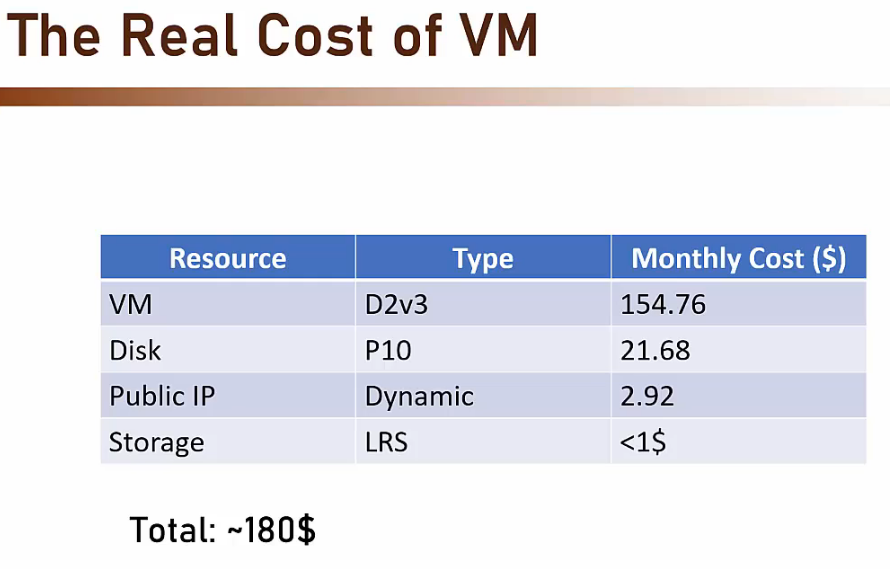
- Costi
- Controllare sempre il costo
- Virtual Machine
- Disk
- IP (non sempre)
- Dinamico (cambia ogni volta che la VM è riaccesa)
- Statico
- Storage
- In questo caso corrisponde allo spazio usato da Azure per ospitare la nostra VM
- Non è nostra competenza ma dobbiamo pagarlo.
- Creare una nuova Virtual Machine
-
-
-
- Azzeramento costi
- E’ possibile azzera i costi legati ad una VM semplicemente spegnendola. Non è necessario eliminarla (come invece bisogna fare con gli ‘App Service’).
- Azzeramento costi
-
- Deployare di 2 o più VM ridondanti =>
- Concetti
- Availability di una VM
- Come gestire le proprie VMs in modo che da garantire il servizio per più tempo possibile.
- Availability di una VM
- Concetti
-

-
-
-
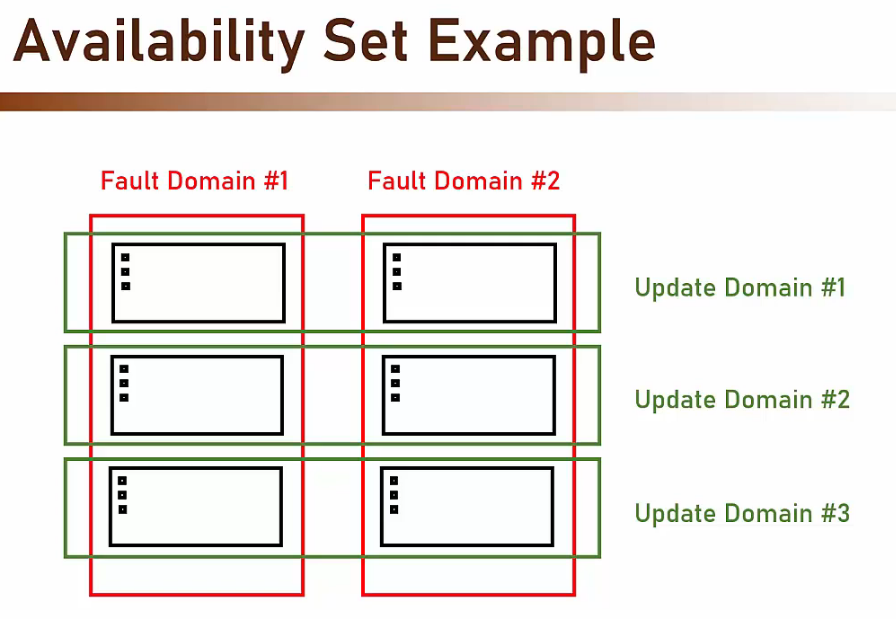
- Fault domain
- Equivale a un rack fisico che fa riferimento ad un’unica sorgente elettrica e di rete è utilizzata per far funzionare più servers fisici.
- E’ meglio evitare di avere tutte le VM o i server nello stesso ‘Fault domain’ o rack.
- Update domain
- Equivale a un gruppo logico di apparecchiature hardware che Azure può stoppare per manutenzione nello stesso momento.
- E’ meglio evitare di avere tutte le VM o i server nello stesso ‘Update domain’
- Fault domain
- Availability options =>
- Availability zone (Zone-level redundancy) =>
- Se disponibile, è la scelta migliore.
- Posso scegliere in quale ‘Zone’ (tra quelle disponibili nella ‘Region’ scelta) deployare la mia VM
- Fornisce la protezione contro il guasto di un’intera ‘Zona’ (=datacenter)
- Offre la migliore SLA.
- Se devo fare il deploy di 2 VMs identiche allora potrò scegliere due ‘Availability zone’ diverse nella stessa ‘Region’.
- Availability Set è gratuito. Si paga per la seconda VM di ridondanza.
- Availability set (Domain-level redundancy) =>
- Da usare nel caso nella nostra ‘Region’ non sia disponibile ‘Availability zone’.
- E’ un’insieme di tot ‘Fault domain’ e tot ‘Update domain’ nel quale le proprie VMs saranno distribuite.
- Tutti i domain sono nella stessa ‘Zone’ (data center).
- Quando si configurano due virtual machine identiche è possibile di associarle ad un ‘Availibility Set’, scegliendone poi il numero di ‘Fault domain’ e di ‘Update domain’.
- Se non è stato scelto nessun ‘Availibility set’ sarà Azure che deciderà in quali rack mettere le mie VMs senza prendere in considerazione i domain.
- Availability Set è gratuito. Si paga per la seconda VM di ridondanza.
- Availability zone (Zone-level redundancy) =>
-
-
-
- ARM Template =>
- Sono 2 file json che rappresentano le configurazioni scelte per la nostra VM
- parameters.json
- template.json
- E’ diviso in 3 parti:
- Parametri
- Variabili
- Risorse
- E’ possibile fare il download dei 2 file e modificarli.
- Creare una VM con ARM Template (E’ possibile usare i 2 file una volta modificati per creare una VM) =>
- Andare nel ‘Storage account’ legato al ‘Resource group’ creato ‘Cloud shell Storage..’ la prima volta che si è usata la ‘Cloud shell’
- Cliccare su ‘Files share’ e cliccare sul solo file presente.
- Aggiungere una cartella cliccando su ‘Add directory’
- Entrare nella cartella create e fare l’upload dei nostri file json modificati cliccando su ‘Upload’
- Aprire la ‘Cloud Shell’ e scrivere i seguenti comandi per creare una nuova VM secondo le configurazioni presenti nei 2 file =>
- Creare prima un ‘Resourse Group’ da legare alla nuova VM (es: ‘optimized-wm-rg’).
- Lanciare i seguenti comandi:
- Sono 2 file json che rappresentano le configurazioni scelte per la nostra VM
- ARM Template =>

-
- Eliminare una VM =>
- Se si decide di eliminare una VM selezionandola e cliccando su ‘Delete’, Azure ci proporrà di selezionare anche le altre risorse legate alla VM per poterle eliminare se non più necessarie
- La risorsa che non può essere selezionata è la ‘VirtualNetwork’. Infatti Azure immagina che sia condivisa con altre risorse e non ci permette di eliminarla direttamente dal menù della VM.
- Per poter eliminare tutte le risorse legate ad una VM, possiamo eliminare il ‘Resourse Group’ associato (se al momento della creazione della VM ne abbiamo scelto uno ad-hoc)
- Virtual Machine Scale Set (Scaling out) =>
- E’ un gruppo logico di VM (un pool di VM uguali) che condividono la stessa immagine.
- Permette di gestire un sovraccarico imprevisto facendo lo scale-out (aggiungo nuove VM identiche per meglio ripartire il carico).
- Dopodiché é possibile tornare alla situazione standard facendo lo scale-in (disattivo le VM che avevo attivato per gestire il sovraccarico).
- Non sarà possibile modificare la VM machine originale per evitare che le repliche create nello ‘Scale Set’ perdano tali modifiche.
- Il meccanismo di ‘Scale Set’ è gratis. Si pagano le VM utilizzate per implementarlo.
- Attivazione del meccanismo di ‘Scale Set’ =>
- Manuale
- Automatica
- E’ possibile impostare delle ‘Regole di scaling’ basate su differenti possibili indicatori (es: Percentuale della CPU).
- Normalmente si inserisce una regola per lo scale-out e una regola inversa per lo scale-in.
- Applicazioni Web
- E’ possibile far precedere lo ‘Scale Set’ da un ‘Load balancer’ che è capace di reindirizzare le ‘web requests’ alle differenti VM attive del nostro ‘Scale Set’.
- Per preparare una VM ad accogliere una web .NET Core è necessario =>
- Aggiungere il Web Server al sistema operativo scelto per la VM.
- Installare le componenti necessarie per eseguire delle applicazioni .NET Core (Windows Hosting Bundle).
- Copiare la cartella ‘publish’ del nostro progetto .NET (dotnet publish -o /publish) direttamente sul server.
- Accedere al Web Server (es: IIS) e fare click dx su ‘Sites’ e cliccare su ‘Add Web site’ collegando il nuovo sito alla cartella ‘publish’
- Scegliere un none per il sito.
- Scegliere la porta (<application-port>).
- Configurare la Virtual Network legata alla VM in Azure affinché accetti chiamate esterne.
- Sarà possibile accedere alla nostra app digitando http://<virtual-machine-ip>:<application-port>.
- Azure Instance Metadata Services
- Direttamente all’interno di una VM è possibile interrogare due WebAPI che ci danno delle informazioni sulla VM stessa
- In particolare se per la VM in questione sono schedulati degli eventi (come ad esempio l’eliminazione causata da uno scaling)
-
http://169.254.169.254/metadata/instance?api-version=2020-06-01 http://169.254.169.254/metadata/scheduledevents?api-version=2019-08-01
- Eliminare una VM =>
-
- Varie =>
- Dischi aggiuntivi => Se la propria VM necessita di più dischi (oltre a quello predefinito fornito da Azure)
- Aprire il tab ‘Disks’ e aggiungi il disco di cui hai bisogno.
- Non dimenticare che i dischi hanno dei costi e verificalo prima nel ‘Calcolatore dei costi’.
- Vuoi eseguire il backup della tua VM in modo che possa essere ripristinata in caso di guasto?
- Controlla la pagina Backup, dove puoi definire la frequenza del backup e il periodo di conservazione.
- È possibile definire il nome DNS per la VM, in modo che sia accessibile non solo utilizzando il suo IP.
- Questa operazione può essere eseguita facendo clic sul link ‘DNS Name’ => Configura nella pagina ‘Overview’.
- Dischi aggiuntivi => Se la propria VM necessita di più dischi (oltre a quello predefinito fornito da Azure)
- Varie =>
- Cloud service =>
- Ogni cosa che può essere fatta nel cloud è chiamata ‘Cloud Service’
- Creare VMs.
- Creare DB.
- Fare il setup di una rete.
- Usare algoritmi d’intelligentzia artificiale.
- Azure cloud service project =>
- In Visual Studio => new ‘project’ => selezionare i progetti ‘Cloud’ => selezionare ‘Azure Cloud Service’
- oppure convertire un progetto MVC esistente =>
- In Visual Studio => click dx sul progetto => tab Convert => ‘Convert to Microsoft Azure Cloud service project’
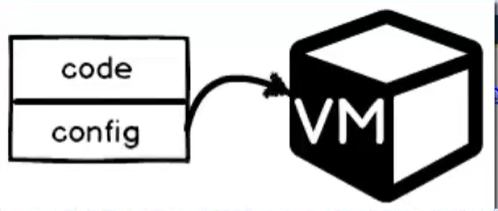
- Config project => Come risultato della conversione viene
- Creato un secondo progetto (<mymvcapp>.Azure) che sarà il progetto di startup e che permette di publicare la nostra MVC application in Azure Cloud
- include qualche file di configurazione
- Aggiunte le necessarie ‘references’ al progetto originario
- Code + config => Il progetto MVC originale (code) + il progetto di configurazione (<myapp>.Azure) vengono deployati in una VM su Azure
- Creato un secondo progetto (<mymvcapp>.Azure) che sarà il progetto di startup e che permette di publicare la nostra MVC application in Azure Cloud
- Ogni cosa che può essere fatta nel cloud è chiamata ‘Cloud Service’
-
- Publish as a Cloud service to Microsoft Azure =>
- In Visual Studio => click dx sul progetto => ‘Publish to Microsoft Azure’
- Sign-in in Azure account e creare il ‘Cloud Service‘ e lo ‘Storage Account‘ riempiendo i dati richiesti
- Cloud service URL => L’app deployata è visibile all’url => https://<mycloudservice>.cloudapp.net
- Exclusive Virtual Machine =>
- In Azure.com si creano 2 nuove ‘resources’ =>
- [opzionale] un nuovo ‘Storage Account’ (utile per attività di tracing, logging, messaggi di errori)
- un nuovo ‘Cloud service’ => questo servizio ospita una VM esclusiva in cui è eseguita la mia applicazione MVC che ho voluto deployare ‘as a service’
- In Azure.com si creano 2 nuove ‘resources’ =>
- Publish as a Cloud service to Microsoft Azure =>

-
-
-
- Enable Remore desktop =>
- Dal menu di questo nuovo ‘Cloud Service’ è possibile cercare la voce ‘Remote Desktop’ e attivare il remoting desktop per collegarsi alla VM.
- Enable Remore desktop =>
- Unico resource group => La VM + il code sorgente appartengono allo stesso ‘resource group’.
- Classic deployment => Il deploy tramite Cloud service dalla community Azure è definito come quello ‘classico’.
-
-
- App Services =>
- Cosa é =>
- Un web hosting completamente gestito (non è necessario creare VM e installarvici i software necessari).
- E’ sufficiente publicare il proprio codice in un’App Service’ e questi funziona direttamente.
- Non avendo creato direttamente una VM allora nessun accesso a essa è possibile.
- Sono integrati con molti ‘Source Control’ e ‘DevOps engine’ (GitHub, Azure DevOps, Docker-hub …).
- Ad esempio è possibile deployare una nuova versione della nostra app su GitHub e questa sarà automaticamente deployata nella nostra ‘App Service’
- Supporta le seguenti piattaforme
- .NET, .NET Core, Nodejs, Java, Python, PHP
- Supporta i containers (es: docker)
- E’ sufficiente ‘impacchettare’ la nostra app in un container e publicarla in un ‘App Service’
- Supporta i seguenti tipi di applicazioni
- Web apps
- Web API
- Web jobs (processi di batch)
- Pagina di un App Service in Azure =>
- Auto-scaling (Scaling out) =>
- In un ‘App Service’ è disponibile un meccanismo automatico di scaling. Per cui di fronte a picchi di traffico, Azure aggiunge delle istanze della propria ‘App Service’ secondo in relazione a diversi indicatori.
- Funzionamento simile al ‘Virtual Machine Scale Set’.
- App service editor
- Posso modificare direttamente online i file già deployati
- Console
- Apro la shell (CLI) per comunicare con la VM in cui l’App Service è in esecuzione.
- Essendo di fatto in una sorta di ‘Sandbox’ dedicata al nostro ‘App Service’, tramite questa shell non è possibile ad esempio installare o eliminare software.
- Auto-scaling (Scaling out) =>
- Varie =>
- Per impostazione predefinita, è possibile accedere ai servizi app tramite http e https.
- Puoi renderlo https solo nelle impostazioni TLS/SSL nel menu ‘App Service’.
- L’ App Service può eseguire anche processi batch (non solo web app con il paradigma richiesta/risposta).
- Questo può essere fatto utilizzando la voce di menu WebJobs, dove è possibile caricare file exe che verranno eseguiti sempre o in orari pianificati.
- Per conoscere l’indirizzo IP dell ‘App Service’
- Aprire la pagine ‘Properties’.
- È possibile trovare l’indirizzo IP virtuale del ‘App Service’ e anche gli indirizzi IP in uscita.
- Si noti il plurale: il servizio app può avere più di un indirizzo IP in uscita.
- Statistiche di utilizzo
- Ricercare a aprire la propria ‘Subscrption’.
- Andare alla voce di menu ‘Usage + Quotas’.
- Da questo menù è possibile vedere il livello di utilizzo dei servizi e le quote rimanenti
- L’accesso ad alcune risorse è plafonato da dei quota (ad es: numero massimo di VM disponibili)
- Le ‘Quotas’ sono plafonate per ‘Region’. Cambiando la ‘Region’ dei nostri servizi possiamo accedere a dei nuovi ‘Quota’
- Per impostazione predefinita, è possibile accedere ai servizi app tramite http e https.
- Costi
- Il costo è in corrispondenza con l’ App Service Tiers scelto.
- Azzeramento costi
- Stoppare il servizio NON è sufficiente per smettere di pagare.
- Per smettere di pagare è necessario fare il ‘delete’ dell ‘App Service’.
- Publish as a AppService =>
- In Visual Studio => click dx sul progetto => ‘Publish’
- E’ possibile che vengano richieste le credenziali per accedere al nostro account Azure.
- Durante l’operazione di ‘publishing’ è possibile selezionare un ‘App Service’ già presente in Azure o crearne uno nuovo.
- In Azure.com si creano 2 nuove ‘resources’ =>
- Un nuovo ‘App Service’ => che ospita l’applicazione MVC che abbiamo deployato ‘as an app’.
- Un nuovo ‘App Service plan’ =>
- Permette di memorizzare la configurazione scelta per la VM che ospita l’applicazione MVC
- Rappresenta l’App Service Tiers selezionato al momento della creazione del nostro ‘App Service’.
- Cosa é =>

-
-
- Not exclusive Virtual Machine =>
- La VM non permette un uso esclusivo della mia applicazione MVC quindi non ho un remote desktop per collegarmici
- App service URL
- La nostra app che si sta pubblicando sarà raggiungibile al seguente URL => https://<myappservice>.azurewebsites.net
- A differenza del caso di una VM, non è proposto un IP ma direttamente un URL. (La VM machine è condivisa).
- Tale URL deve essere univoco in tutto Azure. E’ necessario personalizzare il nome.
- 2 Resources group => La VM e il codice sorgente appartengono a 2 risorse differenti
- Not exclusive Virtual Machine =>
-
-
- Differenze tra ‘Cloud Service’ e ‘App Service’ =>
- Cloud service =>
- Differenze tra ‘Cloud Service’ e ‘App Service’ =>
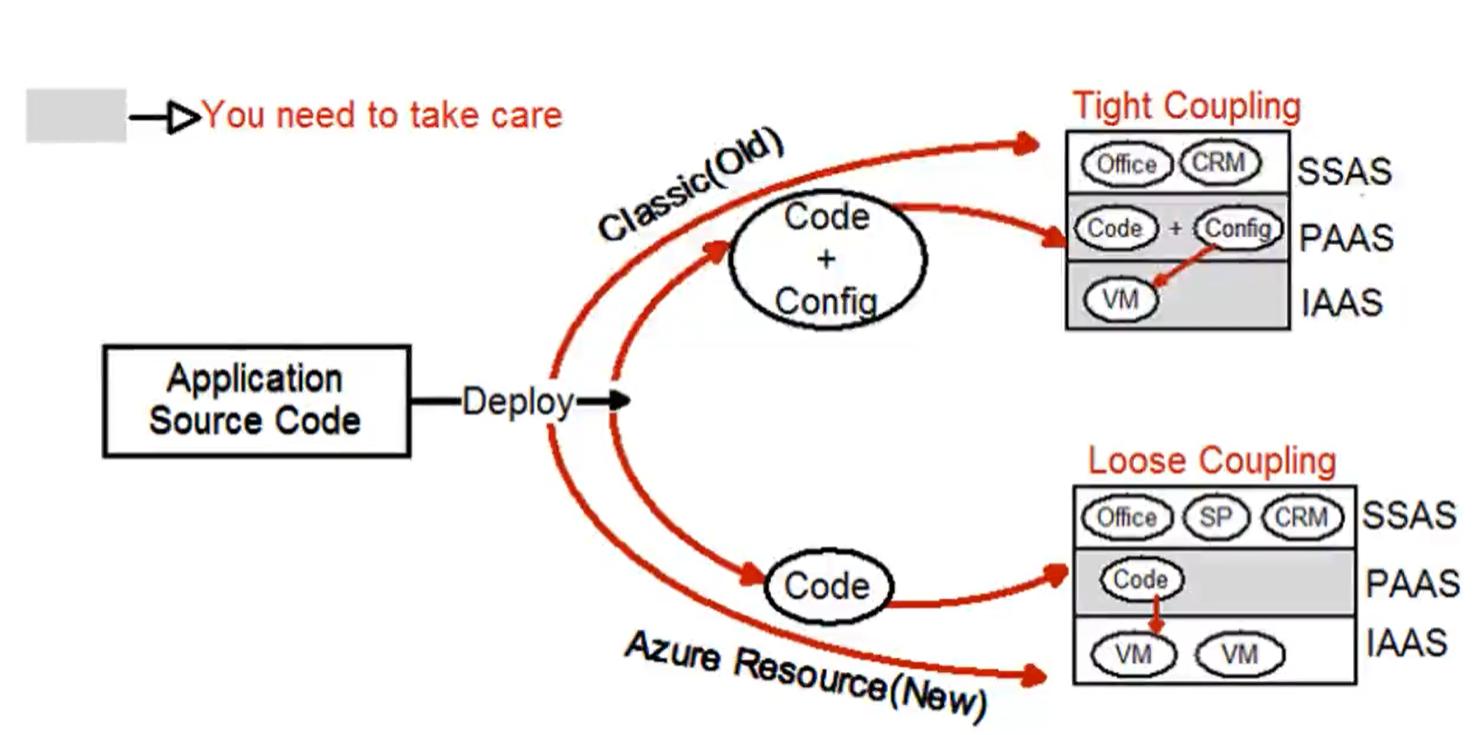
 Tight coupling =>
Tight coupling =>
-
-
-
-
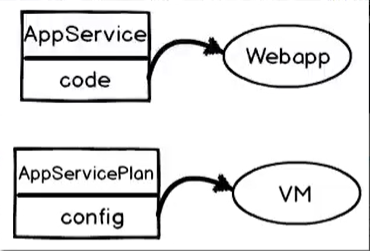
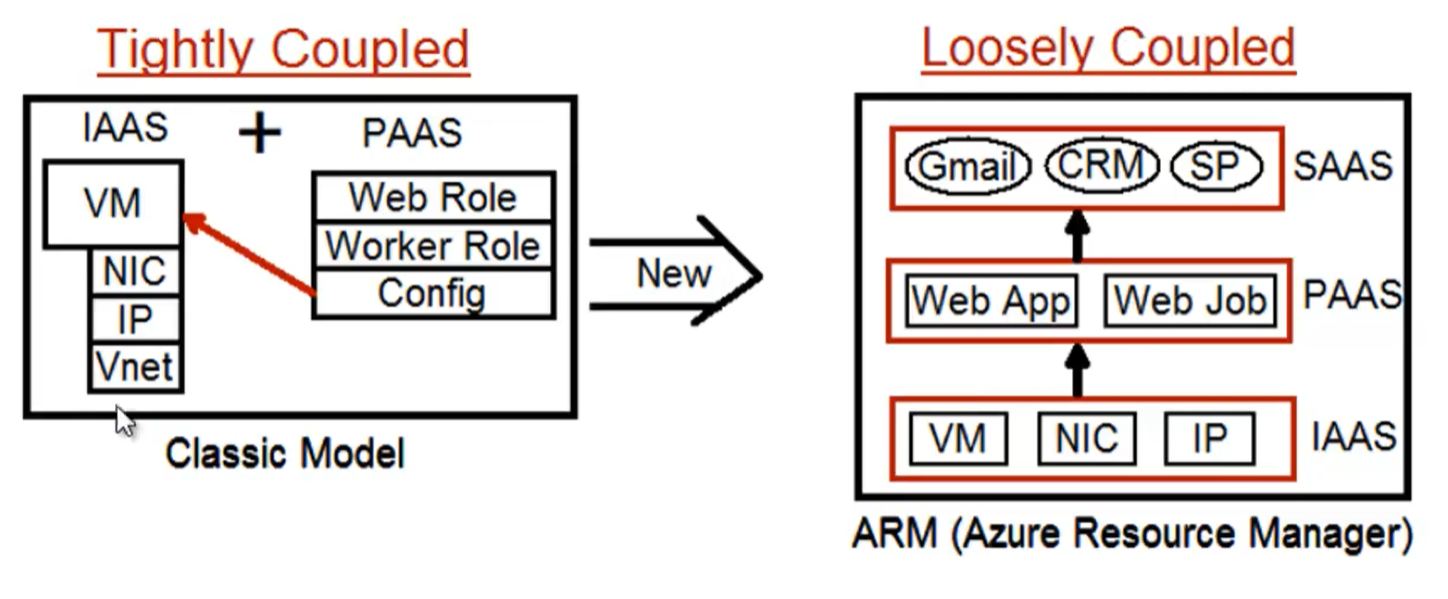
- Deployare la propria applicazione ‘as a cloud service’ crea una struttura più fortemente accoppiata
- Le responsabilità di uno sviluppatore (PAAS) si sovrappongono a quelle di un esperto IT (IAAS)
- Il codice, la configurazione della VM e la virtual machine fanno riferimento ad un unica ‘resource’
- Exclusive VM => Aumento dei costi
-
- App service =>
-
-

-
-
-
- Loose coupling =>
- Deployare la propria applicazione ‘as a app service’ crea una struttura meno fortemente accoppiata
- Le responsabilità tra gli utenti dei diversi livelli non si sovrappongono
- Il codice e la VM (e la sua configurazione) fanno riferimento ad 2 resource separate
- C’è un isolamento completo tra il livello PAAS e IAAS
- Shared VM => Diminuiscono i costi
- Viene rispettato il principio della singola responsabilità
- Loose coupling =>
-
-
- AKS =>
- Permette di deployare e gestire ‘container’ in Azure tramite Kubernetes
- Non ha costo => Il costo è legato alle VM utilizzate.
- Cosa è Kubernetes
- E’ la piattaforma di gestione dei container più popolare.
- Rilasciato da Google nel 2014.
- Problemi da risolvere
- Spesso in un sistema reale si arriva ad avere un gran numero di container deployati (ad esempio per ospitare il front-end, il back-end, il DB e i vari processi batch)
- Deploy automatizzato
- Realizzarlo manualmente può essere lungo e soggetto a errori.
- Scalability
- E’ necessario avere la possibilità di aggiungere/togliere istanze di un container in relazione alla variazione di carico.
- Monitoring
- Tenere monitorata la situazione di tutti i container deployati non è facilmente realizzabile.
- Routing
- Se si hanno più istanze di un container è necessario impostare un meccanismo di equilibrio per istradare le richieste in entrata alle differenzi istanze.
- High-Availability
- Assicurarsi che il nostro sistema possa far faccia a dei crash e alle varie evoluzioni dello stesso.
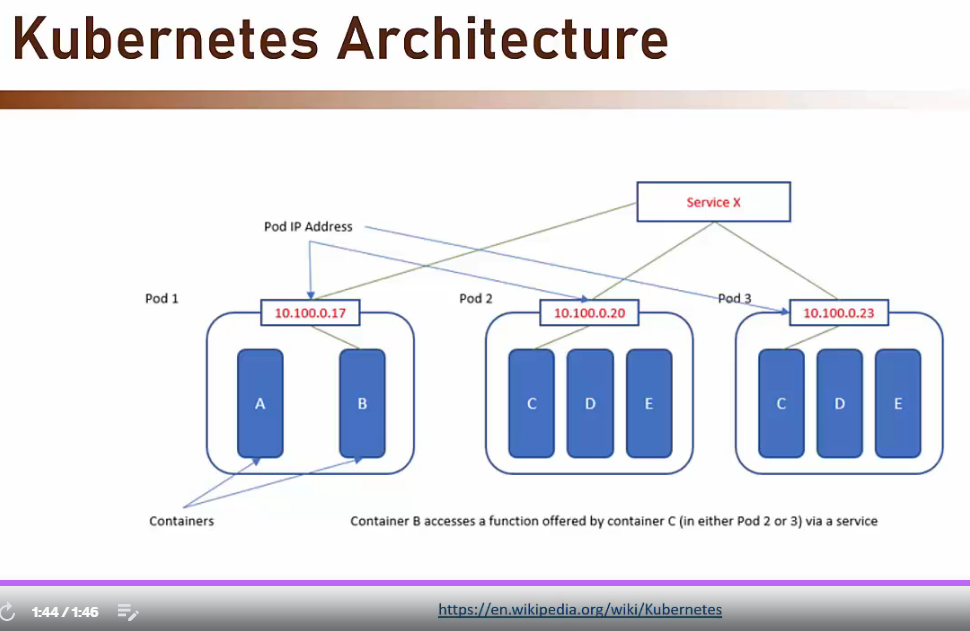
- Kubernetes architecture
- POD =>
- L’unità base in un’architettura Kubernetes è detta POD.
- E’ possibile pensare a un POD come ad un container di container.
- Normalmente un POD coincide con uno e un solo container.
- Un POD fornisce connettività e monitorizzazione all’insieme dei container ivi contenuti.
- IP Address
- Ad ogni POD è associato un indirizzo IP tramite il quale Kubernetes dialoga con i vari container che deve gestire
- Services
- I container hanno accesso alla rete publica tramite dei servizi
- I servizi sono il meccanismo con cui Kubernetes espone al mondo esterno le funzionalità che implementa.
- POD =>
-
- Aggiungere un container Docker a ACR (Azure Container Registry) =>
- Controllare di aver installato ‘Docker desktop’ nella propria macchina.
- Aggiungere al proprio progetto il dockerfile .
- Lanciare il comando docker build per creare un’immagine docker del proprio progetto basata sul dockerfile.
- Lanciare il comando docker run per eseguire la propria immagine in un nuovo container.
- Registrare il nuovo container in ACR (Azure Container Registry):
- Scegliere un nuovo registro
- Oppure crearne uno
- Scegliere il none del registro (es: <my-registry>-acr)
- Scegliere il TIER (Basic, Standard, Premium).
- Se non ancora attiva, attivare la possibilità di creare un nuovo registry
- Nel menù della nostra ‘Subscription’ accedere alla voce ‘Resource Providers’ e attivare la voce ‘Microsoft.ContainerRegistry’

- Selezionare il ‘Resource Group’
- In Azure Portal verrà aggiunta una voce nei ‘Container Registries‘.
- Ora è possibile usare il comando docker push per copiare la nostra immagine docker nel registry appena creato.
- Creare un cluster Kubernetes in Azure =>
- Selezionare ‘Kubernetes Services’.
- Cliccare su ‘Create’ per aggiungere un nuovo servizio Kubernetes (che ospiterà il nostro nuovo cluster).
- Impostare ‘Cluster preset configuration’ selezionando il piano di abbonamento scelto.
- Indicare un nome (ad es: <my-cluster>-aks).
- Scegliere il node size => La potenza del server che ospiterà il nostro cluster.
- Scegliere il node count => il numero di PODS per il nostro cluster.
- Deployare un container (via ARC) nel cluster =>
- Per poter associare un nostro container (es: docker) al cluster è necessario precedentemente averlo aggiungo al registro dei container in Azure (ACR)
- Vedi punto sopra ‘Aggiungere un container Docker a ACR’
- Passare al tab ‘Integrations’
- Come ‘Container registry’ selezionare il registro dei container desiderato tra quelli presenti nel ACR di Azure (es: <my-registry>-acr).
- Connettersi alla proprio istanza Azure e al proprio cluster Kubernetes =>
-
//installare sulla propria macchina la CLI per comunicare con Kubernetes in Azure //dal terminale shell del proprio computer >az aks install-cli //aggiungere la CLI nella variabile d'ambiente PATH in modo che i comandi siano riconosciuti ovunque nel nostro computer >set PATH=%PATH%;"c:\users\<my-user>\.azure-kubectl" //loggarsi ad Azure per poter interagire con il nostro cluster Kubernetes //fornire le credenziali >az login //connettersi al cluter (es: <my-cluster>-aks) >az aks get-credentials --resource-group <my-resource-group> --name <my-cluster>-aks //ora che siamo connessi, possiamo interrogare la nostra istanza ad esempio per sapere quali nodi ci sono //verificare che lo status=ready >kubectl get nodes //deployment.yaml modificare il file di configurazione per il deploy del nostro container (es: docker) in Azure Kubernetes specificare il path dove raggiungere il registry ACR in Azure (es: <my-registry>-acr.azurecr.io/<docker-image>:latest //adesso è possibile lanciare il comando per fare il push del nostro container //nella nostra istanza cluster kubernetes su Azure //Azure creerà anche un servizio per gestire il POD nel nostro cluster Kubernetes >kubectl apply -f deployment.yaml
-
- Per poter associare un nostro container (es: docker) al cluster è necessario precedentemente averlo aggiungo al registro dei container in Azure (ACR)
- Aggiungere un container Docker a ACR (Azure Container Registry) =>
-
-
- Visualizzare il container deployato nel cluster
- In Azure, aprire la scheda del nostr cluster
- Andare al menù ‘Services and Ingresses’
- Selezionare il servizio legato al nostro container
- Associato a tale servizio vi sarà un IP esterno grazie al quale sarà possibile collegarsi al container (e all’applicazione che vi è contenuta)
- Visualizzare i PODS
- Visualizzare il container deployato nel cluster
-
- Azure Functions and serverless (CPU cycle only) =>
- Azure Compute Services – Differenti casi di utilizzo =>
- Esempio 1 (Server + VM) =>
- Ho bisogno di una macchina dedicata e accessibile 24 ore su 24 => creo un server => creo una VM
- Eesmpio 2 (App service) =>
- Ho bisogno di ospitare un sito => creo un app service che avrà una VM dedicata o condivisa
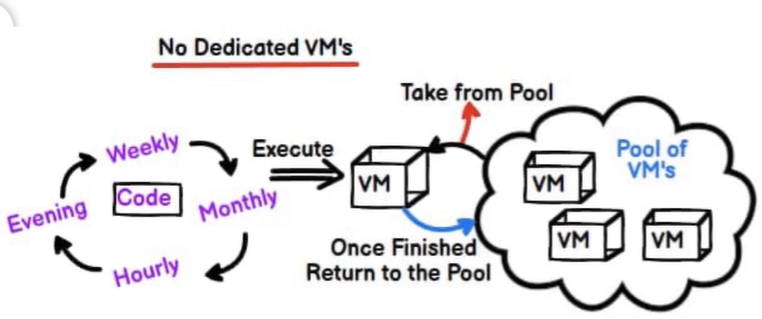
- Esempio 3 (Function app) =>
- Ho bisogno di eseguire un codice a intervalli determinati => ho bisogno solo di cicli della CPU e non di una infrastruttura dedicata
- Ci sarà un pool di VM che posso utilizzare per trovare le risorse per eseguire il mio codice e dopodichéi liberare tale risorse
- Creo una ‘Funzion app’
- Esempio 1 (Server + VM) =>
- Azure Compute Services – Differenti casi di utilizzo =>
-
- Cosa é => Una ‘Function app’ è una piccola routine che:
- può essere ospitata in Azure senza usare un VM (server less).
- viene eseguita a seguito di un evento.
- è molto utile per sistemi ‘Event Driven’.
- Serverless =>
- Per eseguire una ‘Function app’ non è necessario avere un server dedicato perciò si parla di serverless.
- La risorsa che eseguirà una ‘Function app’ sarà presa da un pool di risorse (e quindi non da una risorsa dedicata).
- Sono gestite automaticamente (start, stop, scale) =>
- Non devo interessarmi a nessuna scelta di configurazione delle risorse hardware (VM, CPU, Memory). Sarà Azure che gestirà la cosa per me.
- ScaleController
- In funzione di quante richieste effettivamente riceve una funzione, lo ScaleController decide quante istanze creare per meglio rispondere a tali richieste.
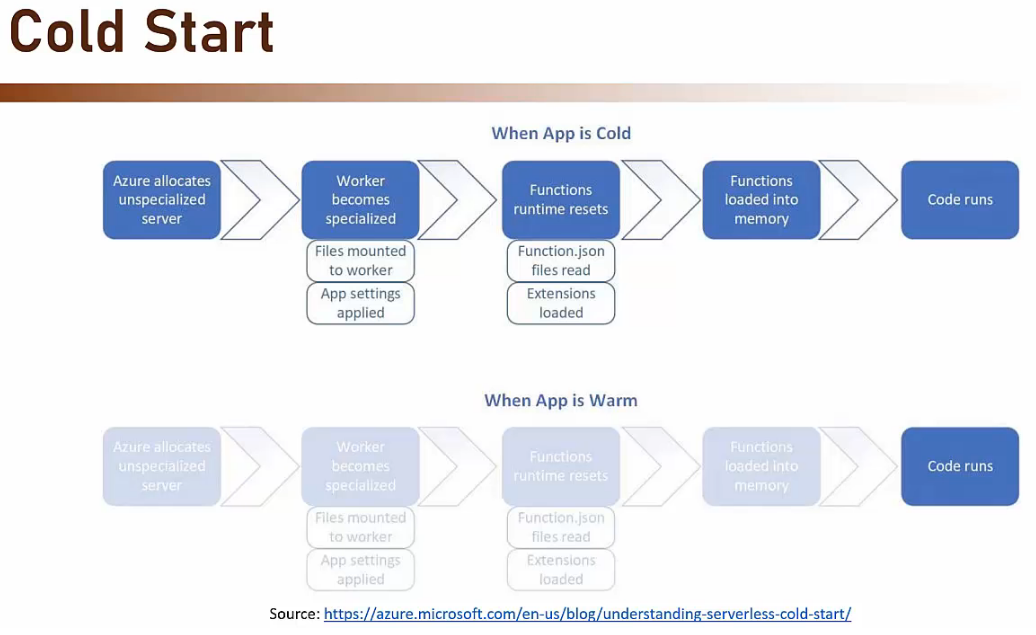
- Cold Start
- Il fatto che Azure gestisca automaticamente l’host che alberga la nostra ‘Function App’ può portare Azure a spegnerlo dopo un certo periodo di inattività della nostra funzione.
- Ciò può portare ad un ritardo di risposta alla prossima attivazione della funzione. Il sistema deve essere riattivato e ciò potrebbe prendere 2 o 3 secondi.
- E’ un problema per i trigger sincroni (HTTP Request).
- Non è un problema per i trigger asincroni (Queue, Timer).
- E’ possibile evitare questo fenomeno scegliendo il buon ‘Azure Function Hosting plan’.
- Cosa é => Una ‘Function app’ è una piccola routine che:
-
- Azure Function Hosting Plan =>
- Consumption
- Si paga per ciò che si consuma
- Tempo di eseguzione (GB/s).
- Numero di esecuzioni (al mese).
- Uno costo aggiuntivo per lo ‘Storage account’ e il ‘Networking’ è possibile.
- Svantaggi
- Non è possibile consumare più di 1.5GB di RAM.
- Cold Start
- Si paga per ciò che si consuma
- Consumption
- Azure Function Hosting Plan =>

-
-
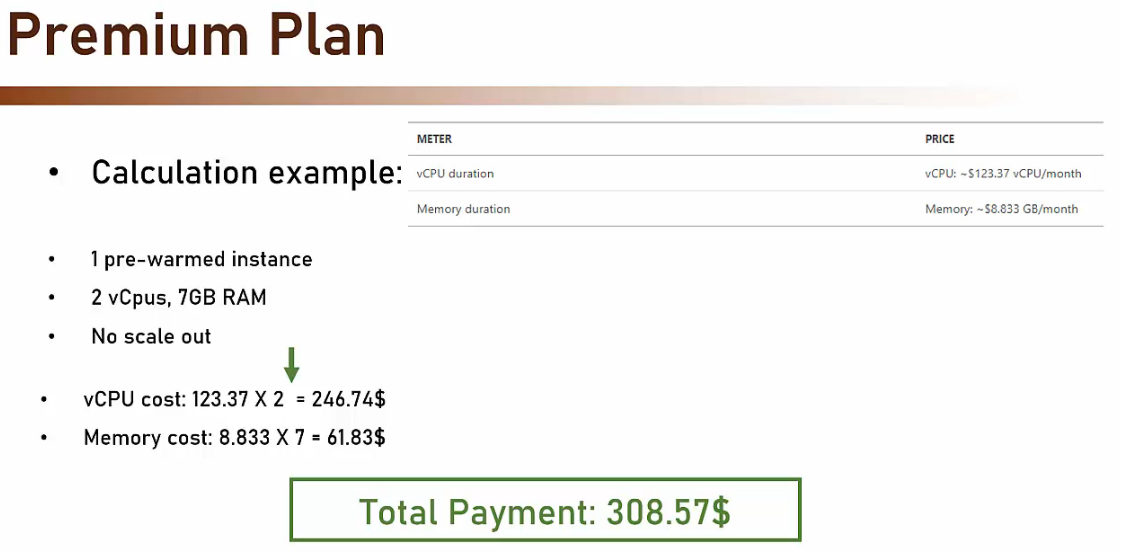
- Premium
- Si paga per le risorse fisse (sempre accesse) assegnate alla nostra ‘Function App’
- Durata vCPU
- Durata della memoria RAM
- Si paga se si sceglie l’opzione di Scale-out
- Vantaggi
- E’ possibile usare tutta la RAM scelta.
- No Cold Start.
- Migliori performance
- Integrazione VNet
- Prezzo certo
- Svantaggio
- Più caro
- Si paga per le risorse fisse (sempre accesse) assegnate alla nostra ‘Function App’
- Premium
-
-
-
- Dedicated
- La ‘Function App’ viene eseguita in un ‘App Service’ esistente (se esiste nella propria ‘Subscription’), condividendone le risorse.
- E’ utile se il server è sotto-utilizzato.
- Nel settaggio dell’ ‘App Service’ scelto per ospitare la nostra ‘Function App’ dobbiamo aver settato ‘Always On’ = On. Evitando che la ‘Function App’ si spenga ad un certo punto.
- Always On => On
- Vantaggi
- Nessun prezzo addizionale
- Svantaggi
- No Auto-Scale
- Dedicated
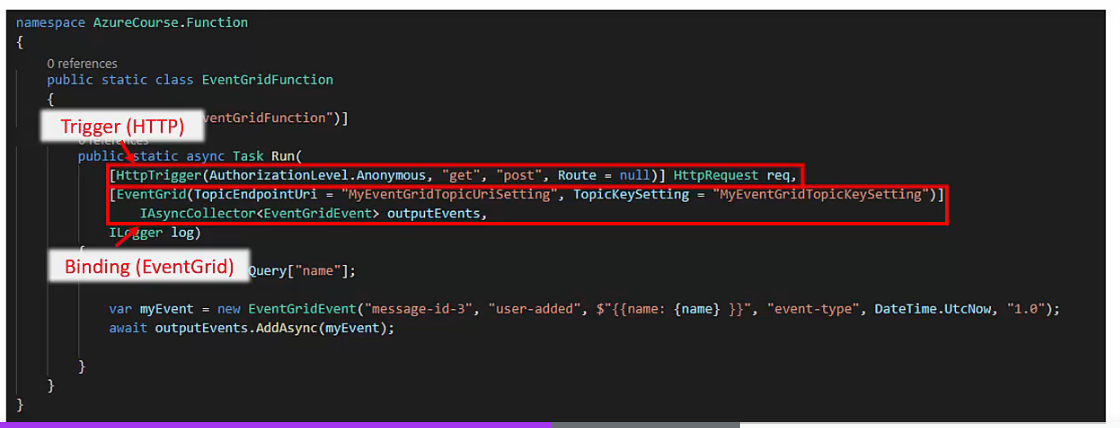
- Triggers (Impostare gli eventi di attivazione delle ‘Function App’) =>
- Contengono la definizione degli eventi che attivano la ‘Function App’.
- Non sono obbligatori ma quasi sempre si usa quando si vuole lavorare con una ‘Function App’.
- Trigger Type (Azure offre una breve lista di tipi di trigger possibili tra cui scegliere. Ben integrati con il resto dei servizi presenti in Azure) =>
- Blob storage
- Cosmo DB
- Dapr
- Event Hubs
- Event Grid
- HTTP Request
- IOT Hub
- Kafka
- Queue storage
- RabbitMQ
- Service Bus
- Timer
- Bindings (Scambiare dati con altri Azure Services) =>
- Contengono la dichiarazione a risorse esterne
- Tramite i ‘Binding’ è possibile impostare delle connessioni con altre risorse presenti in Azure e scambiare dati con esse
- Scambio dati in input
- Scambio dati in output
- Scambio dati in entrambe le direzioni
- Sono forniti come parametri delle ‘Funcion App’.
- Non sono obbligatori ma si usano spesso per dialogare con le altre risorse.
- Binding Type (Azure offre una breve lista di tipi di trigger possibili tra cui scegliere. Ben integrati con il resto dei servizi presenti in Azure) =>
- Blob storage
- Cosmo DB
- Event Hubs
- Event Grid
- HTTP Request
- IOT Hub
- Dapr
- Kafka
- Mobile Apps
- Notification Hub
- Queue storage
- RabbitMQ
- SendGrid
- SignalR
- Table storage
- Esempi di ‘Function App’ =>
-
-
-
- Esempio 1
- Eseguire la funzione ogni 5 minuti (Timer trigger) e calcolare la somma di una colonna nel DB. Se supera una certa cifra, inviare un evento in EventGrid (Eventi Grid binding).
- Esempio 2
- Quando un messaggio arriva nella coda degli ordini (Queue trigger) salvarlo in Cosmo DB (Cosmo DB binding).
- Esempio 3
- Ricevere una HTTP Request. (HTTP trigger). Se questa richiesta contiene 4 numeri ritornarle il più piccolo (no binding).
- Esempio 1
- Linguaggi supportati =>
- C#
- Javascript (NodeJS)
- Java
- Python
- PowerShell
- F#
- Creare ‘Function App’ in Azure =>
- (Via Azure Portal) Per creare una routine è necessario indicare =>
- Lo stack a runtime (es: .NET o JAVA)
- L’ambiente di sviluppo
- Direttamente su Azure
- Vs Code
- Visual Studio
- (In Visual studio) Functions worker
- In-process o Isolated process (permette usare una verisone di .NET diversa da quella usasa dal processo host delle funzioni su Azure)
- L’evento che scatena l’esecuzione della routine
-
- HTTP
- Timer
- Azure Queue
- Blob storage
- (Via Cloud Shell) Per versioni trial non é possibile creare ‘Function App’ con la formula di pagamento ‘a consumo’
- Direttamente dal portale
- Tramite la ‘Cloud Shell’
-
//i seguenti esempi usano comandi bash (e non powershell) //Passo 1 - Creo un nuovo 'Storage Account' //il nome di uno 'Storage Account' (similarmente alle 'App Service') deve essere univoco in tutto Azure //il nome di uno 'Storage Account' può contenere solo lettere. >az storage account create <my-unique-storage-name> --location <my-region> --resource-group <my-resource-group> --sku standard_LRS //Passo 2 - Creo una 'Function App' e la associo allo 'Storage Account' appena creato //anche il nome di una 'Function App' deve essere univoco in tutto Azure >az functionapp create --name <my-unique-functionapp-name> --storage-account <my-unique-storage-name> --consumption-plan-location <my-region> --resource-group <my-resource-group> --functions-version 4 //Dopo aver eseguito i 2 passi, sul portale Azure, si ha una nuova 'Function App' vuota
- (Via Azure Portal) Per creare una routine è necessario indicare =>
- Eseguire una ‘Function App’ localmente =>
- E’ necessario installare sul proprio computer il ‘Azure Functions Core Tools’
- Se si usa VS Code allora bisogna installare l’extension ‘Azure Function’
- Dopo aver installato l’extension, aprendo il menù dedicato alle extension di Azure si vedrà un nuovo tab ‘Functions
- Si possono vedere le Azure ‘Function App’ presenti in Azure + quelle presenti in locale nel nostro progetto.’
- Ogni funzione è esposta ad un URL specifico (come le WebApi)
- Sarà quindi possibile testarle tramite un client come ‘Postman’.
-
-
- Fare l’upload della propria ‘Function App’ locale in Azure
- Seguire il passo descritto sopra (Creare una ‘Function App’ in Azure) per creare un ‘Function App’ vuota in Azure
- Usando VS Code e la ‘Azure Function’ extension è possibile semplicemente cliccando su ‘Deploy’ fare il deploy delle funzioni presenti in VS Code alla ‘Function App’ selezionata tra quelle presenti in Azure.
- Visitando la scheda della ‘Function App’ su Azure e aprendo nel menù ‘Functions’ sarà possibile vedere le ‘Function App’ appena deployate.
- Selezionare una funzione e cliccare su ‘Code + Test’
- Tramite ‘Get Function URL‘ recuperare l’URL associato alla funzione (<my-function-project>.azurewebsites.net/api/<my-function-name>).
- Testarlo tramite un client come ‘Postman’.
- Nella finestra in basso è possibile vedere i messaggi di log.
- local.settigs.json (Visual Studio)
- AzureWebJobsStorage
- Tutti i casi in cui trigger != HttpTrigger e’ necessario la configurazione per lo ‘storage account’ di default usato dalla funzione quando eseguita.
- Manage Azure App Service Settings
- Tramite questo menu é possibile gestire le stinghe di configurazione e connessione presenti nel file local.settigs.json che si voglio deployare in Azure
- AzureWebJobsStorage
- Diagnose and solve problems
- Questo menù permette di conoscere eventuali problemi e errori legati alle nostre function
- Ad esempio problemi di configurazione (ben parametrata in locale ma non rilasciata in Azure)
- Application Insights
- Questo menù permette fare delle query per riscontrare errori e malfunzionamenti
- Function access restriction
- Visualizza la ‘Azure Function’ di cui si vuole limitare l’accesso e aprire il menù=> Settings -> Networking => ‘Configure access restrictions’
- Aggiungere una nuova regola indicando il tipo di risorsa (autorizzata o bloccata) e la risorsa vera e propria.
- Esempio: autorizzare l’accesso alla funzione solo da un Event Grid
- servizio Type = servizio
- Service tag = ‘Azure Event Grid’
- ‘Durable Function‘ =>
- Sono funzioni stateful che interagiscono con risorse esterne e tangono traccia del flusso
- Nascondo la complessità di gestire lo stato, i retry..
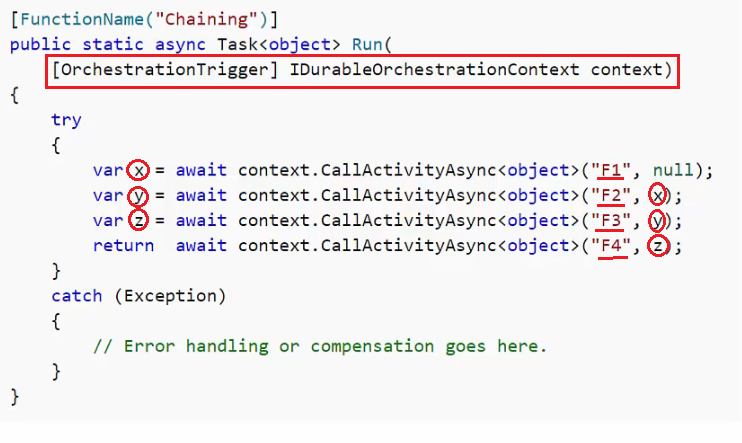
- Concatenamento di funzioni =>
- Le ‘Durable Function’ sono utili nel caso di concatenamento di funzioni dove la precedente passa l’output alla successiva.
- Ogni funzione è autonoma, interagisce con una sorgente dati con i propri tempi
- Fare l’upload della propria ‘Function App’ locale in Azure
-
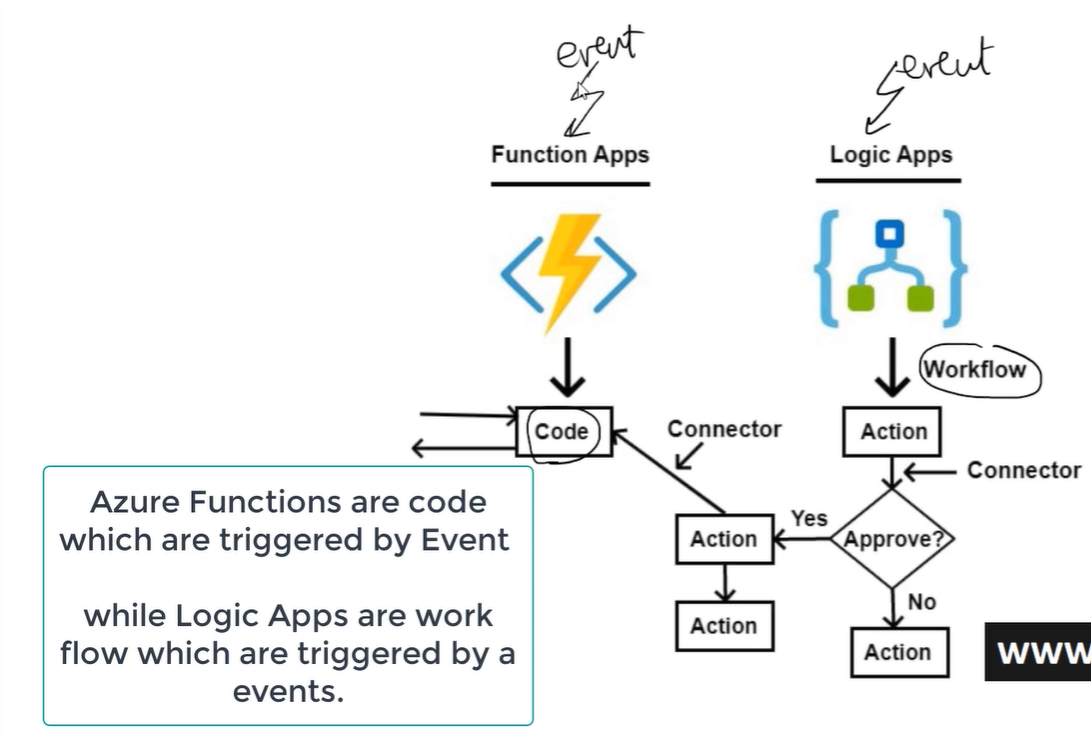
- Logic App vs Function App
- Le ‘Logic app’ sono dei completi workflow eseguiti a seguito di un dato evento e che interagisco con altri servizi.
- Le ‘function app’ sono delle routine eseguite a seguito di un dato evento.
- Logic App vs Function App
-
-
- Da una ‘Logic app’ è possibile richiamare una ‘Function app’
- Creare una ‘Logic App’ =>
- Loggarsi al portale Azure
- Decidere il tipo di trigger (es: una richiesta HTTP)
- Aggiungere gl step voluti per creare il workflow desiderato
-
- Altri tipi di ‘Compute Services’
- ACI (Azure Container Instance)
- Se si vuole deployare un solo container (es: docker) senza il bisogno della complessità di Kubernetes.
- App Service Container
- Serve per fare il deploy di un container docker in un ‘App Service’ (e non direttamente del codice, come visto sopra)
- ACI (Azure Container Instance)
Azure Data Services (Azure Sql, DB on VM, Azure Storage, Cosmo DB)
- Cosa è?
- Azure fornisce molte soluzioni dati in qualità di servizio cloud (es: DB relazionali, NoSQL Db, Object stores).
- Tutte le soluzioni sono completamente gestite (fully managed) da Azure (non è necessario e possibile accede ai sistemi sottostanti).
- Tali soluzioni possono essere parte di altre ‘Azure App’ o completamente indipendenti.
- Sono forniti diversi modelli di prezzo
- Come scegliere il miglior servizio dati per noi?

- DB on VM (not managed service) =>
- In Azure è comunque possibile scegliere di non usare i servizi gestiti pensati per i dati ma ospitare un’istanza del DB scelto direttamente in un VM (virtual machine).
- Vantaggi e svantaggi
- La piena flessibilità di poter Installare ciò che si vuole e configurare il server come si vuole è un vantaggio ma può portare con se anche molti svantaggi in quanto cadranno su di noi tutte le responsabilità di una buona gestione della DB (SLA, Update, Availability, Security, Backups…)
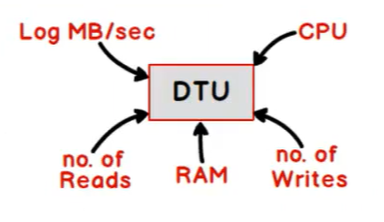
- DTU (Database transaction units) => .
- E’ usato da Azure per calcolare il costo del servizio per storare un RDBMS
- E’ una misura per garantire le performance per quella data configurazione
- E’ dato da diversi indici di utilizzo:
- Il numero di letture
- Il numero di scritture
- L’uso della RAM in Giga
- La % d’uso della CPU
- La quantità di dati nei log files
-
-
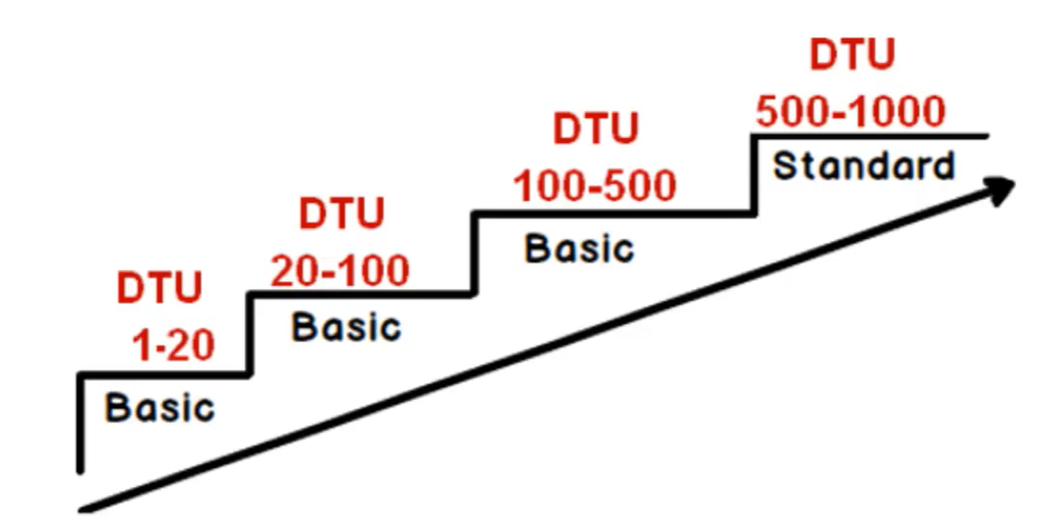
- Si parla di DTU quando si vuole cifrare le risorse da allocare a 1 e un solo DB
- EDTU => Se si parla quando le risorse allocate sono intese per 2 o più DB
-
-
- Azure SQL Database DTU Calculator =>
- In questo sito si trova una utility per permettere il calcolo della DTU necessaria alle proprie esigenze
- sqldtuperfome.exe =>
- Utilizzare questa applicazione scaricabile dal sito e configurabile (file config) per
- misurare l’utilizzo delle risorse da parte del mio attuale DB
- avere un file .csv che tali misure da uploadare sul sito e avere il calcolo delle DTU necessaria
- Utilizzare questa applicazione scaricabile dal sito e configurabile (file config) per
- Azure SQL Database DTU Calculator =>
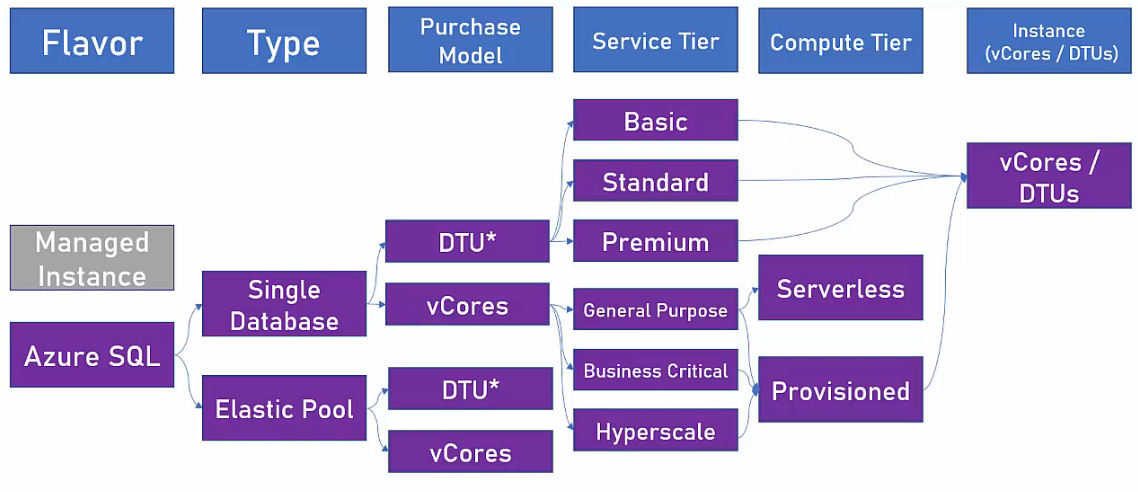
- Azure SQL =>
- Managed SQL Server in Azure.
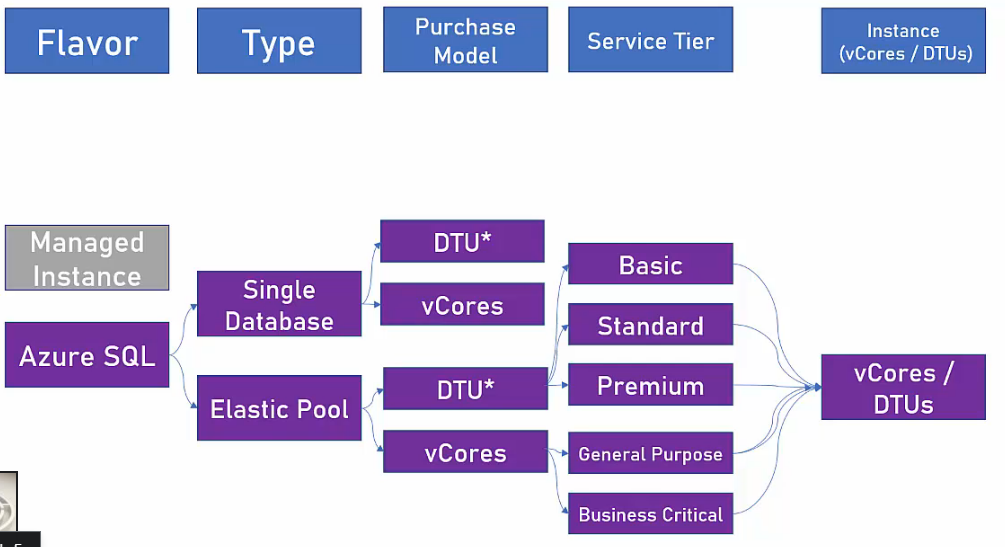
- Azure SQL Flavors (Azure offre una gamma flessibile di prezzi) =>
- Azure SQL Database
- 1 DB in 1 server.
- Backup, Update, Scaling automatici
- Buona compatibilità con le versioni in SQL Server installate in locale (sulle proprie macchine nella propria sede).
- Non tutte le funzionalità di un’istanza SQL Server classica sono supportate.
- Security
- IP Firewall (solo le richieste che arrivano dagli IP specificati sono accettate).
- Autenticazione tramite Sql & Azure Active Directory (AD)
- Secure comunication (TLS)
- Dati criptati (TDE)
- Backup
- Full => Ogni settimana.
- Differential => Ogni 12/24 ore.
- Transaction log => Ogni 5/10 minuti.
- Availability
- SLA: 99,9% – 99.995 %
- Compute tiers
- Provisioned =>
- Si paga in funzione delle risorse allocate (e non del traffico prodotto).
- Reservation-feature: è possibile pagare meno se si paga per un abbonamento che dura di più.
- Serverless =>
- Si paga solo per l’uso (numero di core e RAM).
- Se il DB non è usato per esempio la notte. In quel caso si pagarà solo per lo ‘Storage’.
- Esiste un piccolo ritardo alla partenza (non essendoci una risorsa dedicata sempre accesa, come nel caso delle ‘Function App’).
- Reservation-feature non è possibile.
- Provisioned =>
- Azure SQL Database
-
-
- Elastic pool
- Molti DB in 1 server.
- E’ adatto a DB basso carico e poche punte di traffico.
- Le altre caratteristiche riprendo il caso ‘Azure SQL Database’.
- E’ molto conveniente => Si acquista le risorse di cui si ha bisogno e non l’intero DB.
- Elastic pool
-
-
-
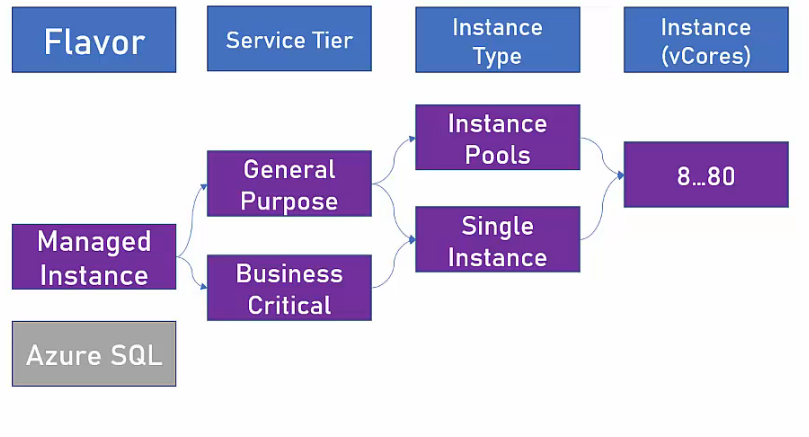
- Managed Instance
- Condivide quasi il 100% delle caratteristiche e possibilità offerte da una normale installazione di SQL Server in un server locale.
- Può essere deployato in VNet.
- La geo replicazione non è attiva.
- L’auto-scaling non è attivo.
- SLA: 99.99%.
- Può esseguire codice CLR.
- Non è attiva la ‘Availabilty Zone’
- Managed Instance
-
-
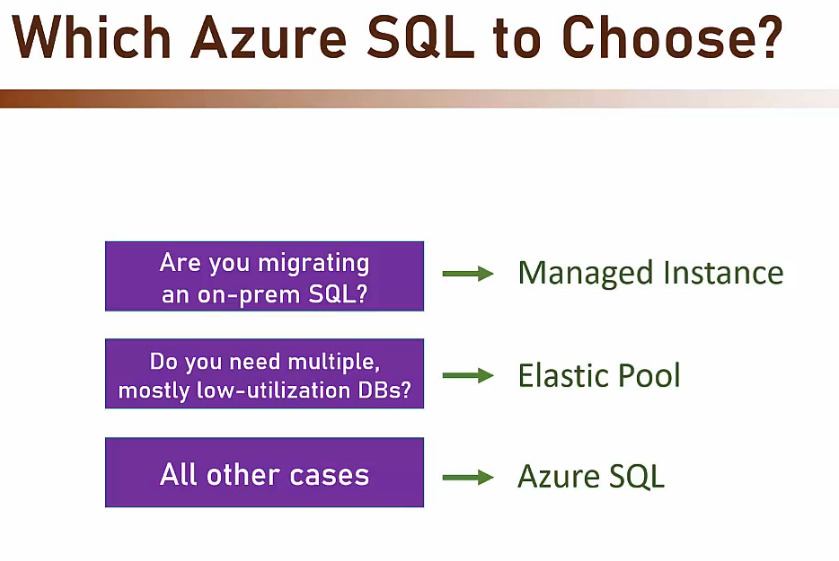
- Quale Azure SQL scegliere?
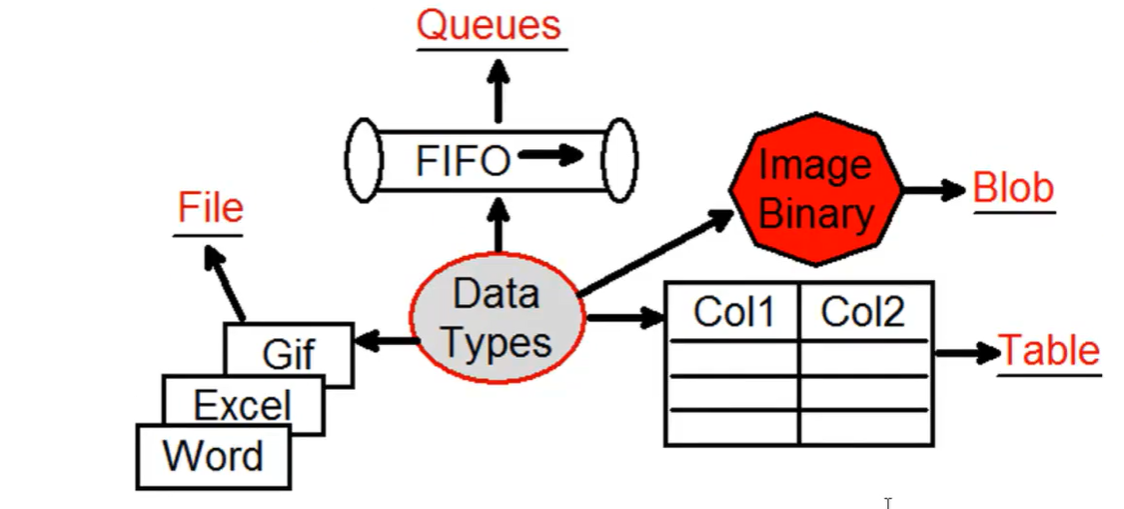
- Azure Storage =>
- Storage account =>
- Per aggiungere dati (storage) in Azure creare un storage account
- E’ molto economico
- Definire il tipo di dato =>
- Account kind => scegliere il tipo di dato (es: file, blob, queue, table)
- Storage account =>
-
-
- Definire il tipo di device => Scegliere tra normali (HDD) e dischi allo stato solido (SDD)
- Tale scelta influenzerà la performance
- Definare la politica di disaster recovery e backup
- Locally-redundance storage (LRS) => sono creati 3 backup nello stesso data-center
- Zone-redundance storage (ZRS) => specializzato per dati blob
- Geo-redundance storage (GRS) => sono creati 3 backup localmente (come in LRS) e 3 backup in un data-center geograficamente dislocato.
- A volte la creazione di uno ‘Storage account’ è trasparente all’utente finale che richiede un determinato servizio
- Database backups
- VM Disks
- Diagnostics data
- Aggiungere dati =>
- Una volta creato un storage è possibile aggiungervici i dati
- Blob => aggiungere un container poi a tale container aggiungervici i file desiderati (immagini, exe)
- Una volta creato un storage è possibile aggiungervici i dati
- Microsoft Azure Storage Explorer =>
- Client per accedere e interagire con gli storage creati in Azure
- Aggiungere un account (connettersi allo storage desiderato)
- Definire il tipo di device => Scegliere tra normali (HDD) e dischi allo stato solido (SDD)
-
- Azure Storage – Azure Table =>
-
- In Visual Studio usare il ‘Cloud Explorer’ per navigare attraverso gli elementi presenti nel proprio account Azure.com
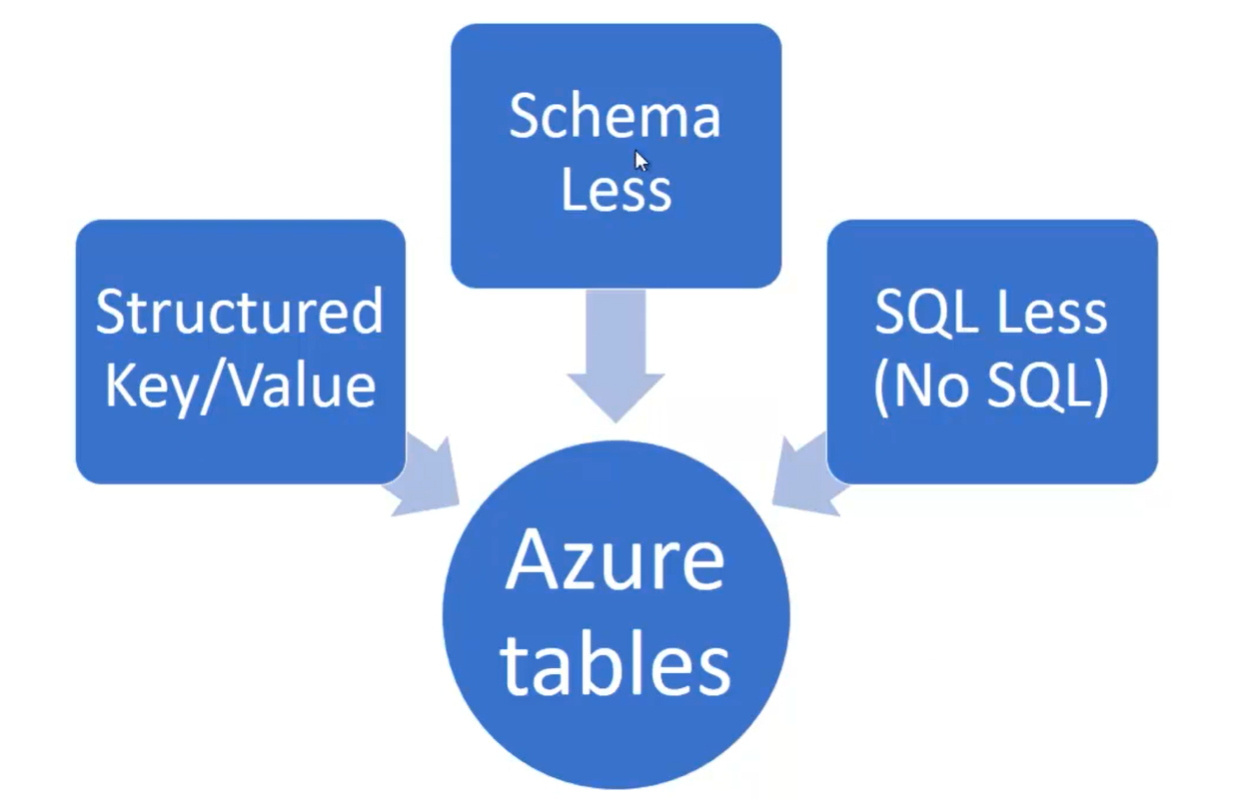
- Azure table =>
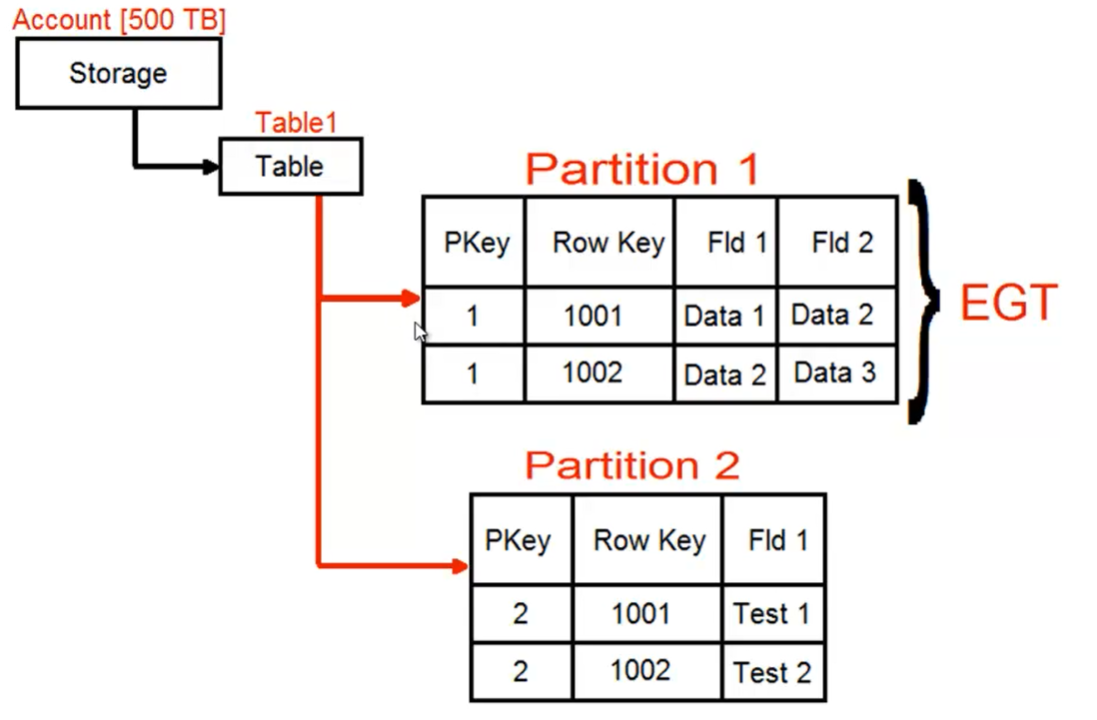
- Una table è in realtà l’equivalente di un database dei RDBMS classici
- Default properties => Ogni dato aggiunto ad una table ha queste 3 proprietà automaticamente
- PartitionKey (es: Dottori)
- RowKey (es: Dottore 1, Dottore 2)
- Timestamp
- Una table può ospitare molte partitions (le vecchie tabelle)
- Sono schemaless
- Hanno partitions che ospitano coppie chiave-valore
- Azure partition =>
- Una partition è l’equivalente di una tabella dei RDBMS classici
- Una partition può ospitare molti tipi diversi di dati
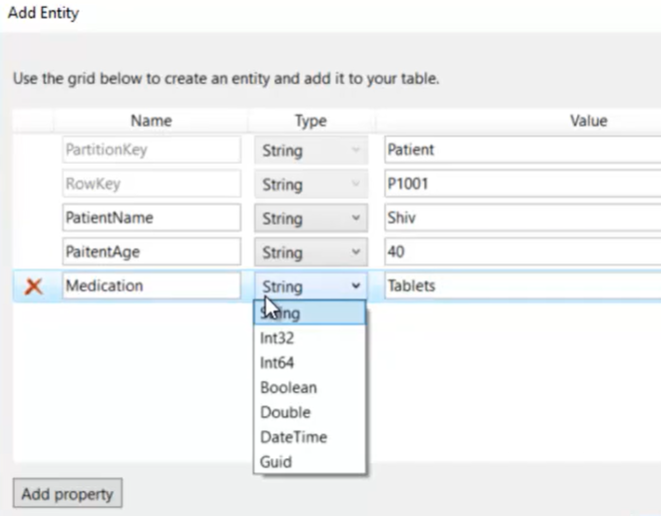
- Esempio aggiunta di un nuovo ‘paziente’ =>
-
-
- Esempio aggiunta di un nuovo ‘dottore’ =>
-
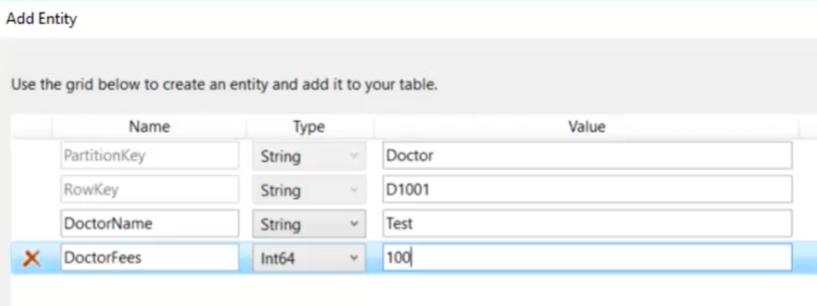
-
- Transazioni => possono essere gestite solo all’interno di una partition
- C# =>
- Installare tramite nuget il package WindowsAzure.storage
- Creare delle classi che mappino le partitions presenti nell’Azure Table che si vuole leggere =>
-
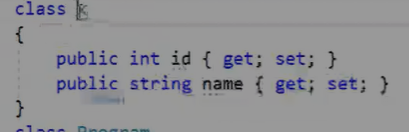
class Patient: TableEntity { public string PatientName {get; set;} public string PatientAge {get; set;} public string Medication {get; set;} }
-
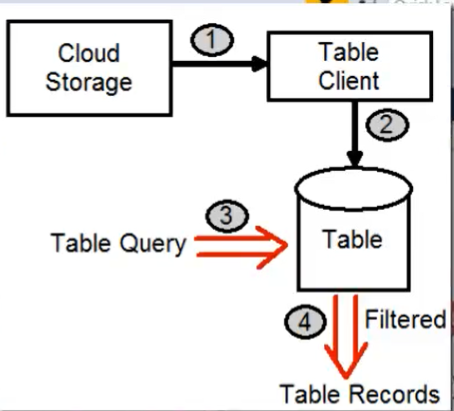
- Leggere i dati =>
- Recuperare (n Azure.com menu ‘Storage’ => select ‘My Storage’ => ‘Access Key’) la chiave di accesso allo ‘storage’
-
static void Main(string[] args) { //Step 0 - Recuperare la chiave di accesso 'Access Key' per connettarsi allo 'storage' //Step 1- Creare la connessione allo storage CloudStorageAccount storageAccount = CloudStorageAccount.Parse("my access key"); //Step 2 - Crea un'istanza del Table client CloudTableClient tableClient = storageAccount.CreateCloudTableClient(); //Step 3 - Accedere alla 'table' desiderata CloudTable myTable = tableClient.GetTableReference("MyTable"); //Step 4 - Leggere i dati di una partition della table 'MyTable' //recupero tutte le righe di tipo 'patient' TableQuery<Patient> myQuery = new TableQuery<Patient>(). Where(TableQuery.GenerateFilterCondition("PartitionKey", QueryComparisons.Equal,"Patient")); //ciclo la collezione di 'Patient' foreach(Patient item in myTable.ExecuteQuery<Patient>(myQuery)) { Console.WriteLine(item.PatientName); Console.WriteLine(item.Medication); } Console.Read(); }
-
-
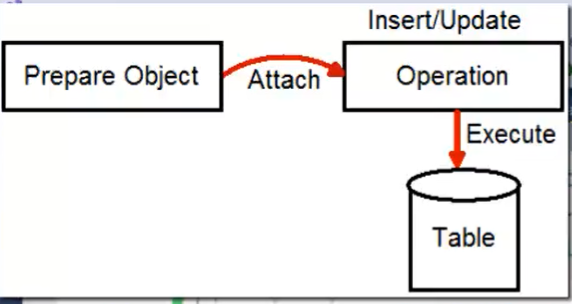
- Inserire/Modificare/Eliminare dati =>
-
//Step 0 - come 'lettura' //Step 1 - come 'lettura' //Step 2 - come 'lettura' //Step 3 - come 'lettura' //Inserimento //Step 4 - Preparare l'oggetto da inserire Patient newpat = new Patient(); newpat.PartitionKey = "Patient"; newpat.RowKey = "P2002"; newpat.PartitionName = "Radu"; newpat.PartitionAge = "40"; newpat.Medication = "Tablets"; //Step 5 - Legare tale oggetto all'operazione di inserimento TableOperation insertOper = TableOperation.Insert(newpat); //Step 6 - Eseguire tale operazione nell'istanza 'table' myTable.Execute(insertOper); oppure //Modifica/Eliminazione //Step 4 - Recuperare l'oggetto da modificare/eliminare TableOperation retreiveOperation = TableOperation.Retreive<Patient>("Patient", "P2002"); TableResult retreivedResult = table1.Execute(retreiveOperation); Patient patientP2002 = (Patient)retreivedResult.Result; //Step 5 - Modificare l'oggetto patientP2002.PartitionAge = "41"; //Step 6 - Legare tale oggetto all'operazione di update (o delete) TableOperation updateOper = TableOperation.Replace(patientP2002); TableOperation deleteOper = TableOperation.Delete(patientP2002); //Step 7 - Eseguire tale operazione nell'istanza 'table' myTable.Execute(updateOper);
-
- Inserire/Modificare/Eliminare dati =>
-
-
-
- TableBatchOperation =>
- E’ possibile eseguire le operazioni in batch
- TableBatchOperation =>
- Best Practices =>
- Impostare sempre PartitionKey e RowKey quando si vogliono leggere dati da una ‘table’ per non rallentarne la lettura evitando un ‘Azure Table scan’:
-
TableQuery<Patient> myQuery = new TableQuery<Patient>(). Where( TableQuery.CombineFilters( TableQuery.GenerateFilterCondition("PartitionKey", QueryComparisons.Equal, "Patient"), TableOperators.And, TableQuery.GenerateFilterCondition("RowKey", QueryComparisons.Equal, "P2002") ) );
-
- Duplicare i dati (per inserire diffenti keys) o per creare viste con dati aggregati =>
- Cambiare il mind-set rispetto al backgrond maturato con gli RDBMS =>
- E’ normale duplicare i dati creando dello stesso dato più righe con dei valori di ‘RowKey’ differenti
- Ciò permette di velocizzare le operazioni di lettura (fornendo la coppia ‘PartitionKey’, ‘RowKey’)
- Impostare sempre PartitionKey e RowKey quando si vogliono leggere dati da una ‘table’ per non rallentarne la lettura evitando un ‘Azure Table scan’:
-

-
-
-
- Una volta duplicato i dati bisogna ricordarsi di propagare le modifiche sui dati duplicati.
- Compound keys =>
- Creare delle chiavi che siano combinazioni di 2 o più chiavi
- al fine di rendere più veloce la ricerca dei dati
- al fine di creare diverse viste dei dati
- Creare delle chiavi che siano combinazioni di 2 o più chiavi
-
-

-
-
- Evitare di creare hot partition =>
- Evitare di creare una partition sia sovraccaricata (superi il limite di memoria) di ricerca => dividere tali dati in più ‘partitions’
- Evitare di creare ‘azure table’ non necessarie =>
- Per poter creare un batch di operazioni in una sola transazione (EntityTransactionGroup)
- Se si splittano i dati su iù ‘azure table’ non sarà possibile gestire la transazione.
- Evitare di creare hot partition =>
- Azure table desing pattern =>
- Intra-partition pattern =>
- Nella stessa partizione differenziare i dati (per poter fare 2 o più ricerche sugl stessi dati) tramite la ‘RowKey’
- Se si vuole creare la possibilità di ricercare gli stessi dati per 2 chiavi diverse duplicare i dati come mostrato di seguito
- Intra-partition pattern =>
-

-
-
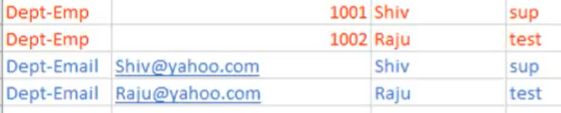
- Iter-partition pattern =>
- Se si vuole duplicare i dati per fornire più chiavi di ricerca farlo creando più ‘partitions’
- Iter-partition pattern =>
-
-
-
- Delete-partition pattern =>
- Il nome della partition deve avere anche una parte di dati
- Utile nel caso si abbiano bulk-delete e poche ricerche sui dati
- Delete-partition pattern =>
-

-
-
- Optimistic locking =>
- Usa il campo timestamp per implementare una politica di optimistic locking’
- Optimistic locking =>
-
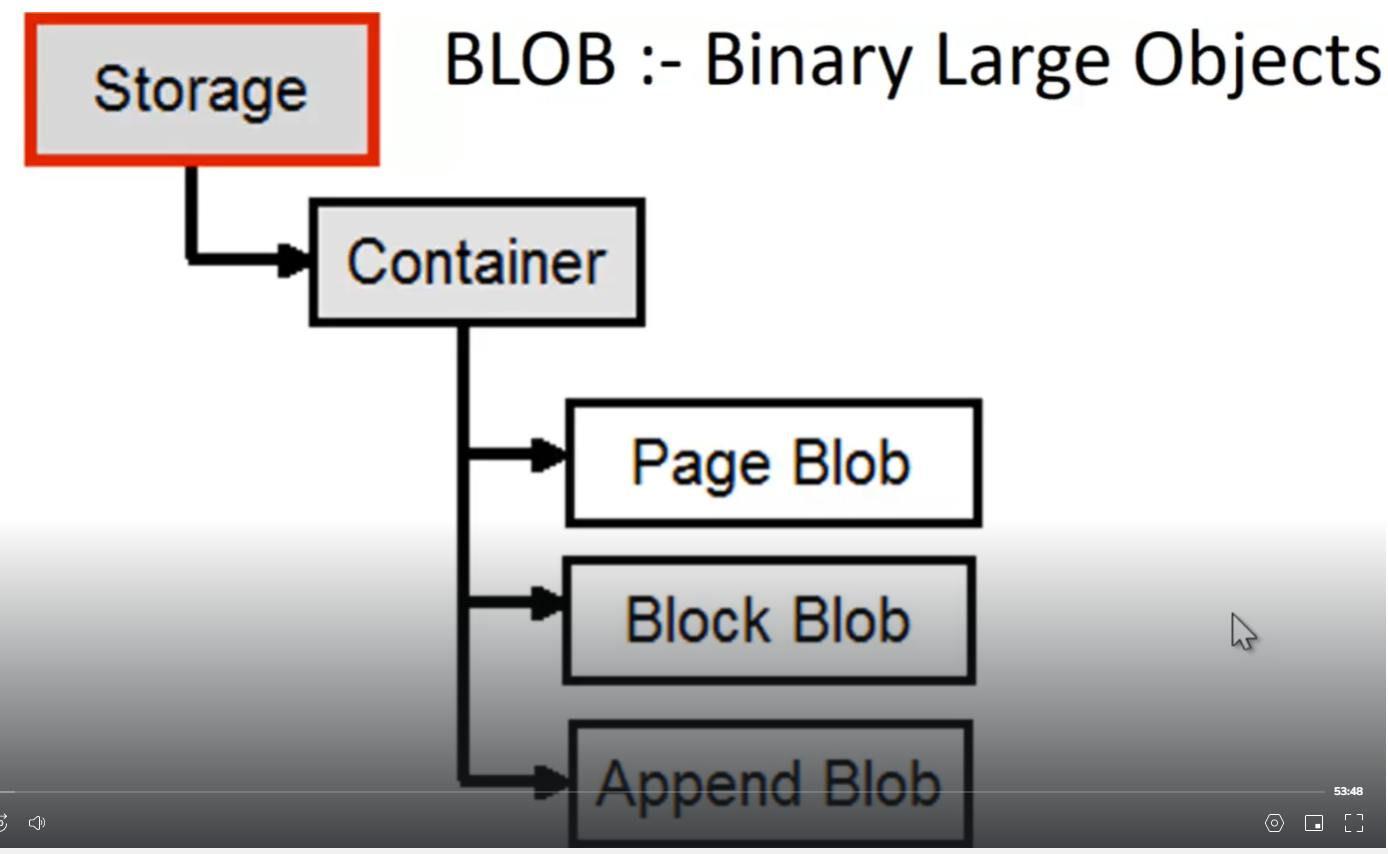
- Azure Storage – Blob =>
- Nuget => In Visual Studio aggiungere la referenza al package WindowsAzure.Storage
- Creare un account storage =>
- Creare un container =>
- Scegliere il tipo di blob =>
- Caricare il dato
- Scegliere il tipo di blob =>
- Creare un container =>
-
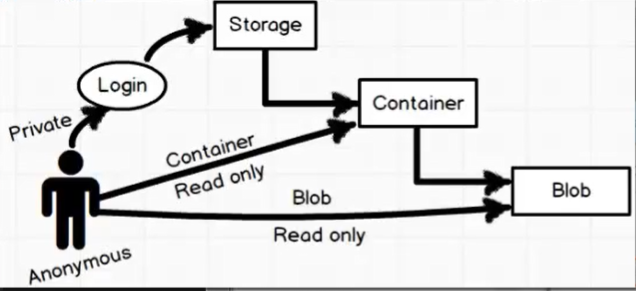
- Public access level =>
- Private
- Anonymous blob
- Anonynous container and blob
- Public access level =>
-
- Tipi di blob in funzione dell’operazione che si vuole effettuare =>
-
-
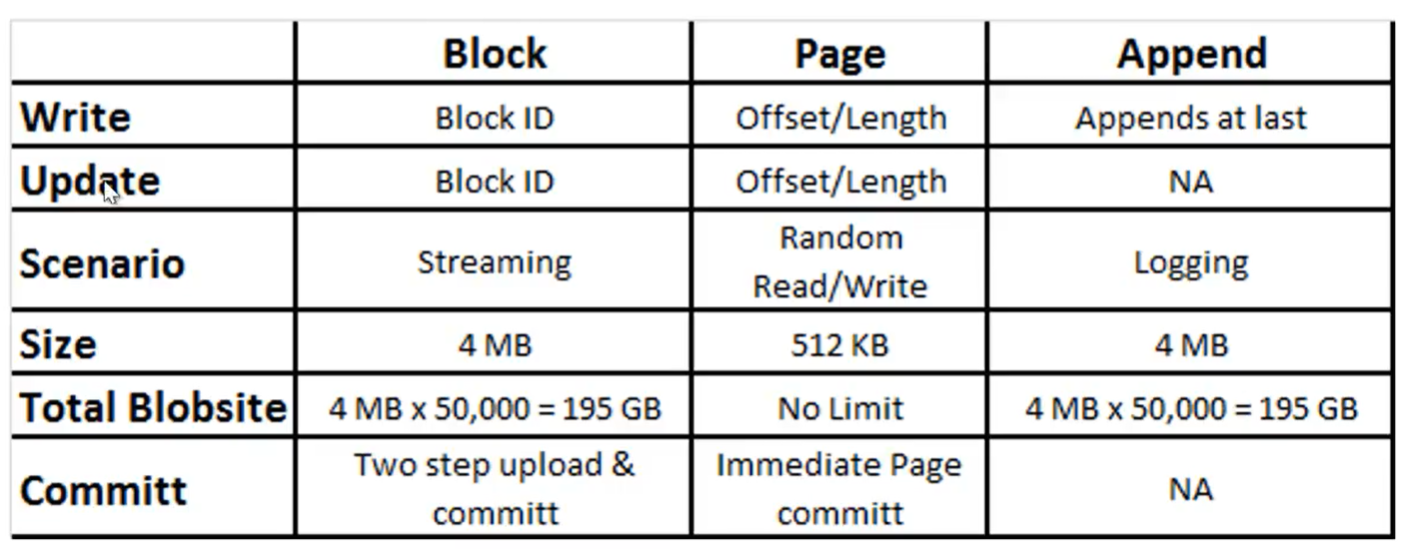
- Block Blob =>
- Un’oggetto di tipo blob (es: un grosso file) può essere gestito nella sua interezza oppure suddiviso in blocchi (4Mb) con ognuno un ID
- E’ molto indicato per lo streaming
- Totalsize => Un oggetto blob è contenuto in un container è può essere grandezza massima 195GB
- Caricato in Azure.com in una sequenza aleatoria
- Quando viene memorizzato viene ripristinato l’ordine originario
-
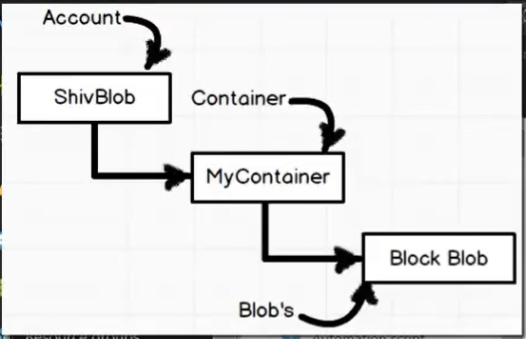
//Esempio upload file PDF (ebook.pdf) //Step 0 - Recuperare la connection string //Normalmente si mette la stringa di connessione in un file config e la si legge da lì Dal menu dello storage account aprire 'Access keys' e recuperare la 'connnectionString' //Step 1 - Connettersi allo 'stoage account' CloudStorageAccount storageAccount = CloudStorageAccount.Parse(@"connection string... AccountName=ShivBlob"); //Step 2 - Instanziare il BlobClient CloudBlobClient blobClient = storageAccount.CreateCloudBlobClient(); //[Step 2A - Opzionale] Dichiaro di suddividere il caricamento del blob in chunks blocClient.DefaultRequestOptions = new BlobRequestOptions() { //1MB, divido il blob in chucks a partire dalla dimensone totale del blob di 1MB SingleBlobUploadThresholdInBytes = 1024*12024; ParallelOperationThreadCount = 1 } //Step 3 - Dal BlobClient ottenere un' istanza del 'container' CloudBlobContainer container = blobClient.GetContainerReference("MycCntainer"); //Step 4 - Dal 'container' ottenere un'instanza di 'BlockBlob' CloudBlockBlob blockBlob = container.GetContainerReference("EbookBlob"); //[Step 4B- Opzionale] - posso indicare la dimensione dei chunk //By default = 4MB blockBlob.StreamWriteSizeInBytes = 1024 * 1024; //1MB //Step 5- Upolad un file PDF blockBlob.UploadFromFile(@"c:\ebook.pdf"); //E' possibile creare i blocchi manualmente (PutBlob, PutBlobList)
- Append Blob =>
- Adatto per loggare informazioni
- Totalsize => 195GB
-
//Step 0 - Come caso 'Block blob' //Step 1 - Come caso 'Block blob' //Step 2 - Come caso 'Block blob' //Step 3 - Come caso 'Block blob' //Step 4 - creo un append Blob CloudAppendBlob appendBlob = container.GetAppendBlobReference("myblobapp"); if(!appendBlob.Exists){ //Creo un container di tipo Append blob appendBlob.CreateOrReplace(); } appendBlob.AppendFromFile(@"c:\file1.txt"); appendBlob.AppendFromFile(@"c:\file2.txt");
- Page Blob =>
- Adatto per operazioni di lettura, scrittura randomiche
- Voglio creare un blob che è la concatenazione di 2 file Hello1.txt e Hello2.txt più 512KB vuoti.
- Totalsize => No limit
- Block Blob =>
-

-
-
-
-
//Step 0 - Come caso 'Block blob' //Step 1 - Come caso 'Block blob' //Step 2 - Come caso 'Block blob' //Step 3 - Come caso 'Block blob' //Step 4 - creo un page blob CloudPageBlob pageBlob = container.GetPageBlobReference("mypageblob"); if(!pageBlob.Exists) { pageBlob.Create(3*512); //creo 3 pagine vuote di 512KB l'una } //Primi 512KB byte[] ba = new byte[512]; MemoryStream m = new MemoryStream(); FileStream fs = new FileStream(@"c:1\file1.txt", FileMode.Open); fs.read(ba,0, 512); m = new MemoryStream(ba); pb.WritePages(m, 0); //Secondi 512KB fs = new FileStream(@"c:1\file2.txt", FileMode.Open); fs.read(ba,0, 512); m = new MemoryStream(ba); pb.WritePages(m, 512); //Ultimi 512KB
-
-
-
- Azure Storage – Azure queue =>
- Nuget => In Visual Studio aggiungere la referenza al package WindowsAzure.Storage
- Il primo obbiettivo di utilizzare un sistema di code è disaccoppiare 2 sistemi
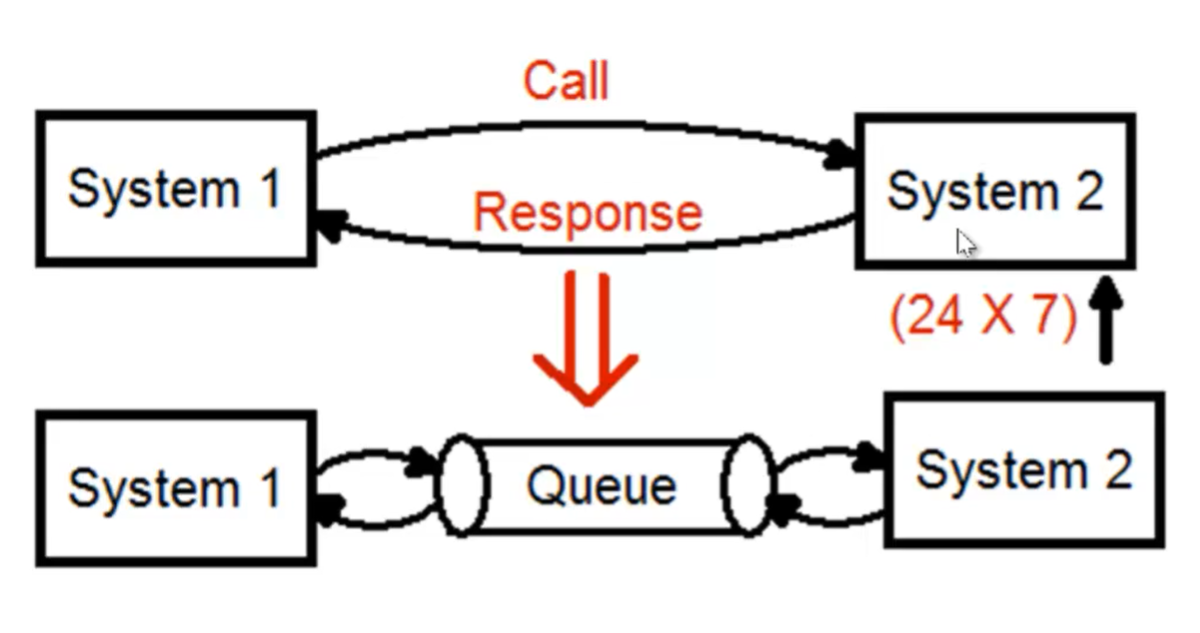
-
- Un sistema di code è gestito secondo una logica FIFO => Ciò che viene scritto per primo, viene letto per primo
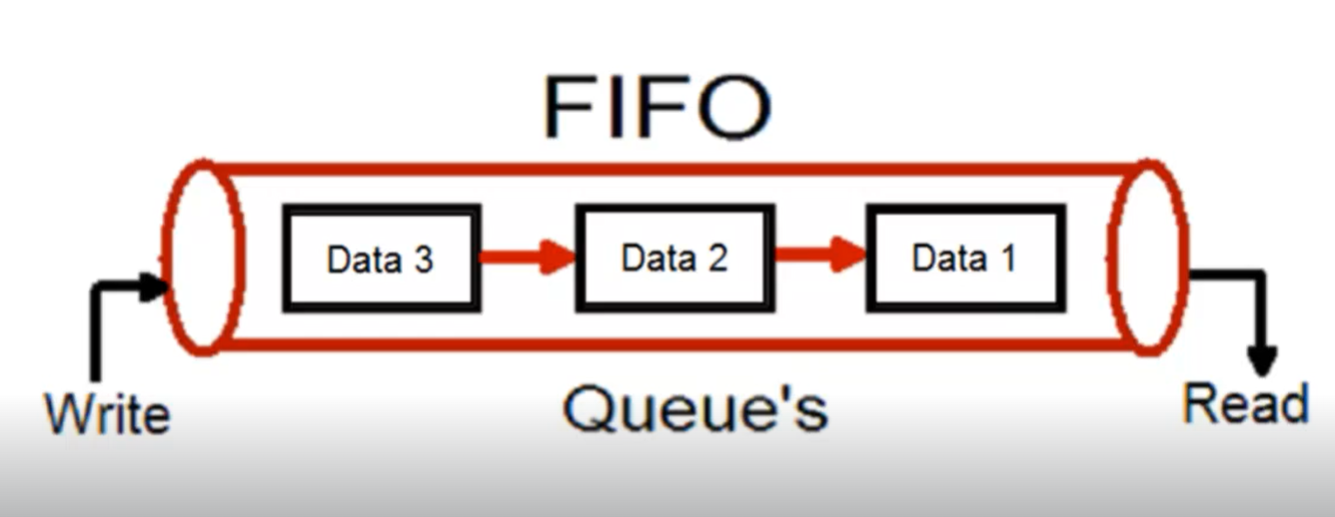
-
- Come creare una ‘queue’ =>
- Creare uno ‘storage account’
- Creare una ‘queue’
- Aggiungere messaggi
- Creare una ‘queue’
- Creare uno ‘storage account’
- Leggere dati in una ‘queue’ =>
- Come creare una ‘queue’ =>
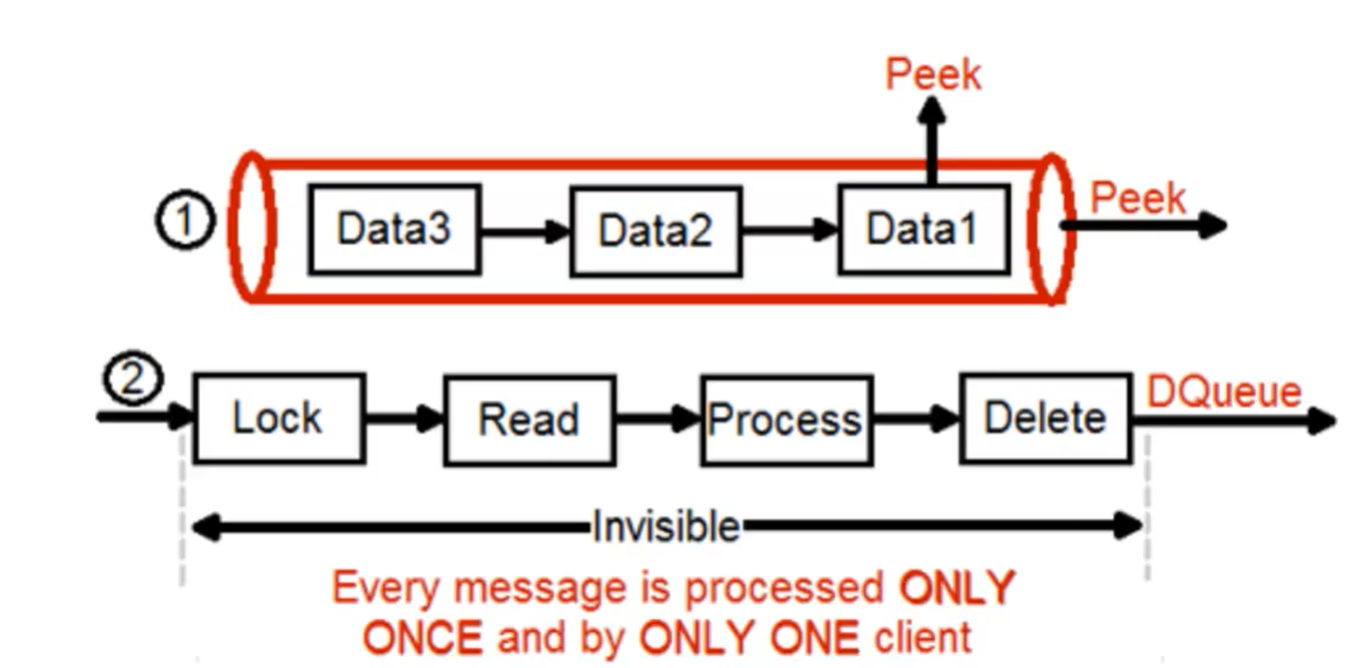
-
-
- Peek =>
- Leggere senza processare i dati
- Ogni messaggio può essere processato più volte, finché è disponibile
- Per leggere il secondo dato, devo eliminare il primo dato (ho finito di processarlo) che trovo nella coda
- DQueue => Leggere processando i dati
- Ogni messaggio è processato solo 1 volta da 1 solo client
- Peek =>
-
- Cosmo DB
- Cosa è =>
- E’ una database no-sql fully managed
- JSon DB , NO SQL => I dati immagazzinati sono in formato JSON
- Performance => Eccellenti (<10ms per quasi il 99% delle operazioni)
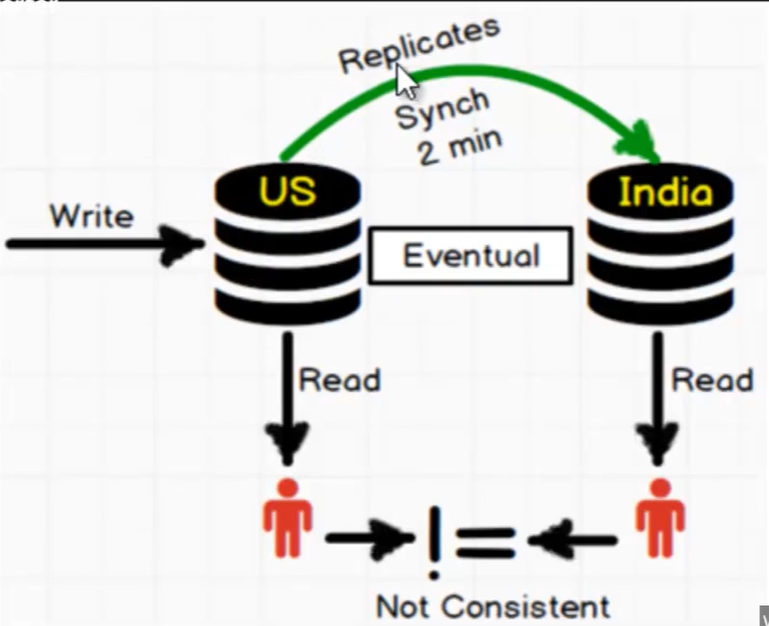
- Globally distribuited =>
- Planet scale => promette di limitare la latenza creando una ridondanza di DB in lettura geograficamente dislocati
- Pirmary DB => E’ il DB usato norlmalmente per aggiungere e togliere dati
- Secondary DB => Sono delle ‘fresh copy’ (continuamente aggiornate) del ‘primary DB’ dislocate più vicino agli utenti nel mondo
- Consistency issue =>
- C’è un momento (prima che la sincronizzazione finisca) in cui i dati del ‘primary Db’ e dei ‘secondary DB’ non coincidono
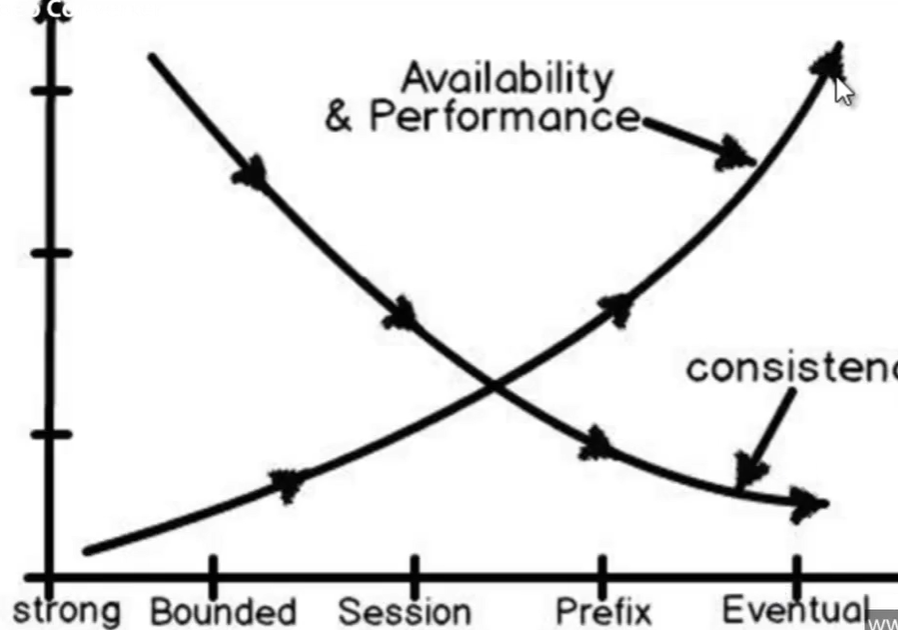
- Strong consinstency (only committed) =>
- I nuovi dati sono visibili ai ‘secondary DB’ solo quando il commit si è propagato a tutti i db secondary.
- Eventual consistency =>
- I nuovi dati sono visibili appena possibile (senza nessun meccanismo di sincronizzazione tra db secondary)
- Bounded, session, prefix =>
- Esistono delle politiche intermedie tra i 2 estremi
- Cosa è =>
-
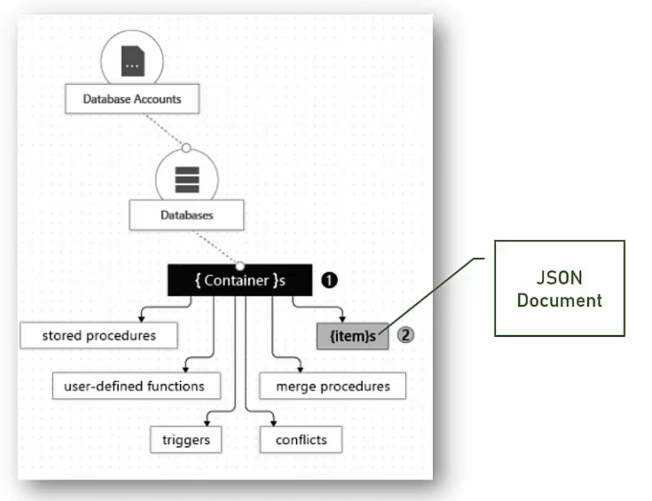
- Hierarchical DB =>
- Creo un ‘Cosmo Db Account’
- Creo un nuovo ‘Database’ = >
- Inserisco molte ‘Collection’ (=> le vecchie tabelle di un DB relazionale) =>
- Documents => In ogni collezione inserisco i dati divisi in ‘Documents’ di formato JSON (=i singoli record di un DB relazionale)
- Partition =>
- I documenti possono essere ragruppati in ‘partizioni’ logiche in base al valore di una particolare proprietà dei documenti stessi.
- La proprietà scelta per fare delle ‘partition’ non puo’ essere modificata
- Dati bilanciati => Le ‘partition’ dovrebbero sparti
- Lo scaling funiona a livello di ‘partition’
- Inserisco molte ‘Collection’ (=> le vecchie tabelle di un DB relazionale) =>
- Creo un nuovo ‘Database’ = >
- Creo un ‘Cosmo Db Account’
- Hierarchical DB =>
-
- Consistency level
- Replicate data globally =>
- In questo menu posso settare il livello di consistenza desiderato
- Tipi di consistenza
- Strong
- Comportamento quanto possibile simile a i classici DB relazionali
- Eventual
- Comportamento simile ad altri db NoSql
- Strong
- Replicate data globally =>
- Creare un nuovo Cosmo DB =>
- Crere un ‘Azure Cosmo DB Account’
- Selezionare quali API utilizzare (scegliere quale sintassi si preferisce per interrogare i dati che verranno inseriti nel nuovo Cosmo DB)
- SQL Api
- Mongo Api
- Graph Api
- Cassandra
- Table Api
- Capacity Mode
- Networking (private o public o entrambi)
- Backup policy
- Selezionare quali API utilizzare (scegliere quale sintassi si preferisce per interrogare i dati che verranno inseriti nel nuovo Cosmo DB)
- Crere un ‘nuovo container’ (e il suo database)
- Cliccare su ‘Data explorer‘ => Crere su ‘New Container’
- Database Id
- Indicare un database esistente o aggiungerne uno (es: myapp-orders)
- Container Id
- Partition Key (es: /priority)
- Database Id
- Cliccare su ‘Data explorer‘ => Crere su ‘New Container’
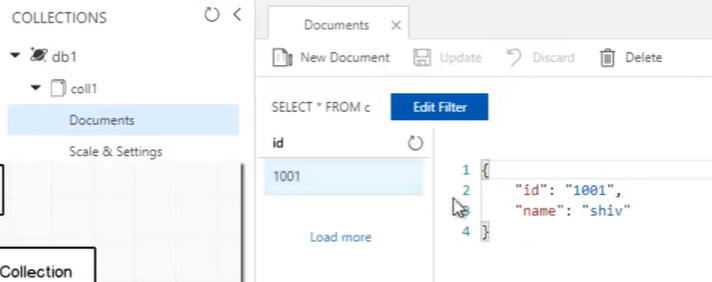
- Aggiuntere item
- Cliccare su ‘Data explorer’
- Selezionare il container desiderato
- Cliccare su ‘New Item’
- Inserire il JSON con i valori dell’item
- Azure Csomo Db agiunge dei campi di sistema ai nostri
- Crere un ‘Azure Cosmo DB Account’
- Aprire il menu ‘Keys’
- Cosmo Db URI => https://<my-cosmodb-name>.documents.azure.com:443/
- Primary connection string
- Secondary connection string
- Esempio di query
-
SELECT * FROM orders o WHERE exists ( select value n from n in o.items where n.name = 'Rama II')
-
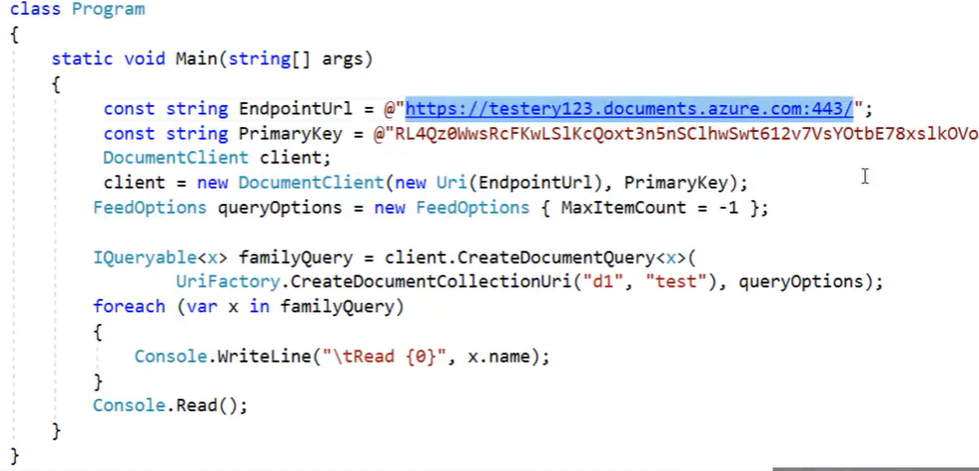
- Connettersi a Cosmo DB in C# =>
- Il codice seguente permette di collegarsi all’istanza del CosmoDB
- Leggere dal database ‘db1’ la collezione ‘test’
- La classe x definita in c# rispecchia il formato dati presenti nei ‘documents’ della collezione ‘test’
- Consistency level
Azure Fabric
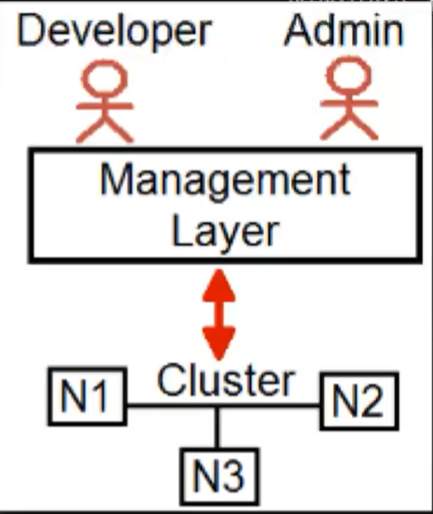
- Per implementare il pattern Microservice si avranno molte unità indipendenti eseguite da processi diversi su computer diversi oppure in container presenti in un solo computer
- Si finisce per avere una struttura complicata, un cluster di computer in cui bisogna:
- Gestire in sicurezza il livello di comunicazione (http) tra nodi (computer, VM, container) del cluster
- Gestire il deploy automatico in sicurezza
- Monitorare il deploy
- Gestire i failure (rotture di un nodo)
- Azure Fabric =>
- implementa un livello di gestione tra i microservizi e l’infrastruttura cluster
- Microsoft dà la possibilità di usare Azure Fabric in locale per sviluppare e testare e solo in ultimo deploiare su Azure.com e quindipagare
- Azure Fabric SDK => Aggiunge i progetti necessari in Visual Studio
- Service Fabric Application =>
- Statefull Azure application =>
- permette in caso di failure di riavere la stessa situazione su un altro nodo.
- viene creato un statemanager dictionary per gestire la ‘statefullness’
- un’applicazione ‘statefull’ è normalmente deploiata su più nodi del nostro cluster appunto per poter gestire il mantenimento di stato in caso di cambio nodo
- Stateless Azure application =>
- non permette di mantenere lo stato dell’applicazione in caso di rideploy in un altro nodo a seguito di un guasto o di uno spegnimento.
- un’applicazione ‘stateless’ è normalmente deploiata su 1 nodo solo.
- E’ normalmente divisa in 2 progetti:
- Uno per configurare il deploy nel cluster (deve essere il progetto di startup)
- Uno per ospitare la logica vera e propria
- Quando l’applicazione è deploiata online (su Azure.com) un nodo non corrisponde a un computer/container ma piuttosto a un set di computer/container
- Statefull Azure application =>
- Service Fabric Application =>
- Azure Fabric Explorer => Permette di gestire il cluster in locale
- Azure Fabric SDK => Aggiunge i progetti necessari in Visual Studio
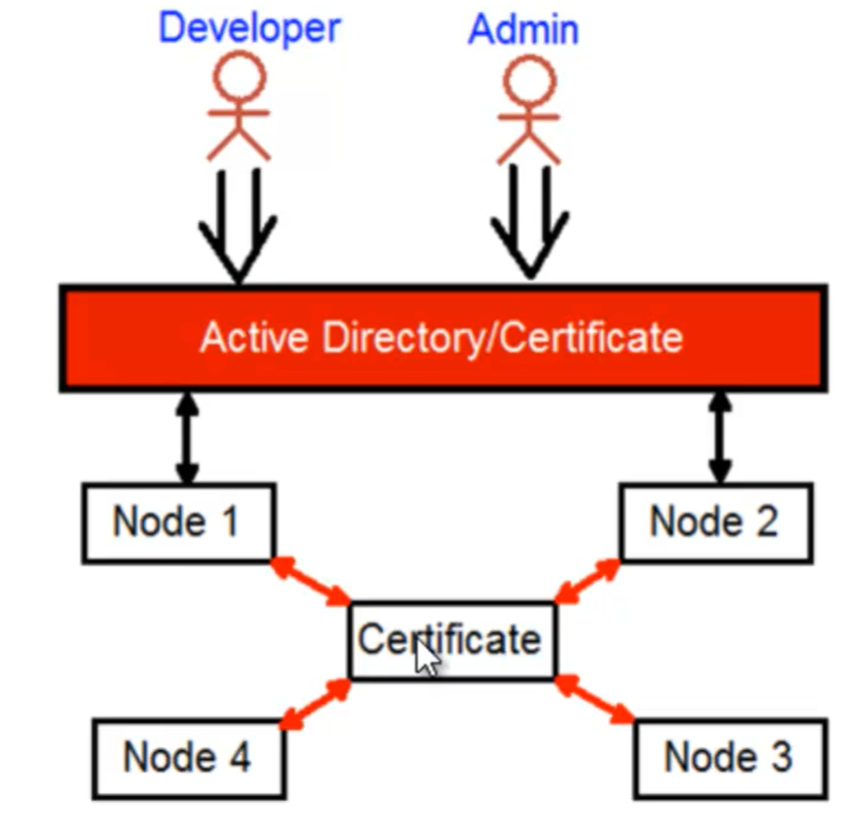
- Security =>
- Sicurezza nella comunicazione tra nodi del cluster
- Sicurezza nell’accesso da parte delle parti in causa (developers, admin)
-
- Key vault => (portafoglio di credenziali di accesso)
- Creare un certificato cluster (che verrà utilizzato per la comunicazione tra nodi)
- Creare un certificato client o aggiungere un utente di windows active directory (che verrà utilizzato degli stakeholder per accedere all’istanza di Azure Fabric)
- Passi da seguire darei permessi all’ Azure Fabric online=>
- Creare un sevice cluster
- Recuperare il TenantID
- Creare le 2 applicazioni (clusterapplication e clientapplication)
- Tramite ‘Azure Active Directory’
- Aggiungere gli untenti desiderati legati al TenantId
- Dare accesso per entrambe queste applicazioni a questi utenti
- Recuperare il TenantID
- Creare un sevice cluster
- Key vault => (portafoglio di credenziali di accesso)
WebJob (App Service) and background processing
- Normalmente si sviluppano 2 tipi di applicazione =>
- Con interfaccia utente (UI app) =>
- Cloud service => selezionare un progetto ‘Azure Cloud Service’ => ‘Web Role‘
- Con interfaccia utente (UI app) =>

-
-
- App service => selezionare ‘Cloud’ poi
- Azure Functions
- ASP:NET Web application
- App service => selezionare ‘Cloud’ poi
- Senza interfaccia utente (Non-ui app) =>
- Cloud Service => selezionare ‘Cloud’ => ‘Azure Cloud Service’ => ‘Worker Role‘
- App Service => selezionare ‘Cloud’ => ‘Azure WebJob‘
-
- WorkerRole => Permettono di implementare in modalità ‘Cloud Service‘ in Azure dei task eseguiti continuativamente in background
- Webjob =>
- Cosa é =>
- Permette di implementare in modalità ‘App Service‘ in Azure dei task eseguiti continuativamente in background
- Un WebJob condivide lo stesso ‘App service’ con le applicazioni web (come MVC) deploiate as an AppService
- Creare un webjob – Metodo1 =>
- Creo un nuovo progetto ‘Azure WebJob‘:
- mi permettà di avere delle funzionalità built-in rispetto ad un normale progetto ‘console app’
- non devo implementare un ciclo infinito se voglio che il task sia eseguito in modalità continuativa
- per pubblicarlo è sufficiente scegliere
- publish as ‘Azure WebJob’
- selezionare un app service esistente o crearlo (es: myappserviceshiv)
- dopo la pubblicazione, nel menu ‘WebJobs’ del mio ‘app service’ trovo il nuovo webjob appena deploiato (es: WebJob4):
- mi permettà di avere delle funzionalità built-in rispetto ad un normale progetto ‘console app’
- Creo un nuovo progetto ‘Azure WebJob‘:
- Cosa é =>
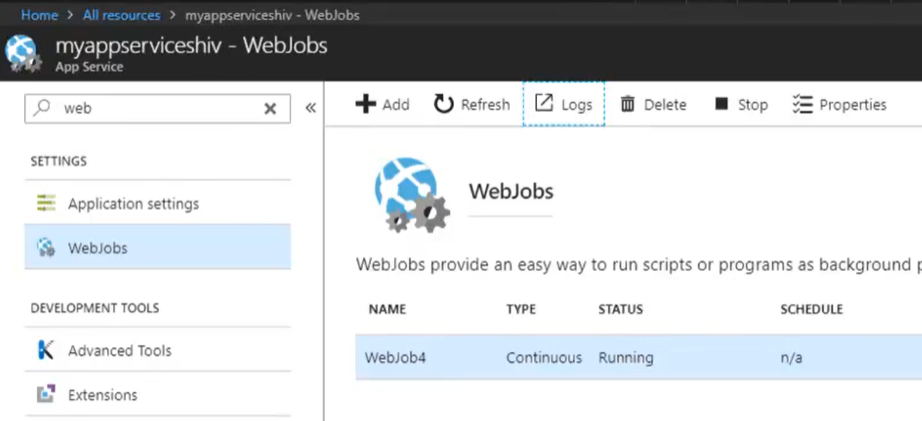
-
-
-
- Application settings =>
- Nel menu ‘Application Settings’ dell’app service aggiungere le 2 connectionString (app.config) al
- WebJob storage account (AzureWebJobsStorage) =>
- un storage per i dati (es: <datashiv>.core.windows.net)
- es: posso aggiungere la queue poi letta del webjob nella funtion ProcessQueueMessage
- un storage per i dati (es: <datashiv>.core.windows.net)
- WebJob storage account per i log (AzureWebJobsDashbord) =>
- uno storage per i log (dashboard) (es: <logshiv>.core.windows.net)
- WebJob storage account (AzureWebJobsStorage) =>
- Nel menu ‘Application Settings’ dell’app service aggiungere le 2 connectionString (app.config) al
- Application settings =>
-
-

-
- Creare un webjob – Metodo 2 =>
- Creo un normale progetto ‘console app’ (oppure degli script oppure degli exe) e lo ospito in un nuovo ‘webjob’ creato in Azure.com
- (in Azure) Aggiungo un web ‘AppService’ =>
- Non esiste in Azure nessuna differenza tra un ‘AppService’ creato per ospitare una web app (come MVC) o un exe (o uno script) come una console app
- Creare un webjob – Metodo 2 =>

-
-
- (in Azure) Dal menu del nouvo web ‘AppService’ creare un nuovo ‘WebJob’, indicando:
- File da deploiare =>
- Selezionare il file sul proprio computer (exe) da collegare al webjob che si sta creando
- Tipo => Decidere il tipo di job
- Triggered (viene eseguito solo quando un certo evento ha luogo)
- Continuos (viene eseguito continuativamente)
- Always On =>
- E’ necessario attivare l’opzione ‘Always On’
- Tale opzione non è possibile in caso di un piano azure gratis (bisogna avere un plan a pagamento)
- Always On =>
- Schedulazione => In caso di tipo ‘Triggered’ è possibile decidere la schedulazione (se desiderata)
- Cron expression =>
- Indicare i 6 elementi di una cron expression in base alla propria necessità
- Tra ognuno dei 6 elementi è necessario lasciare uno spazio
- es: 0 /*2 * * * * (esegui il task ogni 2 minuti)
- Cron expression =>
- File da deploiare =>
- (in Azure) Dal menu del nouvo web ‘AppService’ creare un nuovo ‘WebJob’, indicando:
-

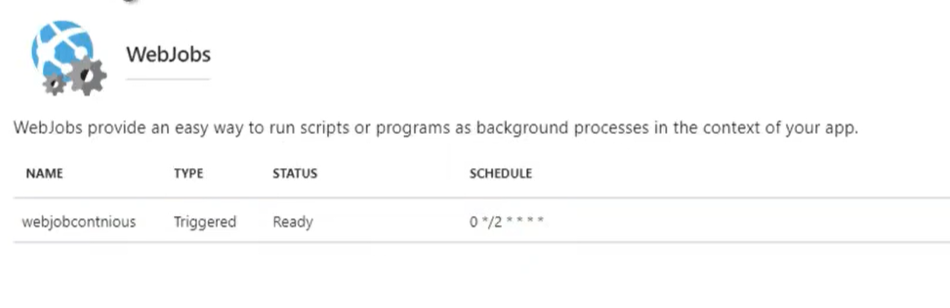
-
-
- (in Azure) Logs => Dal menu del nuovo ‘WebJob’ è possibile aprire la pagine con i ‘Logs’
-
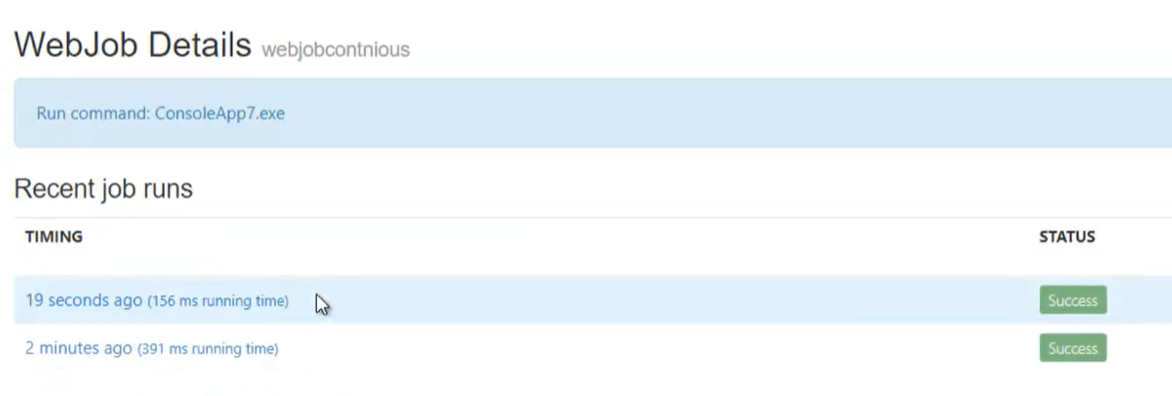
-
- Per rendere un task continuo:
- caso progetto ‘Console app’ => Deve essere cambiata la sua implementazione che deve prevedere una qualche forma di esecuzione infinita (come un ciclo sembre vero)
- caso progetto ‘Azure WebJob‘=> In tale caso la logica per dare forma infinita all’eseguizione è built-in
- Program.cs (host.RunAndBlock) =>
- Per rendere un task continuo:
-
-
-
-
-
- La chiamata host.RunAndBlock() permette di eseguire continuativamente il codice presente nel metodo ProcessQueueMessage (vedi sotto)
-
- Function.cs (ProcessQueueMessage) => Implementare qui la logica desiderata
-
-
-
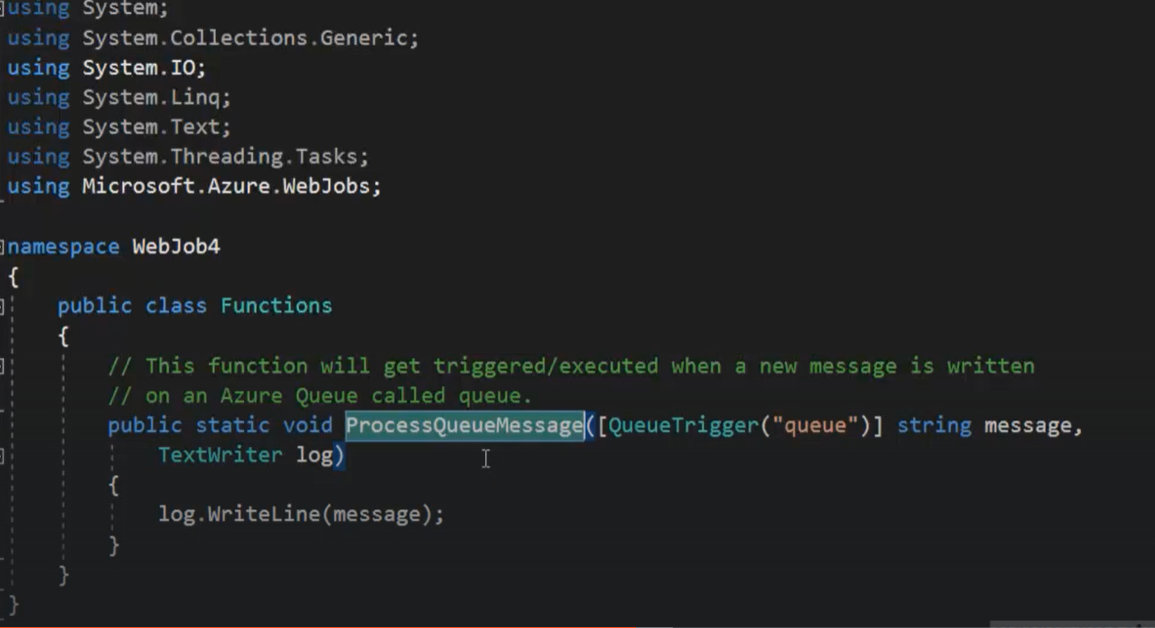
-
-
-
- App.Config => Ospita le connectionString per accedere al
- WebJob storage account =>
- uno storage per i dati (es: <datashiv>.core.windows.net)
- es: posso aggiungere la queue poi letta del webjob nella funtion ProcessQueueMessage
- uno storage per i dati (es: <datashiv>.core.windows.net)
- WebJob storage account per i log (dashboard) ) => un storage per i log(es: <logshiv>.core.windows.net)
- WebJob storage account =>
- App.Config => Ospita le connectionString per accedere al
-
-
-
- WebJob + Applicazione Web (as an app service) =>
- E’ possibile avere una soluzione mista =>
- un progetto ‘Azure WebJob’ (routine senza interfaccia)
- un progetto ‘ASP.NET Web application’ (applicazione con UI)
- Se si vuole deploiarla nello stesso ‘app service’ è necessario
- (in Visual Studio) Click dx sul progetto Web
- Click ‘Add’
- Creare un nuovo ‘Azure WebJob’ project
- oppure collegare un ‘Existing Project as Azure WebJob’
- webjobs-list.json =>
- Viene aggiunto all’applicazione web il file ‘webjobs-list.json’
- Tale file configura il ‘publish’ all’applicazione web in modo che faccia il deploy anche del WebJob indicato
- Click ‘Add’
- (in Visual Studio) Click dx sul progetto Web
- E’ possibile avere una soluzione mista =>
- WebJob + Applicazione Web (as an app service) =>
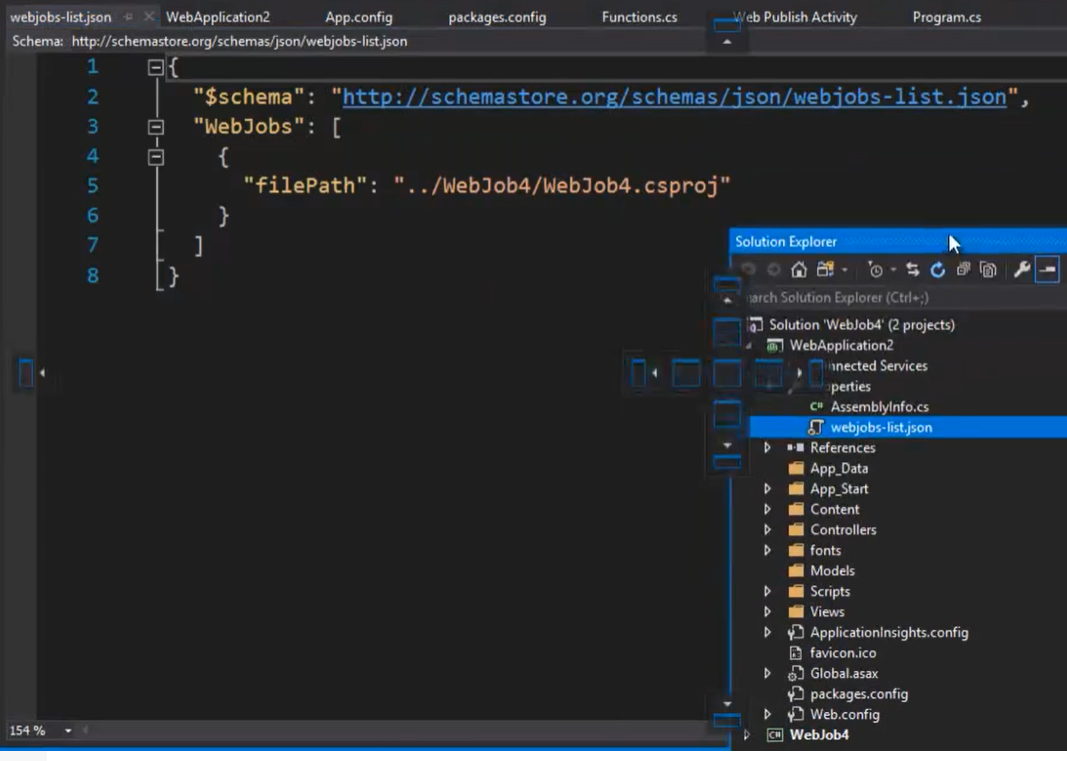
-
-
-
- (in Visual Studio) Click su ‘Publish’ =>
- Selezionare ‘App service’ e confermare il publish
- Verrà deploiata l’applicazione web (es: <myappservice>.azurewebsites.net)
- Verrà deploiato il WebJob
- (in Visual Studio) Click su ‘Publish’ =>
-
-
Azure DevOps (Software developer + Operations/Admin)
- Cosa é DevOps =>
- E’ un framework, del gergo e delle pratiche per ridurre il tempo tra il commit di un cambiamento e la sua messa in produzione e gatantire migliore qualità.
- Nel passato => Esempio di deploy nel modo classico
- Sviluppatori => Mettono il codice ‘source control’.
- Membri QA => Verificano bugs e li reinviano agli sviluppatori.
- Mebri dell’ IT => Una volta il codice validato, ne fanno il deploy in PROD.
- Sviluppo e messa in produzione erano 2 attività separate.
- Con l’arrivo di DevOps
- Sviluppo e messa in produzione sono uniti.
- Il tempo di rilascio di nuovo codice è molto ridotto.
- La qualità è aumentata
- Gli errori sono scoperti prima, riducendo il tempo perso per errori non attesi.
- Working culture =>
- Miglior cultura del lavoro e meno problemi di collaborazione (tra il team di sviluppo e il team IT) e lamentela.
- Nel passato => Esempio di deploy nel modo classico
- E’ un framework, del gergo e delle pratiche per ridurre il tempo tra il commit di un cambiamento e la sua messa in produzione e gatantire migliore qualità.
-
- CI/CD (Continous integration / Continous deployment) =>
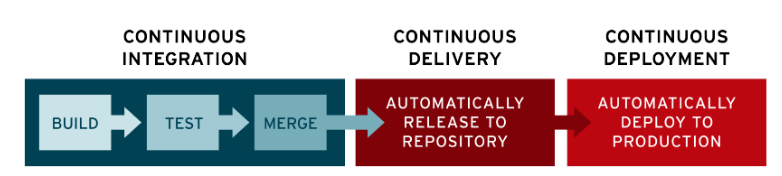
-
-
- L’approccio continuous integration / continuous deployment è l’insieme dei passaggi automatizzati e standardizzati che vengono eseguiti per fornire una nuova versione software.
- Continuous Integration (CI)
- Si riferisce alla cattura di bug o problemi all’inizio del ciclo di sviluppo. Quando sono facilmente identificabili e sesitemabili.
- Continuous Deployment (CD)
- Fa il deploy automatico del codice che arriva dall`integrazione continua.verso gli ambienti di Test + Staging + Produzione.
- Lavorando insieme, queste pratiche producono ‘artifact’ deploiabili
- Continuous Delivery (CD)
- Fa il deploy automatico del codice che arriva dall`integrazione continua.verso gli ambienti di Test + Staging (!= da ‘Continuous Deployment‘)
- DevOps =>
- Dev = Plan + Code + Build +Test
- Ops = Release + Deploy + Operate + Monitor
- E’ suddiviso in 8 fasi (vedi immagine sotto):
-
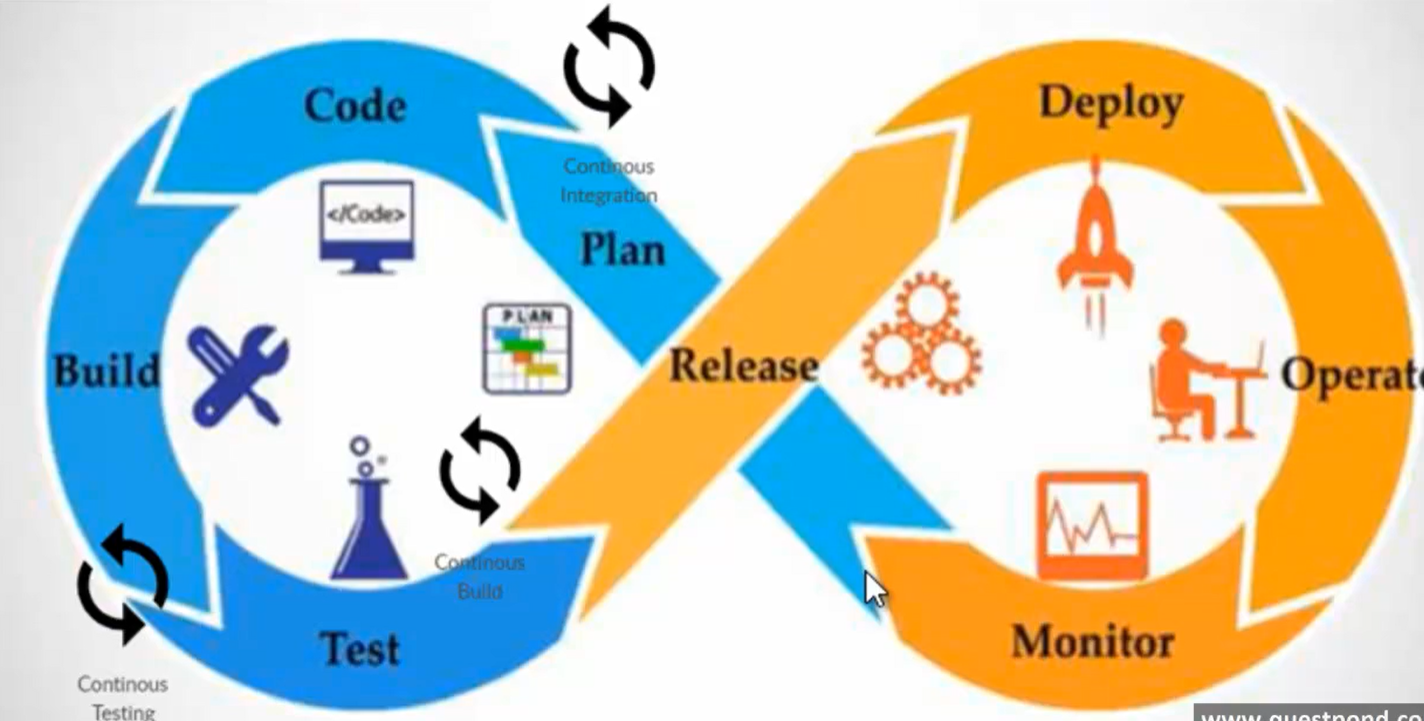
- Cosa è Azure DevOps =>
- Offre un’implementazione per creare un’organizzazione che segue le pratiche DevOps
- Si pone come un’alternativa all’utilizzo di numerosi strumenti/software differenti.
- Fornisce un environment unico e integrato per gestire e pianificare tutte le operazioni e attività =>
- Plan (Trello, Office).
- Code checking.
- Build (Kubernetes, Jenkins, Cucumber).
- Deploy automatico in VM.
- Continui feedback.
- Integrations/Extensions => Azure DevOps offre l’integrazione di molti software e tool presenti sul mercato
- Slack, Campfire, Github
- Massimo livello di automazione (mai il 100%) => Uso intensivo di tool di automazione
- Paragone con altri tools per la CI/CD
- Azure DevOps offre una piattaforma unica per gestire tutte le attività legate alla CI/CD
- Senza la necessità di dover gestire le comunicazioni tra più piattaforme (ognuna con un’operatività specifica) durante tutto il flusso delle operazioni
- Migliora la tracciabilità => Un ‘work item’ risulterà rintracciabile in ognuna delle fasi di lavoro.
- La Azure Pipeline puo fare il deploy anche su altre piattaforme cloud (es: AWS) e non necessariamente verso Microsoft Azure
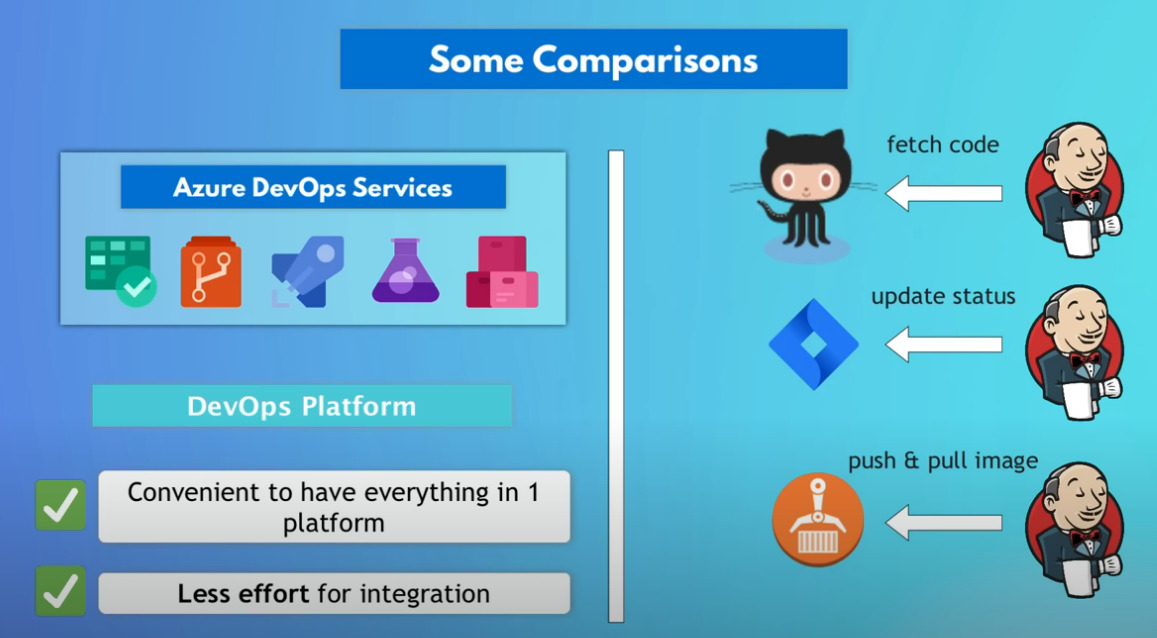
- Azure DevOps Architecture
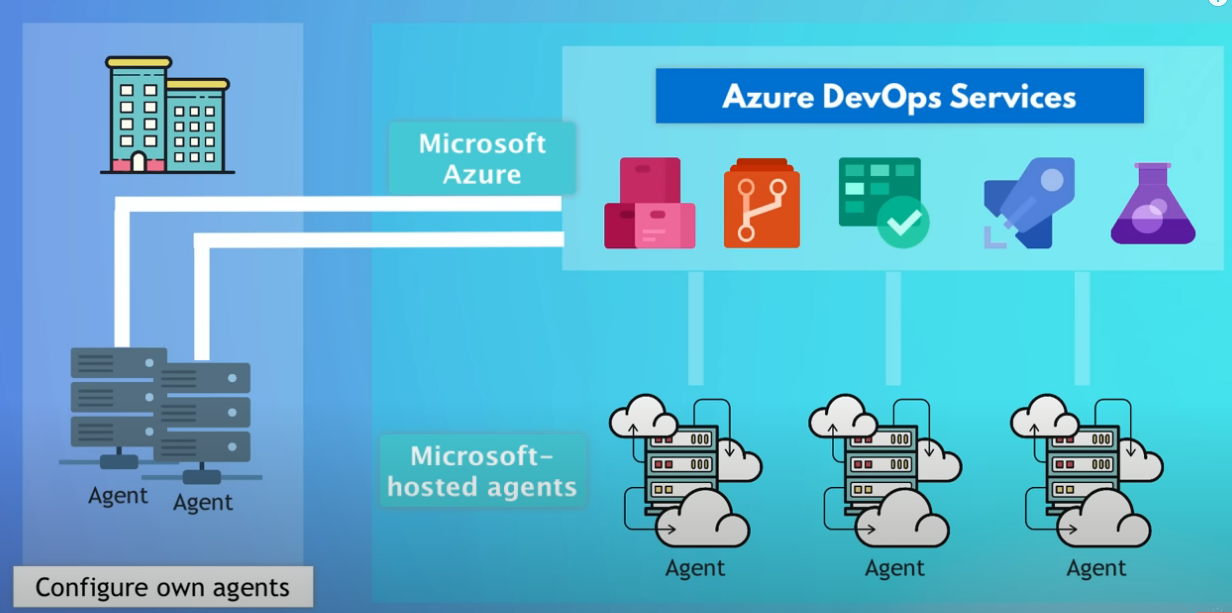
-
- Azure DevOps Services
- I servizi Azure DevOps sono del tipi SaaS (software as a service).
- Gestisti in isolazione da Microsoft.
- Rappresente e ospita la parte principale di ‘Azure DevOps’ => Configurations, Pipelines, Repository
- Agent machines
- Sono macchine separate nelle quali vengono effettivamente eseguiti i task definiti nella ‘pipeline’.
- Caso 1 – Microsoft hosted build Agent:
- E’ il Build Agent usato in Azure che gestisce tali macchine.
- E’ gestito e configurato da autonomamente da Azure (non si deve installare nulla localmente).
- Lo sviluppatore ha confidenza nel build.
- Caso 2 – Configurare in propri gli agents
- Alcune compagnie preferiscono aspitare gli agents nei propri server.
- Tali macchine dialogano con i servizi Azure DevOps che rimangono nel cloud.
- Azure DevOps Services
- Azure DevOps life cycle
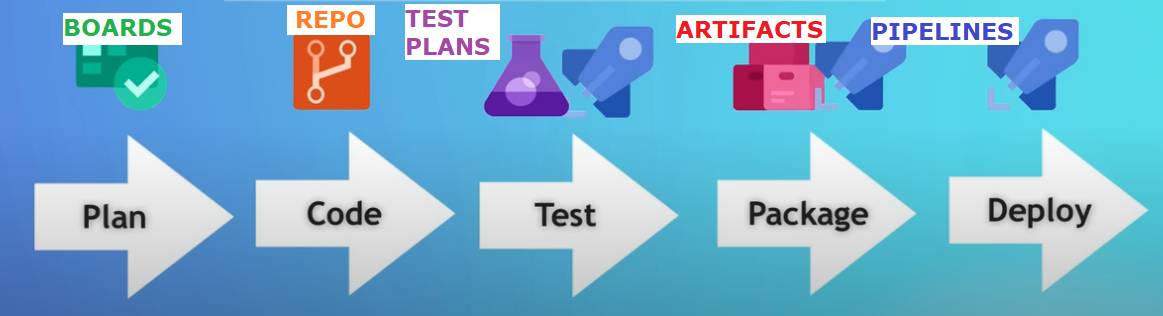
- Azure DevOps connections
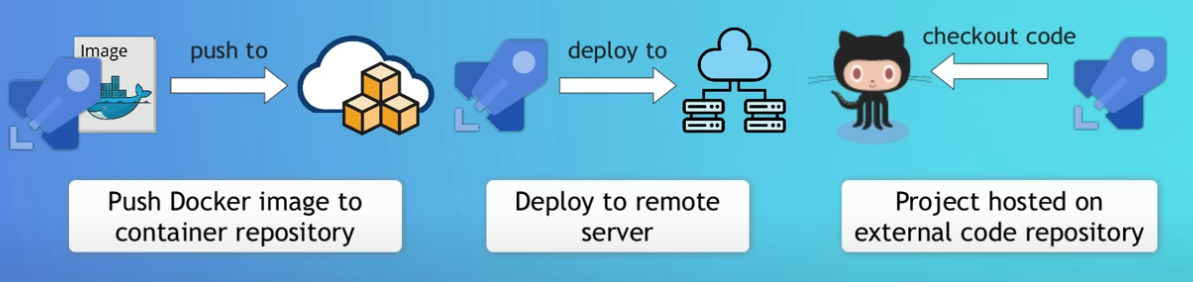
-
- Nel ciclo di vita di un progetto Azure DevOps é necessaria la connettersi, autenticarsi e interagire con altre macchine e altri servizi (piattaforme)
- Nei ‘Project settings‘ => ‘Service Connections‘
- E’ possibile gestire le connessioni (e autorizzazioni) con i servizi esterni con cui il progetto Azure DevOps interagiste
- Per esempio ‘GitHub’, ‘Azure Subscription’, ‘Docker’
- Usa delle credenziali che sono aggiornate spesso
- Attività preliminari =>
- Creare un’organizzazione e un progetto Azure [** attività **] =>
- Selezionare Azure DevOps (https://dev.azure.com)
- Nuova organizzazione =>
- Come primo passo è necessario creare una nuova ‘Organization‘ a cui faranno riferimento tutte le attività gestire tramite ‘Azure DevOps’
- Fornire un nome che farà parte dell’URL (https://dev.azure.com/<MyOrganization>)
- ‘Organization Settings’ =>
- Cambiare il nome dell’organizzazione.
- Cambiare l’URL.
- Eliminarla.
- Work item process types (scegliere il tipo di processo con si vogliono gestire le singole attività) =>
- Agile
- New
- Active
- Resolved
- Closed
- Basic
- Il processo prevede 3 passaggi
- To-do
- Doing
- Done
- Il processo prevede 3 passaggi
- CMMI
- Scrum
- Agile
- Nuovo progetto =>
- Creare un nuovo progetto e fornirgli un nome
- Livello di visibilità
- Publico
- Privato (visibile solo all’interno dell’organizzazione)
- Selezionare il tipo di flusso
- ‘Organization’ => ‘Settings’ => Boards.Process => E’ possibile settare il tipo di default.
- Work item process types =>
- Agile
- New
- Active
- Resolved
- Closed
- Basic
- Il processo prevede 3 passaggi
- To-do
- Doing
- Done
- Il processo prevede 3 passaggi
- CMMI
- Scrum
- Agile
- Dashboard =>
- Ho accesso alla ‘Dashboard’ per gestire tutte le operazioni all’interno del nuovo progetto
- Creare un’organizzazione e un progetto Azure [** attività **] =>
-
- Definire il team => Aggiunere collaboratori al progetto [** attività **]
- Invitare user o gruop
- ‘Project’ => ‘Summary’ => E’ possibile fare un nuovo invito e vedere la lista delle persone collegate al progetto.
- Definire il team => Aggiunere collaboratori al progetto [** attività **]
- Gestire diverse tappe del progetto =>
- Voci del menu di un ‘Project‘:
- menu Boards (Track work)
- menu Repos (Cloud-based source control)
- menu Pipelines (Build, Test and Deploy)
- menu Testplans (Test apps)
- menu Artifacts
- Voci del menu di un ‘Project‘:
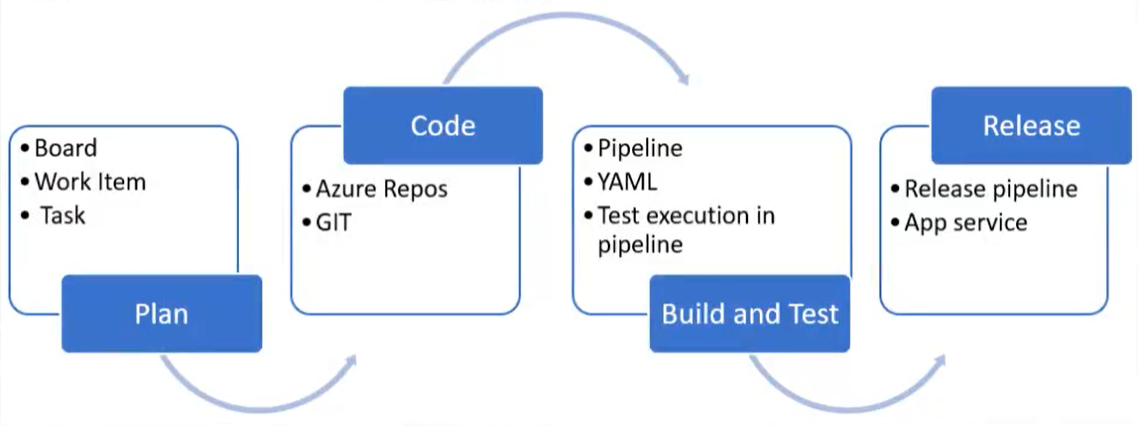
-
- Menu ‘Boards’ (Plan and track)
-
-
- Cosa é =>
- Definire cosa deve essere fatto => Aiuta il project management
- Voci del menu ‘Boards’ (Work items, Boards, Backlogs, Sprints, Queries, Delivery Plans, Analytics views)
- Work items
- Elenco delle attività da farsi.
- Tipo di ‘Work Item’
- Bug
- Ogni possibile problema riscontrato nelle attuali funzionalità
- Funzionalità mancante
- Epic
- E’ una grande ‘user story’ che non puo’ essere rilasciata con una singola iterazione.
- E’ una ‘user story’ grande abbastanza per essere suddivisa in piu ‘user story’.
- Feature
- Semplicemene Microsoft ha pensato che fosse più chiaro usare ‘Feature’ che ‘User Story’. I due sono quindi sinonimi.
- Issue
- Un evento che impedisce il normale sviluppo delle attività.
- Task
- Ogni membro del team buon definire dei task che rappresentano delle attività da fare.
- Test Case
- User Story
- Ognuna delle voci della lista.
- Offre una descrizione della feature ed é usata per pianificare e raggruppare.
- Raggruppano un piccolo gruppo di funzionalità che hanno un valore per il cliente e che si vuole deployare insieme.
- Bug
- Visualizzazione specifico ‘Work Item’
- Related Work
- E’ possibile collegare il corrente item ad un altro, instaurando una gerarchia tra i due elementi.
- Development
- E’ possibile collegare il corrente item ad un repository esterno
- Tipo di link => Specifica voce del repository che é collegata al work item corrente (es/ build, pull request)
- Related Work
- Boards =>
- Rappresentazione visiva delle attività da farsi (‘Work Item’) e il loro stato (altrimenti detta Kanban board).
- Possibilità di gestione delle attività secondo il work item process scelto a livello di organizzazione.
- Backlog navigation level => Possibilità di scegliere quali ‘Work Item type’ rendere navigabili nel ‘Backlog’
- Epic
- Feature
- Story
- Backlogs =>
- Rappresentazione gerarchica delle attività da farsi (‘Work Item’) e la loro assegnazione ad uno ‘Sprint’.
- Cosa è un ‘Backlog‘
- E’ la lista priorizzata di attività da fare o nuove funzionalità da sviluppare
- Normalmente a un progetto corrisponde un backlog.
- Backlog navigation level => Possibilità di scegliere quali ‘Work Item type’ rendere navigabili nel ‘Backlog’
- Epic
- Feature
- Story
- Sprints =>
- Cosa è uno sprint
- Il periodo in cui il team completa una quantità pre-pianificata di lavoro.
- Fissa la deadline entro la quale deve essere rilasciato l’artifact deployabile.
- Container per organizzare le story (work item)
- Normalmente creati dai ‘Product owner’ o ‘Project manager’.
- Visualizzo tutti gli elementi legati allo sprint (iterazione) selezionato.
- Creare un nuovo sprint
- Nome.
- Periodo.
- Progetto di competenza.
- Settare il livello
- Backlog navigation levels
- Gestire la capacità (oraria) dei membri del team.
- Cosa è uno sprint
- Queries (Apri Microsoft doc)
- E’ possibile lanciare e salvare delle query per trovare dei work item secondo numerosi parametri.
- Modifiche bulk => I risultati delle query possono essere usati per fare delle modifiche bulk.
- Tipo di query
- Flat list of work item => E’ possibile visualizzare solo i work item al top level.
- Work items and direct links => E’ possibile visualizzare dei work item che dipendono da altri (non top level)
- Tree of work items =>
- E’ possibile filtrare nella stessa query i padri e i figli fornedo i due differenti criteri
- Il risultato è una lista di padri che mecciano la prma queury. Legato ad ogni padre ci saranno i suoi figli che mecciano la seconda query
- Work items
- Cosa é =>
-
-
-
- Utilizzi principali di ogni voce del menù =>
- Queries
- Semplici reporting
- Modifiche bulk
- Fare la mail di una lista di item
- Work item
- Visualizzare gli item assegnati a me
- Visualizzare gli item dove si é nominati.
- Visualizzare gli item rispetto al loro stato.
- Boards
- Implementare il scheda Kanban.
- Visualizzare il flusso del lavoro per ogni membro del team.
- Aggiungere rapidamante voci al backlog.
- Modificare lo stato delle voci del backlog.
- Blacklogs
- Planning a sprint
- Scrum master e Prodcut owner sviluppano il loro projet plan.
- Sprint
- Implementare Scrum
- Aggiungere rapidamante voci al backlog.
- Configurare e monitorare la capacità (oraria) del team.
- Queries
- Utilizzi principali di ogni voce del menù =>
- Menu Repos (Contiene i codice sorgente e li condivide) =>
-
-
-
- Cosa è =>
- Permette di memorizzare e condividere i codici sorgente del nostro progetto.
- Permette di impostare il tool che si é scelto di usare per la ‘gestione del codice’.
- Git
- TFVC (Team Foundation Version Control)
- Personal access token (PAT)
- Ne esiste uno creato al momento della creazione dell’organizzazione
- Se ne possono creare di customizzati indicando lo scope cioé le credenziali che si vogliono concedere
- Git credential manager
- La prima volta che si accede ad un repository AzureDevOps in locale
- Vengono chieste le credenziali Git per potervi accedere
- il Git credential manager genererà un nuovo PAT (il cui nome è generato in automatico dal nome della macchina) e ne fa il cache localmente
- La prima volta che si accede ad un repository AzureDevOps in locale
- Cosa è =>
-
-
-
- Aggiungere un repository in Azure Repo =>
- Import a repository
- E’ possbile collegare un repository Github or TFS direttamente in Azure DevOps indicandone l’URL (es: https://github.com/leperegoriot1977/flatris.git)
- Initialize a main branch =>
- E’ possibile inizializzare un nuovo repository aggiungendo i file
- readme
- .gitignore
- E’ possibile inizializzare un nuovo repository aggiungendo i file
- Push an existing repository
- Fare il push di un repository esistente in locale
- Il repository in AzureDevOps deve avere lo stesso nome della cartella in locale
- Eseguire i seguenti comandi
-
git remote add origin https://asn-net@dev.azure.com/asn-net/<project_name>/_git/<repository_name> git push origin master [da master -> origin]
-
- Fare il push di un repository esistente in locale
- Import a repository
- Clonare un repository da Azure Repo =>
- Menu Files => Clone
- Clone to your computer =>
- Aggiungere un repository in Azure Repo =>
-

-
-
-
-
- Creare manualmente la carella in locale e tramite la shell fare il clone del repository Azure, indicandone le credenziali quando richieste.
- Automaticamente tramite il bottone ‘Clone in..’ scegliendo l’environment target (es: Visual Studio)
-
- Associzazione tra ‘Work Item’ e ‘Repository’ in Azure
- Ramo => Quando si crea un nuovo ramo su un repo in Azure è possibile associarvici un dato ‘Work Item’.
- Commit => Quando si fa un nuovo commit è possibile associarvici un dato ‘Work Item’.
- Scheda del ‘Work Item’
- Tale collegamento è visibile nella scheda nella sezione ‘Development’.
- Menù ‘Pull requests’
- Visualizza tutte le ‘Pull Request’
- Azure aggiunge una richiesta ‘Pull Request’ ad ogni modifica (commit) effettuata.
-
-
-
- Menu ‘Pipelines – Pipelines‘ => Continuous intergration (CI)
-
-
- Concetti generali
- CI/CD
- Continuous Integration (CI) => Always building and test code.
- Continuous Deployment (CD) => Always deploying code.
- Pipeline
- E’ dove la CI/CD ha luogo
- Combinano l’integrazione continua (CI) e la il continuo delivery (CD) per garantire costantemente di
- Testare
- Fare il build
- Il deploy del proprio codice a qualsiasi destinazione
- Combinano l’integrazione continua (CI) e la il continuo delivery (CD) per garantire costantemente di
- A seguito di un commit del codice (accepted pull request), la ‘Pipeline’ esegue dei task.
- Le pipeline possono funzionare praticamente con qualsiasi linguaggio o tipo di progetto.
- Azure Pipeline permette infinite combinazioni per poter gestire ogni particolare ambiente di sviluppo, strumenti di sviluppo o piattaforma dove fare il deploy
- E’ dove la CI/CD ha luogo
- Task
- I task eseguono delle operazioni nei repository (che ospitano il codice) presenti nel nostro repository provider (es: GitHub).
- I task possono essere eseguiti manualmente o automaticamente.
- Build Agent
- E’ il software installabile che esegue effettivamente le operazioni legate ad ogni task, un job dopo l’altro.
- Agent pool
- L’agent effettivamente utilizzato é selezionato da un pool (es: windows, mac, linux)
- Definisce quale OS e quale versione sarà usata per eseguire i differenti ‘task’ della nostra pipeline
- CI/CD
- Concetti generali
-
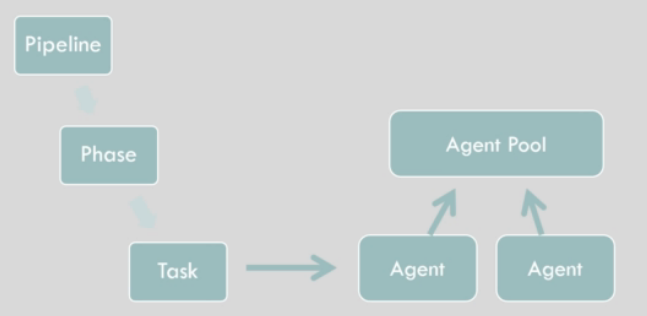
-
-
-
- Artifact =>
- E’ il risultato della ‘Build pipeline’
- E’ un’unità di codice compilato della mia applicazione che puo’ essere testato o deployato.
- Sono prodotti da un’ampia gamma di sorgenti d’artefatti e che sono archiviati in diversi tipi di repository.
- Esempi
- Java impacchettato in un file zip (.jar)
- NET impacchettate in un file zip. (.nuget)
- Javascript library (.zip)
- Docker image o una Virtual Machine (dove il nostro codice sarà eseguito)
- Artifact =>
-
-
-
-
- Cosa é =>
- Una volta che il codice é stato sviluppato e mergiato nel ramo ‘main’ tramite una pull request deve essere rilasciato.
- In particolare questo menù gestisce la prima parte del CI/CD (cioé della fase di rilascio) => Prepara cosa deployare (test + package)
- Cosa é =>
-
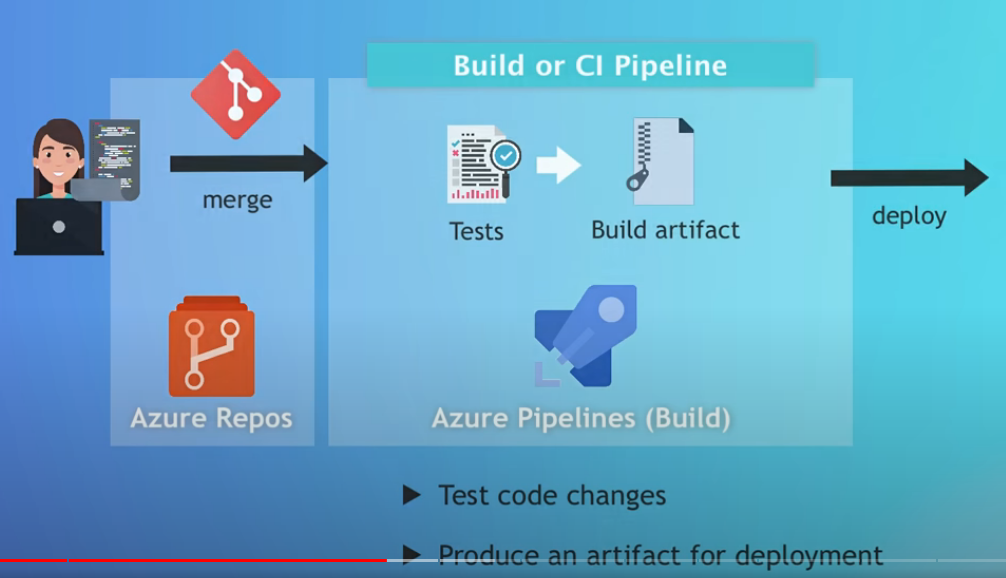
-
-
-
- Si parla di ‘Build pipeline‘ => Code => Steps => Artifact.
- CI + CD in un unico step
- Nella ‘build pipeline’ é possibile combinano l’integrazione continua (CI) e la il continuo delivery (CD) e creando un’unica pipeline
- Azure-pipelines.yml =>
- Infatti é possibile aggiungere stage e i loro task direttamente dal file di configurazione (vedi sotto).
-
-
-
-
- Creare una nuova ‘pipeline’ =>
- Caso 1 – Configurazione tramite UI (classic editor) =>
- Parametri principali della pipeline
- Dove
- Indicare dove si trova il codice sorgente selezionando il repository (es: Azure Repos Git, GitHub, Bitbucket, Subversion, Other git).
- Template
- Selezionare un template in relazione al tipo di progetto che si trova nel repository selezionato (vengono elencati alcuni template di base):
- Emtpy Job => E’ possibile selezionare un template vuoto.
- Agent pool
- Microsoft hosted o privato.
- Specificare la versione del SO desiderato in rapporto all’agent scelto.
- Path
- Progetto principale
- Indicare dove si trova il progetto principale di cui fare il build.
- Esempio => **/*.csproj
- Progetto di test
- Indicare dove si trova il progetto di test.
- Esempio => **/*[Tt]ests/*.csproj
- Progetto principale
- Dove
- Tab Tasks
- Configurare gli stetp precaricati (Jobs/Tasks).
- Aggiungere nuovi Jobs/Tasks, se necessario.
- Tab variabili
- Le variabili memorizzano valori o ‘secret’ che é possibile referenziare nella propria pipeline o rendere disponibile su più altre pipeline.
- Tab trigger
- Enable continous integration (CI) =>
- Con questa stunta ceccata si avviano (kick off) le operazioni impostate nella pipeline dopo ogni merge nel ramo principale (‘commit con sync’ in Visual Studio)
- Branch filters
- E’ possibile Includere/Escludere eventuali rami del repository
- Path filters
- E’ possibile Includere/Escludere eventuali cartelle del repository
- Enable continous integration (CI) =>
- Tab Options
- Configurare qui le proprietà del file di distribuzione prodotto dalla build.
- Tab History
- Visualizza esecuzioni passate della pipeline.
- Parametri principali della pipeline
- Caso2 – Configurazione tramite Azure-pipelines.yml =>
- Pipeline script =>
- File di configurazione della pipeline di build.
- Viene memorizzato nello stesso repository del progetto.
- YAML => Yet Another Markup Language., Data serialization standard
- E’ possibile parametrare tutte le proprietà come nel caso di utilizzo della UI.
- Steps
- Job =>
- Un job delimita e ragruppa una serie di ‘Step’
- Ogni job viene eseguito da un agent diverso.
- Esempi di utilizzo dei job
- E’ possibile eseguire 2 o più test in parallelo invece di attendere reciprocamente
- E’ possibile eseguire una serie di steps in 2 o più ‘enviroment’ diversi (vedasi immagine)
- Nel caso di unico job non é necessario aggiungere il tag job nel file.
- Job =>
- Pipeline script =>
- Caso 1 – Configurazione tramite UI (classic editor) =>
- Creare una nuova ‘pipeline’ =>
-
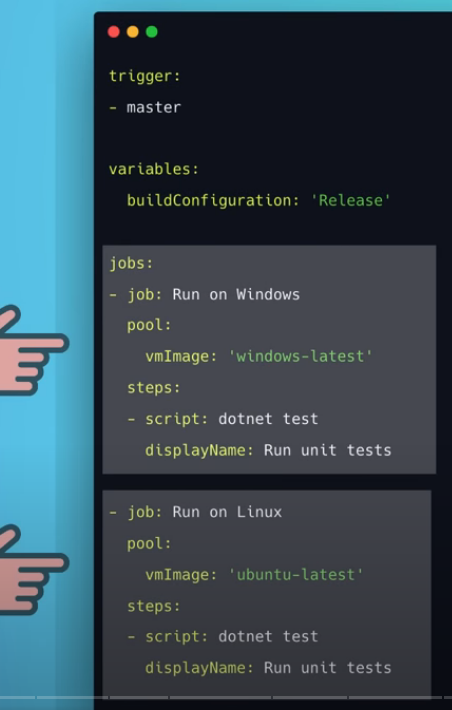
-
-
-
-
-
- Script o task =>
- Ogni blocco che costituisce il nostro script o task (o script preconfezionato disposizione secondo convenienza)
- Esplicitano le operazioni da fare per poter testare e impacchettare il nostro codice (ormai pronto e validato).
- Script o task =>
-
-
-
-


-
-
-
- Save / Save and queue / Save and run =>
- E’ possibile salvare la configurazione della pipeline.
- Oppure é possibile salvare e schedulandone il job (solo nel Caso1) o eseguandola direttamente (solo nel Caso2)
- Viene aggiunto nel repository il file Azure-pipelines.yml
- Cartella degli Artifacts
- Viene prodotto un artifatto (un file .zip) con la versione eseguibile della mia applicazione.
- Tale file é disponibile nella cartella degli artifatti
- Visualizzando il dettaglio della pipeline é possibile accedere al menu degli ‘Articats’ relativi alla nostra pipeline.
- E’ possible farne il download o attivare la pipeline di release (CD). Spesso é attivita in automatico.
- Save / Save and queue / Save and run =>
- Esecuzione della ‘pipeline’
- La pipeline viene eseguità dall’agent pool indicato.
- default= ‘Azure Pipeline’
- Tale agent pool prende i job accodati e li esegue uno dopo l’altro.
- Una volta eseguita la pipeline da ‘queued’ divent.
- La pipeline viene eseguità dall’agent pool indicato.
-
- Menu ‘Pipelines – Release’ => Continous Deployment or Delivery (CD)
-
-
-
- Cosa é =>
- In particolare questo menù gestisce la seconda parte del CI/CD => Dove deployare.
- Si parla di ‘Release pipeline‘.
- CI + CD in un unico step
- In altre piattaforme CI/CD (e: Jenkins) si ha una sola pipeline per l’intero processo CI/CD.
- Azure-pipelines.yml =>
- Anche in ‘Azure DevOps’ é possibile scegliere di configurare CI+CD insieme tramite script.
- Infatti é possibile aggiungere stage e i loro task direttamente dal file di configurazione della ‘build pipeline‘ (vedi sopra).
- Cosa é =>
-
-
-
- [opzionale] Creare Azure VM server per ospitare il build
- Tornare al menù principale
- Creare un nuovo ‘app service’ (con un ready-made template) per ospitare la nostra applicazione
- Indicare il ‘resource group’,
- Indicare il nome dell’app service
- URL della VM appena creta => https://<my-app>.azurewebsites.net
- Publish => Indicare che si tratta del codice sorgente da ospitare nella VM (e non un container docker)
- Runtime stack => Scegliere il template della VM (es: ASP.NET Core)
- Application insights => Abilitare o disabilitare le funzionalità di analisi delle performance
- Passo 1 – Creare una ‘Realese pipeline’ (tramite UI) =>
- [opzionale] Creare Azure VM server per ospitare il build
-
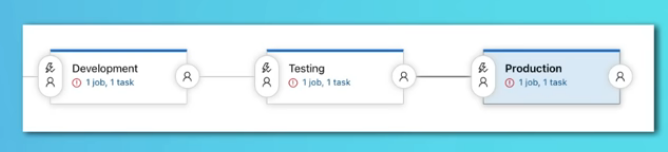
-
-
-
- Artifact =>
- Selezionare l’artifact da deployare
- Caso 1
- Selezionare la build che si vuole deployare tra quelle create con la ‘Build pipeline’ che ha prodotto un artifact (in pratica è un file zip)
- Caso 2
- Selezionare dove recuperare l’artifact già creato (es: Azure Repo; Gitub; Jenkins)
- Stage =>
- Aggiungere un ‘stage’ =>
- Stage => Ragruppamento logico di azioni (job/task) svolte nella pipeline.
- E’ possibile aggiungere alla pipeline 1 o più stage (es: uno per ogni ‘environment‘).
- Template =>
- Scegliere uno dei template proposti (es: Azure App Service Deployment) e fare ‘apply’.
- Verrà creato un nuovo job a cui sono legati dei task precaricati in funzione del teplate scelto.
- Oppure scegliere il teplate con un job vuoto.
- Scegliere uno dei template proposti (es: Azure App Service Deployment) e fare ‘apply’.
- Environment
- Ognuno degli ‘enviroment’ in cui vogliamo fare il deploya puo’ essere soggetto di uno stage apposito
- Aggiungere un ‘stage’ =>
- Artifact =>
-
-

-
-
-
-
- Teplates (Parte di of configuratione riutilizzabile) =>
- E’ possibile centralizzare dei task comuni a tutti gli ‘environment’ in file detti ‘teplates’.
- Tali ‘templates’ (files di tipo .yml) possono essere memorizzati nel repository stesso.
- E’ possibile creare template
- stages
- jobs
- steps/tasks
- Tali ‘templates’ possono essere referenziati e parametrati direttamente nel file di configurazione Azure-pipelines.yml
- Teplates (Parte di of configuratione riutilizzabile) =>
-
-
-
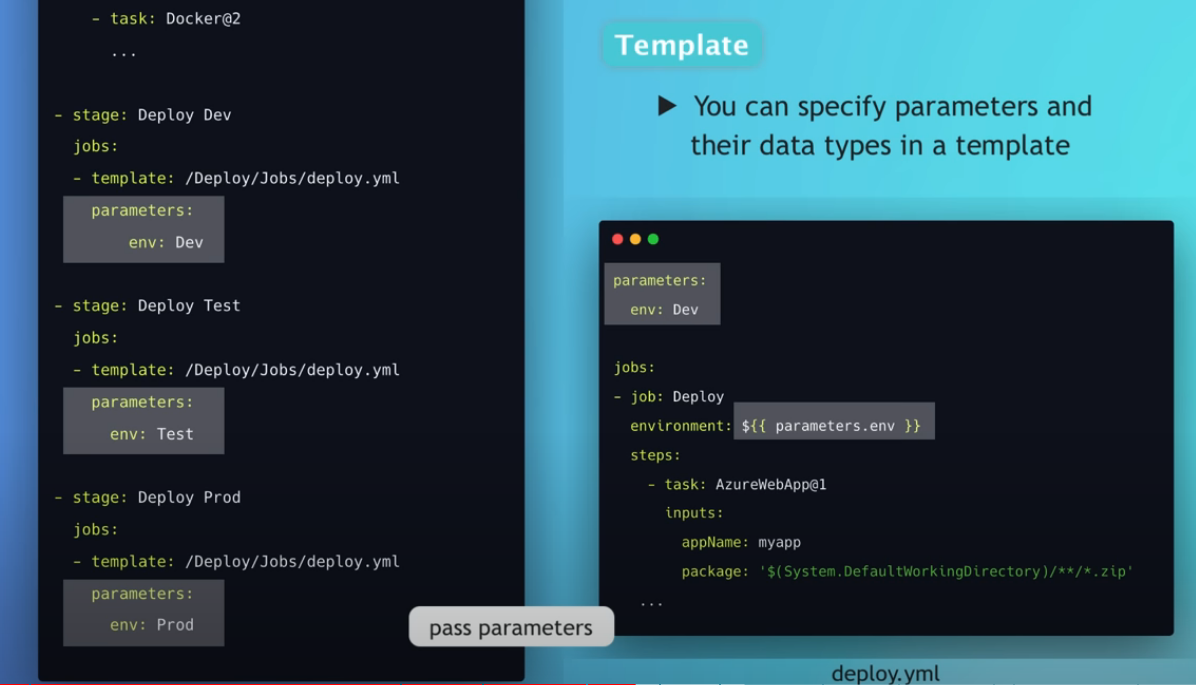
-
-
-
- Aggiungere ‘task’ allo stage =>
- Task => Dove indicare le operazioni che il ‘build agent’ deve fare ad ogni esecuzione del job legato allo stage.
- Ogni task prevede dei dati di configurazione dedicati.
- I Task possono essere di differenti tipi
- Build
- Test
- Deploy
- Utility (es: bash script, delete files…)
- Aggiornameno package (es: nuget restore)
- Installazione package
- Marketplace
- Se si é creato lo ‘stage’ usando un ‘template’ i ‘task’ saranno già preinseriti.
- Aggiungere ‘task’ allo stage =>
- Passo 2 – Creare una nuova release
- Una volta parametrata la nosta ‘release pipeline’ é possibile creare una nuova ‘release’
- Salvare la ‘release’ per eseguirla direttamente.
- Tab variabili
- Le variabili memorizzano valori o ‘secret’ che é possibile referenziare nella propria pipeline o rendere disponibile su più altre pipeline.
- Tab History
- Visualizza esecuzioni passate della release pipeline.
- Enable Continous Deployment (CD) (Automatic golive) =>
-
-
-
-
-
- Cliccare sulla piccola icona del fulmine nella sezione ‘Articats’
- Continous deployment trigger
- Abilitare il trigger per eseguire la pipeline ogni volta che è disponibile una nuova build.
- Percio ogni operazione di build (CI) scatenerà automaticamente un deploy nell’app-service indicato degli ‘environment’ indicati nella ‘release pipeline’.
- Pull request trigger
- Abilitare il ‘Continous deployment’.
- Abilitare il trigger per eseguire la pipeline ogni volta che una nuova versione dell’artefatto selezionato nella pipeline è disponibile a seguito di una nuova ‘Pull request’.
- Continous deployment trigger
- Cliccare sulla piccola icona del fulmine nella sezione ‘Articats’
- Trigger tra uno stage e il succesivo
- Automatico => Di default durante l’esecuzione della ‘release pipeline’ terminata l’esecuzione di uno ‘stage’ si passa al successivo automaricamente (Continous deployment).
- Manuale => E’ possibile per esempio configurare uno ‘stage’ a essere eseguito manualmente (tramite il trigger legato allo ‘stage’ stesso) (Continous delivery).
-
-
-
- Menu ‘Pipelines – Environments‘ =>
-
-
- E’ possibile creare dei nuovi ‘Environment’ per poi referenziarli nel file azure-pipelines.yml.
- Abbiamo cosi’ la possibilità di avero lo storico dei deploy per ognuno degli ‘environment’ configurati.
- Testing (Menu ‘Test Plans’) =>
-
-
-
- Cosa é
- Tool di gestione dei test.
- Permette di avere una vista centralizzata e unificata dei propri test. => Test automatici + Test manuali + Test Utente
- Offre la possibilità di visualizzare i ‘work item’ legati ai singoli ‘test case’.
- Test Manuali =>
- E’ possibile pianificare test manuali
- Specificare quali step fare per eseguire il test.
- Specificare il risultato previsto.
- Test Automatici =>
- Creare un nuovo progetto xUnit =>
- Aggiungervici la referenza all’applicazione che si vuole testare.
- Aggiungere Moq da Nuget.
- Creare gli unit test desiderati =>
- Creare un nuovo progetto xUnit =>
- Cosa é
-
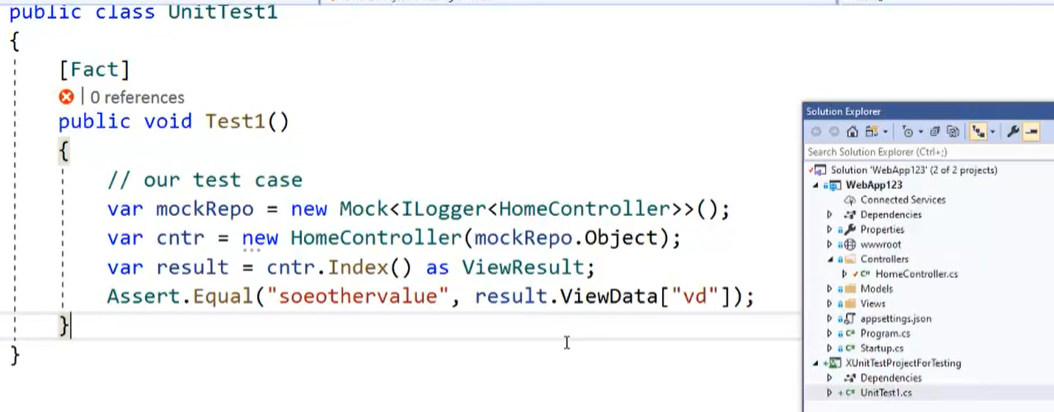
-
-
-
- Configurare il file YAML (Azure-pipelines.yml) per integrare gli unit-test =>
- Scegliere il task VSTest (Visual Studio Test) usando il form di ricerca presente a sx nella pagina di modifica del file YAML di configurazione.
- Una volta fatto il commit degli unit-test creati la pipeline eseguirà tali test.
- Configurare il file YAML (Azure-pipelines.yml) per integrare gli unit-test =>
-
-
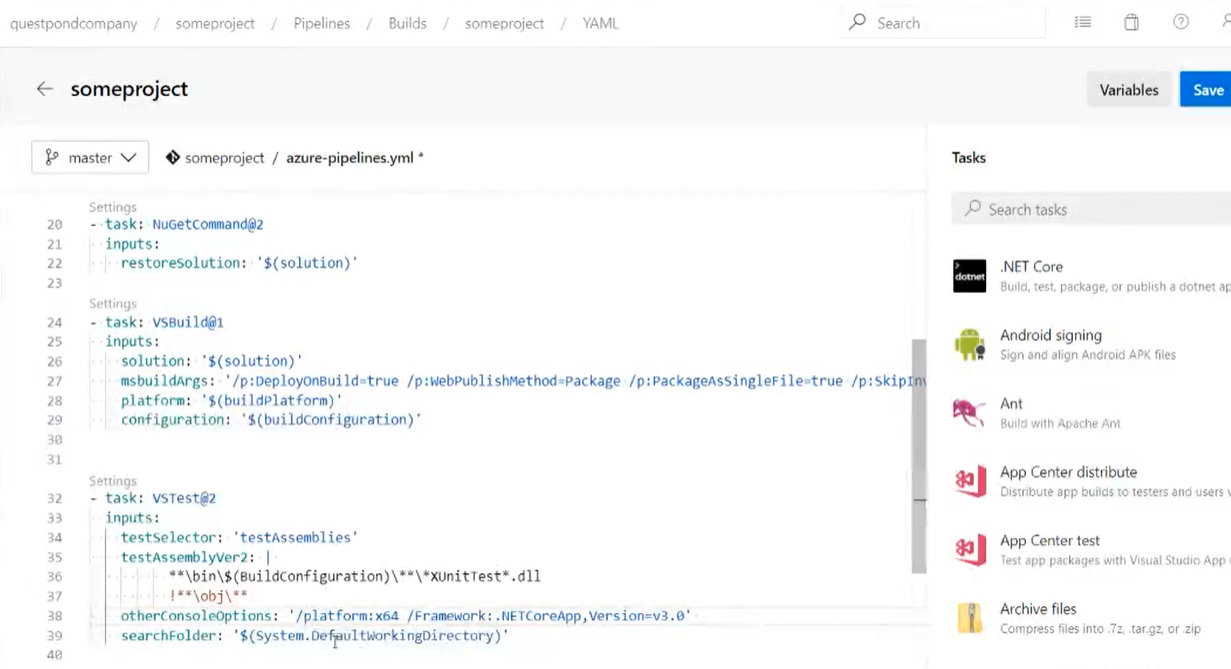
-
-
-
-
- Nei dati di configurazione del task viene indicato dove si trova la dll con il progetto di test
-
-
-
![]()
-
-
- Test reposts
- E’ possibile vedere l’esito dei test configurati nella pipeline
- Test reposts
- Artifacts =>
- Permette di memorizzare e condividere gli artifacts prodotti dalle ‘build pipeline’ già eseguite
- Sopporta packages
- nuget
- maven
- nmp
- Non gestisce le immagini docker
- Spesso gli artifacts sono delle immagini docker (dove sono stati deployati i packages) che necessitano di un repository dedicato (esterno a ‘Azure Devops’ ) per poter essere memorizzate.
-
Azure Networking (VNET)
- Creare una Virtual Network in Azure (es: 10.0.0/16) =>
-
- Nome
- Spazio degli indirizzi (IP adress and subnetting)
- IP Adress =>
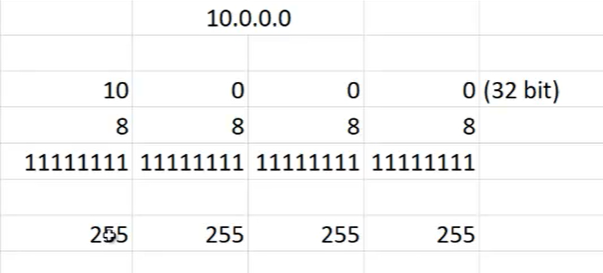
-
-
-
- permetono di identificare univocamente un computer in una rete (network)
- formato da 4 ottetti
- Subnetting (network section vs host section) => es: 10.0.0/16
- Permette di stabilire come interpretare l’indirizzo IP a 4 ottetti
- Ci dice quanti ottetti sono usati per indicare la rete e qunati per indicare i computer raggiungibili nella data rete
- 255.255.0.0 =>
- la sottorete indicata permette di stabilire che 2 ottetti indirizzano le reti e 2 ottetti indirizzano i computer nelle reti
- 65536 reti e ogni rete con 65536 computer
- 255.255.255.0 =>
- tale sottorete indica che 3 ottetti indirizzano le reti e 1 ottetto gli host
- 16777216 reti e ogni rete con 254 computer
-
-
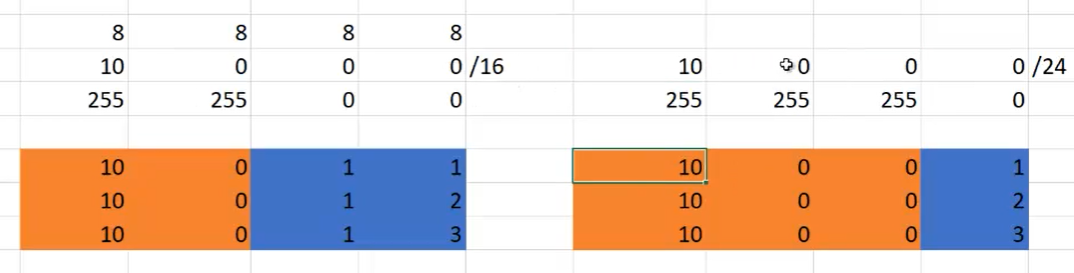
-
- Aggiungere sottoreti (es: 10.0.1.0/24) =>
- Alla rete virtuale è possibile aggiungere delle sotto reti ad esempio per isolare i vari dipartimenti della mia azienda
- Aggiungere sottoreti (es: 10.0.1.0/24) =>
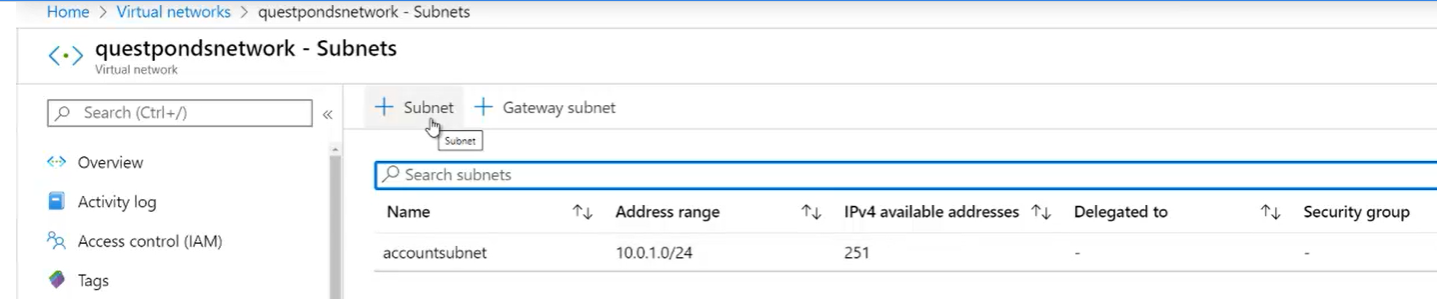
- Aggiungere VM alla Virtual Network =>
- Durante la creazione della VM è possibile indicare la Virtual Network e la sottorete di cui essa farà parte
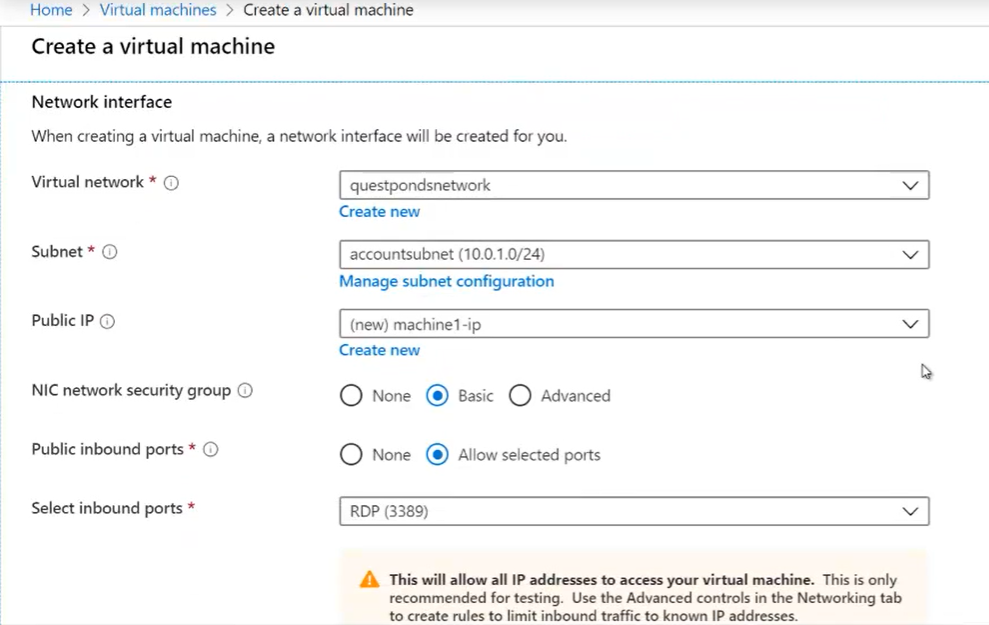
-
- Ad ogni VM creata verrà assegnato un IP
- 10.0.1.4
- 10.0.1.5
- E’ possibile comunicare tra una VM e l’altra all’interno della stessa rete
- Allow ICMP per effetturare PING =>
- Per effettuare il PING tra due VIM appartenenti alla stessa rete è necessario creare una regola di inbound nel firewall del computer pingato per permette i pacchetti ICMP
- Allow ICMP per effetturare PING =>
- Ad ogni VM creata verrà assegnato un IP
- Network Secury Group (NSG)
- E’ possibile stabilire delle regole per gestire le attività all’interno della Virtual Network valide globalmente all’interno di tutta la rete stessa.
- Queste impostazioni sovrascrivono eventuali impostazioni analoghe fatte direttamente nel firewall delle singole VM
- App Gateway
Azure Active Directory
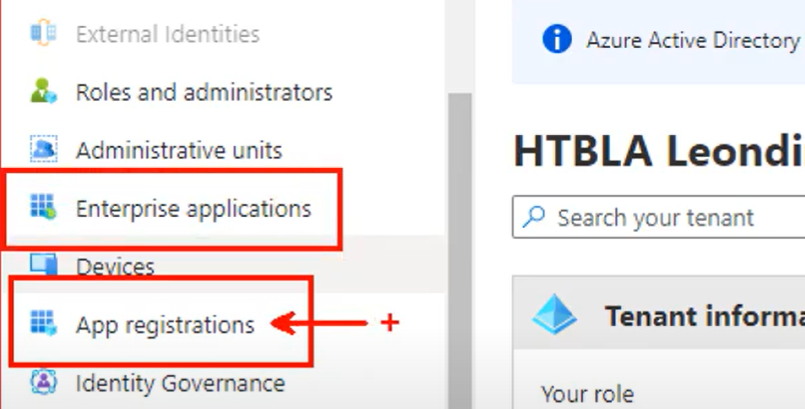
- Auth Server
- L’active directory di Azure agisce come Auth Server nel protocollo Open Id Connect (vedi approfondimento su ASP.NET)
- App registrations =>
- App client =>
- Il primo passo è registrare le app client che saranno riconosciute dall’ Auth Server.
- Chi può accedere a tale risorsa =>
- Aggiungendo una app verrà chiesto di selezionare il tipo di account scegliendo di fatto chi sarà autorizzato ad accedere a tale risorsa
- Single tentant (singolo inquilino)
- La prima opzione permetterà all’applicazione registrata di essere acceduta solo da account di una singola Azure Active Directory (AAD)/organizzazione
- Multitenant
- La seconda opzione permetterà all’applicazione registrata di essere accedura da tutti gli account di tutte le organizzazioni che usano AAD
- Single tentant (singolo inquilino)
- Aggiungendo una app verrà chiesto di selezionare il tipo di account scegliendo di fatto chi sarà autorizzato ad accedere a tale risorsa
- Chi può accedere a tale risorsa =>
- Il primo passo è registrare le app client che saranno riconosciute dall’ Auth Server.
- App client =>
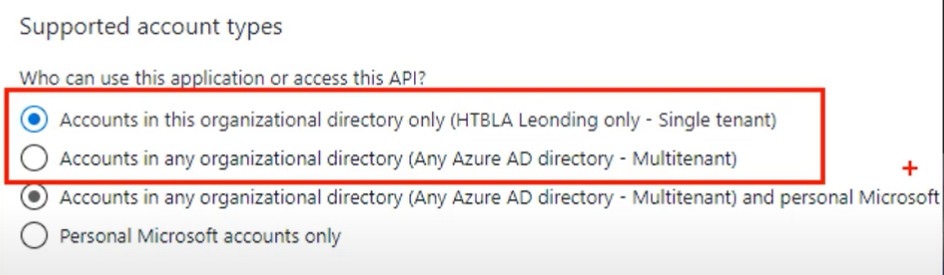
-
-
-
- Application Client ID
- Dopo la registrazione l’Auth Server restituisce l’ identificativo univoco dell’applicazione client
- Application Client ID
-
-
-
-
-
- Tenant ID
- Ogni organizzazione che usa l’ AAD è un proprio identificativo univoco
- E’ tipico di un’organizzazione (es: azienda o università) e di un sistema B2B
- Per sistemi B2C normalmente non c’è bisogno di un Tenant ID, solamente user e psw
- Tenant ID
- Authentication =>
- Dall’app che abbiamo registrato aprire il menù ‘Authentication’
-
-
-
-
-
- Add a platform
- Indicare il tipo di applicazione (web app, mobile app, single page application) che avrà accesso al nostro ‘Auth Server’
- Redirect url (campo facoltativo)
- Nel caso non si voglia far apparire un popup (domandando le credenziali di accesso al nostro utente finale) o magari perché sappiamo che le popup per il nostro utente sono disattivate allora è possibile indicare una pagina dove reindirizzare il nostro utente
- Sarà allora da questa pagina che il nostro utente ricevera l’access token dall’ ‘Auth Server’
- esempio: localhost:4200
- Authorization Code Flow with PKCE
- E’ l’attuale e più diffuso flusso di operazioni per l’autenticazione di una single page application
- Add a platform
- API Permissions =>
- E’ possibile autorizzare l’app client che stiamo registrando ad accedere a certe API fornite nativamente dall’AAC
- Tali API permettono di interoggare i dati presenti in Azure
-
-
-
-
-
- Microsoft Graph => User.Read
- Di default tutte le client app registrate hanno l’atorizzazione di fare il sign in e di leggere le informazioni del profilo dell’utente finale
- Microsoft Graph => User.Read
-
-
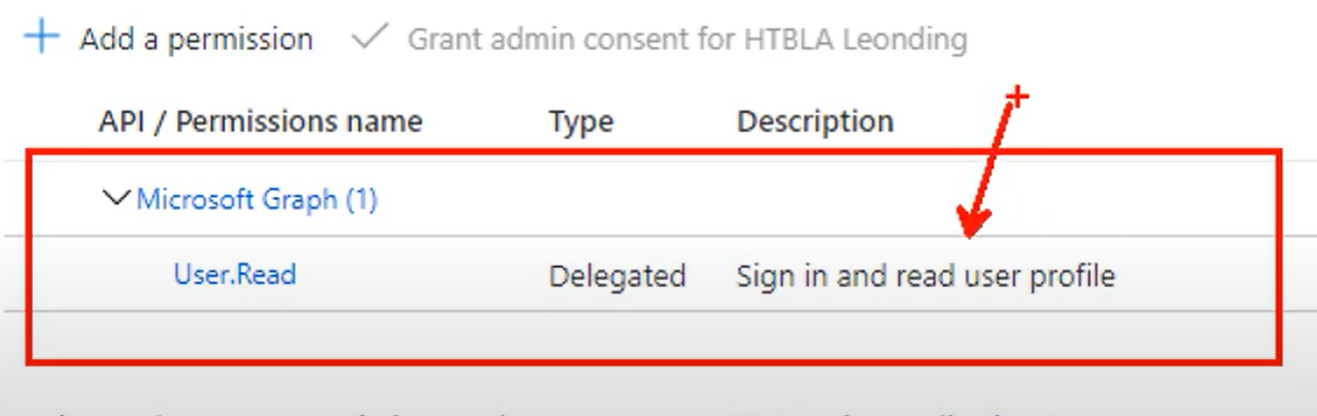
-
-
-
- Microsoft Graph Explorer
- Portale offerto da Microsoft per poter costruire la propria API con le informazioni del profilo Azure desiderate
- Microsoft Graph Explorer
-
-
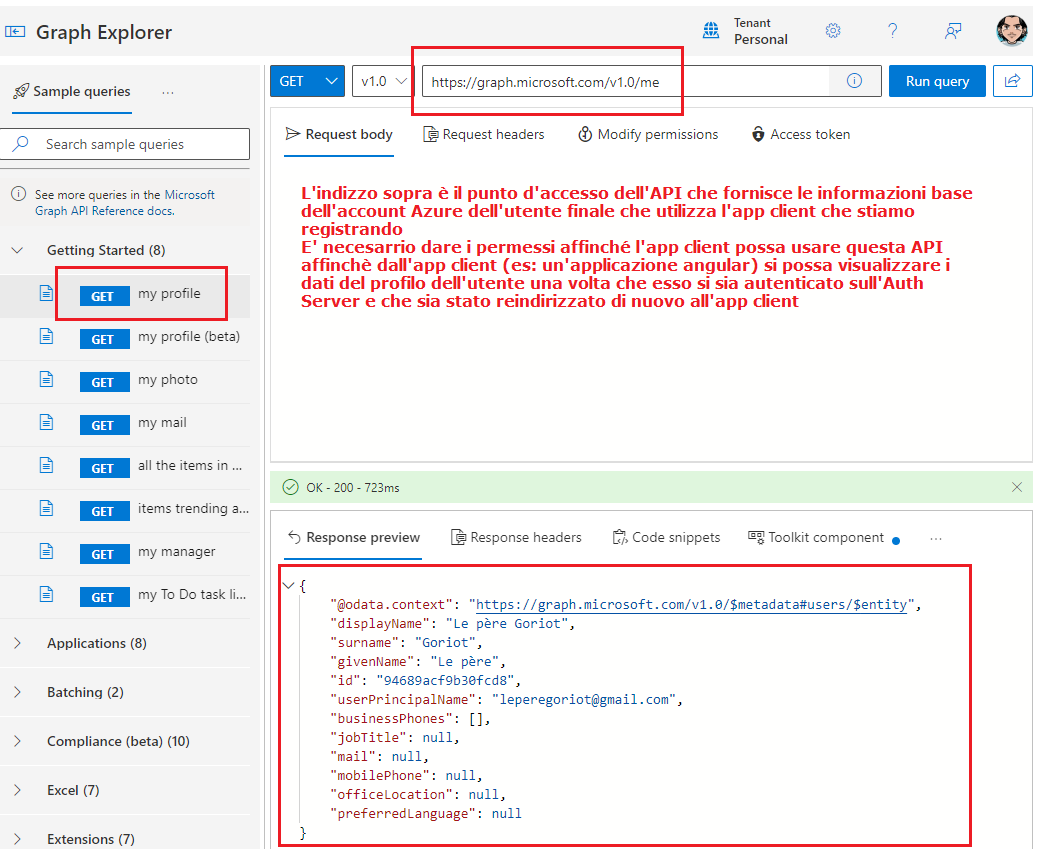
-
-
-
- Aggiungere una nuova permission
- Scegliere il tipo di permission che l’app client puo acquisire
- Delegated permissions
- L’utente finale delega l’app client ad accedere ad alcune informazioni del proprio profilo Azure (tramite API)
- L’utente finale sarà avvisato che loggandosi darà accesso all’app client che sta usando alle permissions che sono state settate per essa
- nell’esempio in basso sarà avvisato che l’app client avrà le permission ‘User.Read’ e ‘User.ReadBasic.All’
- E’ esattamente quello che succede quando si cerca di installare un’app di Android. Spesso appare un piccolo popup che ci avvisa quali permessi l’app acquisirà se la installiamo
- Application permissions
- E’ l’applicazione stessa che ha i permessi di accedere alle informazioni desiderate.
- Non c’è il passaggio verso nessun utente finale
- Delegated permissions
- Scegliere le permission dalla lista visualizzata che l’app client si vuole acquisisca e cliccare ‘Add permissions’
- Scegliere il tipo di permission che l’app client puo acquisire
- Aggiungere una nuova permission
-
-
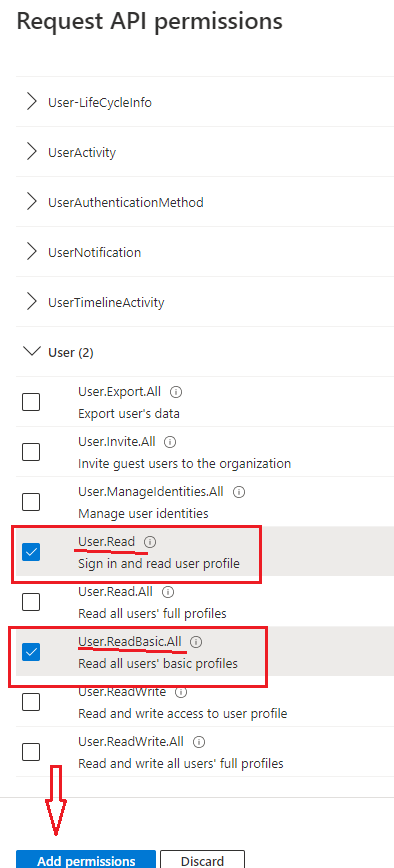
-
-
-
- Lista delle permissions dopo aver aggiunto ‘User.ReadBasic.All’
-
-

-
- Custom API (la risorsa protetta)
- Il secondo passo è registrare l’API che si vuole accedere
- Expose an API
- E’ necessario settare un application id uri (un’identificativo univoco per riferenziare l’API)
- Add a scope
- Aggiungere quali permerssi dare all’app che accederà all’API
- Custom API (la risorsa protetta)
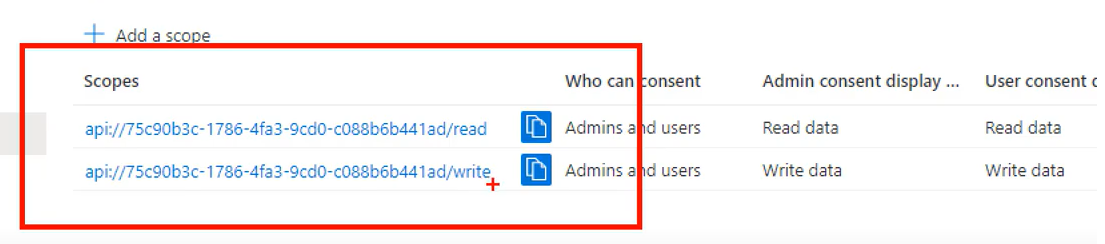
-
-
- Tornare all’app registration dell’app client che abbiamo registrato precedentemente
- Aggiungere la permission alla custom API che stiamo registrando
- Tornare all’app registration dell’app client che abbiamo registrato precedentemente
-