
- Differenze con .NET
- Java Fundamental
- Maven
- Apache Tomcat
- Spring Fundamental
- Spring Ioc Container
- Spring Librerie
- Spring REST API
- Spring Data
- ORM Hibernate
- Hibernate – Problematiche di produzione
- Risorse
Differenze con .NET
- .dll (IL) = .jar (byte code) (contiene file .class che sono il risultato della compilazione di file .java)
- ..JAR (Java Archive)
- Puo’ essere usato come un’alternativa a .zip
- Spesso serve per distribuire versioni binarie delle librerie (file .class compressi) ed eventuali file “resources” aggiuntivi da esse utilizzati.
- E’ possibile creare un file .jar tramite il comando jar o tool come Maven.
-
//tipica struttura di une file JAR META-INF/ (cartella privata) MANIFEST.MF //puo' contenere metadata aggiuntivi sui file presenti nel file .jar com/ baeldung/ MyApplication.class
-
- .WAR (Web application Archive)
- Sono usati per creare un package contenente applicazioni web che possono essere deploiare su qualsiasi container Servlet/JSP
-
//tipica struttura di une file WAR META-INF/ (cartella privata) MANIFEST.MF //puo' contenere metadata aggiuntivi sui file presenti nel file .war WEB-INF/ (cartella publica con risorse statiche, classi servlet e libraries) web.xml jsp/ helloWorld.jsp //Java server page classes/ static/ templates/ application.properties lib/ // *.jar files as libs
-
- Sono usati per creare un package contenente applicazioni web che possono essere deploiare su qualsiasi container Servlet/JSP
- Classpath (no assembly-cache)
- Spesso bisogna aiutare Java a trovare tutti i file JAR che si stanno utilizzando costruendo un classpath ad ogni build o run.
Java Fundamental
- Java Environment
- JDK (JRE + Java Compiler + Debugger + Core classes)
- Java Development Kit.
- Fornisce tutti i tools, gli eseguibili e le librerie richieste per compilare, debuggare e eseguire un programma Java.
- JShell
- E’ specifico alla piattaforma in cui si installa (Windows,Mac, Linux)
- Da installare su un computer di sviluppo.
- In Windows settare variabili d’ambiente
- Crea JAVA_HOME = C:\Program Files\Java\jdk1.8.0_202
- Aggiungi a PATH = C:\Program Files\Java\jdk1.8.0_202\bin
-
C:>javac -version //javac 1.8.9_291
- JVM (equivalente della .NET CLR)
- Java Virtual Machine.
- JIT (Just-in-time Compiler)
- E’ personalizzabile.
- Virtuale perché fornisce un supporto per eseguire ogni programma Java indipendentemente dalla piattaforma.
- Fornisce funzionalità chiave come: memory management, garbage collection, sicurezza.
- L’installazione é specifica alla piattaforma in cui si installa (Windows,Mac, Linux).
- JRE (JVM + Java binaries + other classes)
- E’ l’implementazione della JVM.
- Permette di eseguire ogni programma Java.
- Da installare sul server di produzione.
- JDK (JRE + Java Compiler + Debugger + Core classes)
- Access modifier
- Final
- Equivalente di Final in C#
-
- Final class => Sealed - Final method => Sealed - Final field => Readonly //Definendo una variabile locale (es: in un if-else) significa che prima di essere letta le deve essere assegnato un valore - local variable or method parameter => nessun equivalente in C#
-
- Equivalente di Final in C#
- Final
- Enum
-
//metodo classico public enum Color { green, red, yellow } public class Car { @Enumerated(EnumType.String) private Color color; } //metodo con converter public enum Color { green(1, "the car is green"), red(2, "the car is red"), yellow(3, "the car is yellow"); private Integer key; private String description; Color(Integer key, String description) { this.key = key; this.description = description; } } public class Car { private Color color; } @Converter(autoApply = true) public class ColorAttributeConverter implements AttributeConverter<Color, Integer> { @Override public Integer convertToDatabaseColumn(Color attribute) { //from enum to integer before storing into DB return attribute != null ? attribute.getKey(): null; } @Override public Certification convertToEntityAttribute(Integer dbData) { return Stream.of(Color.values()) .filter(item -> item.getKey().equals(dbData)) .findFirst().orElse(null); } }
-
Maven
- Permette di fare il build di progetti JAVA.
- Goals => E’ possibile eseguire differenti “goals” durante il build
- Compilare il progetto
- Creare un package (file JAR o WAR)
- Installare delle librerie nel repository locale delle dependency.
- In Windows settare variabili d’ambiente
- Aggiungi a PATH = C:\apache-maven-3.9.1\bin
- In Windows settare variabili d’ambiente
- Crea MAVEN_HOME = C:\apache-maven-3.9.1
-
mvn -v //version di Maven installata //Da eseguire nella stessa cartella dove é presente il file Pom.xml //Lancia i differenti golas definiti nel Pom.xml //lancia il build del nostro progetto e crea i file .class nella cartella => ./target/classes/.class //[-e, visualizza dettaglio in caso di errori] //[-X, per abilitare il logging] mvn compile [-e] [-X] // compila // lancia test // creare il package JAR nella directory ./target oppure //creare il package WAR nella directory ./ //il nome del package é basato su <artifactId> e <version> mvn package //eseguo il file appena creato java -jar target/my-projet-1.0.0.jar //Maven gestisce un repository delle dependency in locale (.m2/repository directory) affinché il progetto possa usarle rapidamente //compile + test + package + copia il package nella cartella locale delle dependency. //cosi facendo un altro progetto puo' referenziare il nostro progetto. mvn install
- Pom.xml => File di definizione di un progetto Maven
<modelVersion>. POM model version (always 4.0.0).<groupId>. Group or organization that the project belongs to. Often expressed as an inverted domain name.<artifactId>. Name to be given to the project’s library artifact (for example, the name of its JAR or WAR file).<version>. Version of the project that is being built.<packaging>– How the project should be packaged. Defaults to “jar” for JAR file packaging. Use “war” for WAR file packaging.-
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> //sempre 4.0.0 <groupId>it.richlab</groupId> //la mia organizzazione all'inverso <artifactId>my-project</artifactId> //farà parte del nome del package livrabile <packaging>jar</packaging> //definisce il tipo di package creato dalla compilazione <version>0.1.0</version> //farà parte del nome del package livrabile <properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> </properties> <modules> <module>nonrest</module> <module>rest</module> <modules> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.2.4</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>hello.HelloWorld</mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
- Aggiungere delle dipendenze esterne
- Se nelle nostre classi Java si usano delle librerie esterne, queste devono essere aggiunte nel file Pom.xml nel nodo <dependencies>
- Il nodo <scope> é opzionale se il suo valore é compile [default]
- provided = dipendenze necessarie solo in compilazione (a runtime sono fornite dal container che esegue il codice).
- test = dipendenze necessarie solo in compilazione e esecuzione dei test ma non in produzione.
- compile: valore di default, la dipendenza con questo scope sarà disponibile sia in
src/mainche insrc/test - test: la dipendenza é disponibile solo in
src/test - provided: simile a compile ma la dipendenza é fornita da JDK o un container a runtime
- runtime: la dipendenza non é richiesta in compilazione ma solo a runtime
- system: simile a “provided” ma é necessario fornire il JAR che contiene la dipendenza specifica
- <systemPath>path/some.jar</systemPath>
- import: disponibile per
<type>pom</type>e dovrebbe essere rimpiazzato dalla dipendenza effettiva presente in<dependencyManagement/>
-
<dependencies> <dependency> <groupId>joda-time</groupId> <artifactId>joda-time</artifactId> <version>2.9.2</version> </dependency> <dependency> <groupId>joda-time</groupId> <artifactId>joda-time</artifactId> <version>2.9.2</version> <scope>test</scope> </dependencies>
- Eseguire i test
- Maven usa un plugin chiamato “surefire” per eseguire i test.
- La configurazione di default compila e eseguie tutte le classi in
src/test/javacon un nome*Test. - Il metodo di test deve essere decorato con @Test
-
//src/test/java/hello/GreeterTest.java package hello; import static org.assertj.coe.api.Assertions.assertThat; import static org.hamcrest.CoreMatchers.containsString; import static org.junit.Assert.*; import org.junit.Test; public class GreeterTest { private Greeter greeter = new Greeter(); @Test public void greeterSaysHello() { assertThat(greeter.sayHello(), containsString("Hello")); assertThat(movie.getName()).as(description: "got bad movie").isEqualto(expected: "Rocky IV"); } } //per lanciare i test mvn test
- IntelliJ IDEA
- Dopo una modifica a pom.xml
- Aprire la finestra di gestione di “Maven”
- View -> Tool Windows -> aprire la finestra di gestione di “Maven”.
- Lanciare il reload del progetto cliccando sull’icona “refresh”.
- Dopodiché eseguire “install”.
- Aprire la finestra di gestione di “Maven”
- Dopo una modifica a pom.xml
Gradle
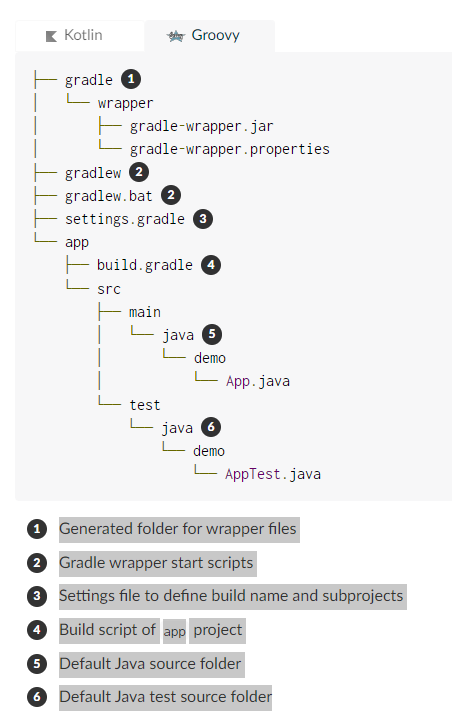
- Ricordarsi di aggiungere il PATH alla cartella /bin di dove è installato Gradle nella system enviroment variable PATH.
- gradle init
Apache Tomcat
- Installare Apache Tomcat 9.0.73 in locale (fare il download dell’ultima versione)
- Configurare IntelliJ per utilizzare l’istanza appena installata
- Run -> Edit Configurations -> + -> Aggiungere nuova configurazione -> Selezionare TomCat server
- Posizionarsi sulla nuova voce ‘Tomcat Seerver’ -> Selezionzionare la propria applicazione
- Tab ‘Server’ ->
- Configure -> Indicare il path del server nel computer locale.
- Url -> Scegliere a quale indirizzo la nostra applicazione risponde.
- Tab ‘Deployment’ -> Selezionare ‘Artifact’ -> indicarne il path (normalmente presente nella cartella /target)
- Se non c’é bisogna configurare il pom.xml
- Nel file pom.xml aggiungere vicino a <artifactId> il nuovo tag <packaging>war</paclaging> se non già presente.
-
<project> ... <artifacId>..</artifactId> <packaging>war</packaging> ... </project>
- Se non c’é bisogna configurare il pom.xml
- ServletInitializer
- Per packaging war é necessario aggiungere il Servlet Initializer alla nostra applicazione
-
import org.springframework.boot.builder.SpringApplicationBuilder; import org.springframework.boot.web.servlet.support.SpringBootServletInitializer; public class ServletInitializer extends SpringBootServletInitializer { @Override protected SpringApplicationBuilder configure(SpringApplicationBuilder application) { return application.sources(DemoApplication.class); } }
- Tab ‘Server’ ->
- Configurare il server manager
- tomcat-users.xml
-
Aprire il file C:\apache-tomcat-9.0.73\conf\tomcat-users.xml <tomcat-users> <role rolename="manager-gui"/> <role rolename="manager-script"/> <user username="tomcatgui" password="tomcatgui" roles="manager-gui"/> <user username="tomcattext" password="tomcattext" roles="manager-script"/> </tomcat-users>
-
- tomcat-users.xml
- Aprire la console di management
-
http://localhost:8080/manager/html
-
Spring Fundamental
- Spring é un framework per Java open source con il quale é possibile creare:
- Microservice
- Reactive (programmazione asincrona)
- Cloud
- Applicazioni web
- Organizzazione progetto web
- Controller
- I controller raggruppano gli end-point
- Espongono i dto
- Utilizzano i manager per richiamare la business logic
-
import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; @RestController public class MyController { @GetMapping("/myapi") public myapi mypapi(){} }
- Dto
- Entità esposte all’esterno.
- Spesso un sottoinsieme delle “Entity”.
- Manager
- I manager contengono la business logic dell’applicazione.
- Nella creazion della business logic richiamano i diversi “service”.
-
import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Component; @Component public class MyManager { .. }
- Service
- I service utilizzano i repository per esporre le operazioni CRUD e di interazione con il data layer.
-
import org.springframework.stereotype.Service; @Service public class MyService { .. }
- Repository (interagisce con il Dao)
- I repository ragruppano le operazioni Dao
- Dao (interagiste con il data layer per la persistenza dei dati, es: hiberate)
- Entity (raggruppa il business model dell’applicazione)
- Controller
-
//file system /src /test/java/<my-package-name> /main /resources /java/<my-package-name> /controller /dto /manager /service /repository /dao /entity
- Organizzazione progetto web
- Serverless (Scale-up on demand)
- Event Driven
- Batch (esecuzione automatica di task)
-
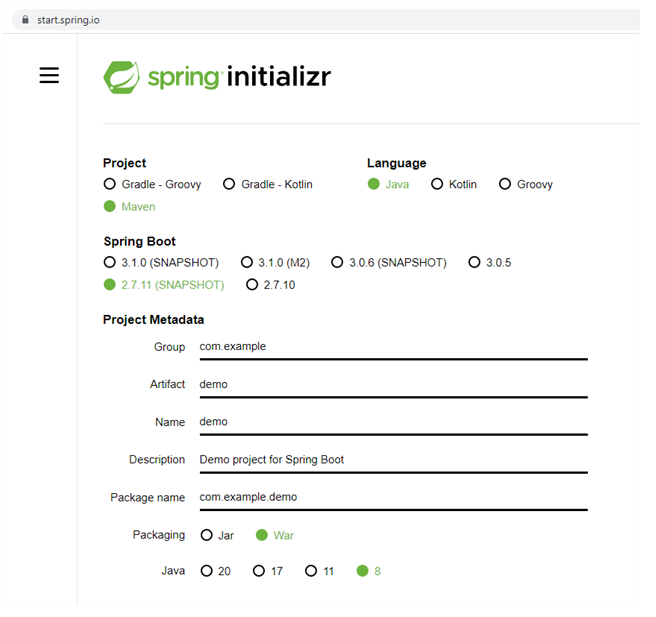
- Spring initializr (Inizializzare un progetto spring boot))
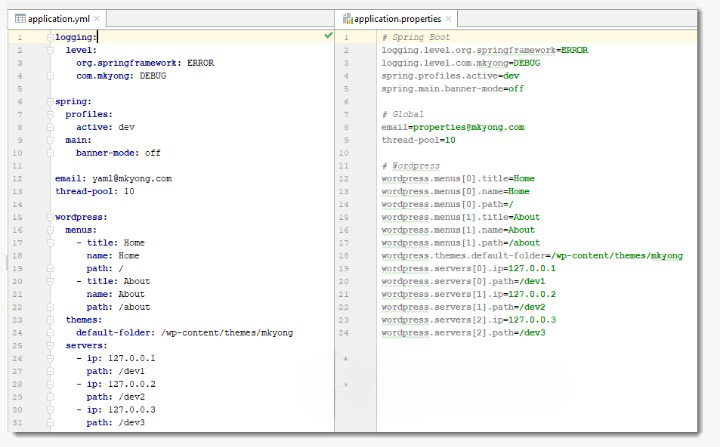
- Configurazione in Spring (application.properties vs application.xml)
-
-
- application.properties
-
//L'uso di ‘#---' indica dove vogliamo dividere il documento //Nell'esempio dotto Spring interpreta 2 sezioni con profili differenti logging.file.name=myapplication.log bael.property=defaultValue application.servers[0].ip=127.0.0.1 application.servers[0].path=/path1 application.servers[1].ip=127.0.0.2 application.servers[1].path=/path2 #--- spring.config.activate.on-profile=dev spring.datasource.password=password spring.datasource.url=jdbc:h2:dev spring.datasource.username=SA bael.property=devValue #--- spring.config.activate.on-profile=prod spring.datasource.password=password spring.datasource.url=jdbc:h2:prod spring.datasource.username=prodUser bael.property=prodValue
-
- application.xml
-
//In questo caso, l'uso di ‘---' indica dove vogliamo dividere il documento application: servers: - ip: '127.0.0.1' path: '/path1' - ip: '127.0.0.2' path: '/path2' logging: file: name: myapplication.log --- spring: config: activate: on-profile: dev datasource: password: 'password' url: jdbc:h2:dev username: SA bael: property: devValue --- spring: config: activate: on-profile: prod datasource: password: 'password' url: jdbc:h2:prod username: prodUser bael: property: prodValue
-
- Leggere la configurazione
- @Value
- Questa annotazione é usata per assegnare valori di default a variabili o argomenti di metodi.
- E’ possibile leggere variabili d’ambiente Spring (es: “application.properties”) cosi come variabili di sistema usando questa annotazione
-
//Spring Expression Language (SpEL) @Value({spring.datasource.url}) privat String url; @Value("${APP_NAME_NOT_FOUND}") private String defaultAppName; @Value("${java.home}") private String javaHome; @Value("classpath:<my-folder>/<my-file>") private Resource my-resource;
- Environment abstraction
-
@Autowired private Environment env; public String getSomeKey(){ return env.getProperty("spring.datasource.url"); }
-
- @ConfigurationProprerties
-
@ConfigurationProperties(prefix = "mail") public class ConfigProperties { String name; String description;
-
- @Value
- application.properties
-
Spring IoC Container
- @Bean
- Un bean é un oggetto aggiunto al IoC container di Spring.
- Il comando @Bean é usato per dichiarare esplicitamente un singolo “bean”.
- Permette di “componentizzare” una classe della quale non si ha il codice sorgente.
- Permette disaccoppaire la dichiarazione di un “bean” dalla classe che lo definisce.
- Permette di rendere disponibile all’application context un classe di terze-parti.
- Generazione dei bean
- (metodo automatico) Creando una classe con l’annotazione @Component
- Una volta che l’applicazione Spring viene eseguita, ogni classe con l’annotazione
@ComponentScanfa lo scan di ognuna dele proprie classi con@Component - Ne fa poi il restore delle istanze nel container IoC
- Una volta che l’applicazione Spring viene eseguita, ogni classe con l’annotazione
- (metodo manuale) Creondo un metodo con l’annotazione @Bean
- Le classi che contengono dei metodi che usano @Bean dovrebbero essere annotate
@Configuration. - L’annotazione
@ComponentScanesegue anche tutti i metodi con @Bean. - Ne fa poi il restore delle istanze nel context dell’applicazione.
- Le classi che contengono dei metodi che usano @Bean dovrebbero essere annotate
- (metodo automatico) Creando una classe con l’annotazione @Component
- Classe config
-
@Configuration @ComponentScan(basePackageClasses = Company.class) public class Config { @Bean public Address getAddress() { return new Address("High Street", 1000); } }
-
- Classe context
-
ApplicationContext context = new AnnotationConfigApplicationContext(Config.class);
-
- @SpringBootApplication = @EnableAutoConfiguration + @Configuration + @ComponentScan
- @EnableAutoConfiguration
- Permette di attiva/disattivare la funzionalità di auto-configurazione in un’applicazione “Spring”.
- Dice a Spring Boot di iniziare ad aggiungere i beans sulla base dei “classpath” configurati nel file pom.xml
- Tenta infatti di configurare automaticamente la nostra applicazione in base alle dipendenze che sono state definite.
- Per esempio se esiste una dipendenza a
HSQLDBe non si é ancora definito manualemente la connessione (tramite @bean) allora Spring Boot auto configura un in-memory database.
- Per esempio se esiste una dipendenza a
- Permette di attiva/disattivare la funzionalità di auto-configurazione in un’applicazione “Spring”.
- @ComponentScan
- Attiviva lo scan degli attributi @Component nel package dell’applicazione.
- @Component
-
@Component class User { } // to get Bean @Autowired User user; - Puo’ essere usato per auto-detect e auto-configurigurare “beans” a partire della dipendenze definite nel progetto.
- @Component ha diverse specializzazione come:
- @Controller
- @Repository
- @Service
- Posso definire dei “bean” senza l’uso di @Configuration.
-
- @Configuration
- Permette di registrare altri @Beans nel context o in classi di configurazione addizionali.
-
@Configuration class MyConfiguration{ @Bean public User getUser() { return new User(); } } class User{ } // Getting Bean User user = applicationContext.getBean("getUser")
-
package com.example.myapplication; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; //@EnableAutoConfiguration //@Configuration //@ComponentScan @SpringBootApplication public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } }
- @EnableAutoConfiguration
- Come usare la dependency injection
-
import org.springframework.beans.facotry.annotation.Autowired; public class MyClass { @Autowired MyInjectedClass injectedClass; public MyClass(MyInjectedClass pInjectedClass) { this.injectedClass = pInjectedClass } }
-
Spring Librerie
- spring-boot-starter-web
-
contiene le seguenti dipendenze spring web: - spring-boot-starter - jackson - spring-core - spring-mvc - spring-boot-starter-tomcat
-
- spring-boot-starter-tomcat
-
//contiene ogni cosa correlata ad un tomcat server embedded: core el logging (logback) websocket
- Come configurare logback
- application.properties
-
logging.level.org.springframework.web=DEBUG logging.level.org.hibernate=ERROR
-
- Oppure aggiungere il file di configurazione di logback.xml nella cartella “resources” del nostro progetto:
-
//logback.xml <?xml version="1.0" encoding="UTF-8"?> <configuration> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <encoder> <pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern> </encoder> </appender> <logger name="org.hibernate.SQL" level="DEBUG" /> <logger name="org.hibernate.type.descriptor.sql.BasicBinder level="DEBUG" /> //log params value in autogenerated Hibernate SQL statement <logger name="com.<my-projet>.<my-package>" level="TRACE" /> //log <my-package> <logger name="org.springframework.orm.jpa.JpaTransactionManager" level="DEBUG" /> //log Hibernate transaction manager <logger name="org.hibernate.internal.SessionImpl" level="DEBUG" /> //log Hibernate session manager <root level="WARN"> <appender-ref ref="STDOUT" /> </root> </configuration> - Loggare le query generate da Hibernate + i parametri valorizzati
-
<logger name="org.hibernate.SQL" level="DEBUG" /> <logger name="org.hibernate.type.descriptor.sql.BasicBinder level="DEBUG" />
-
-
- application.properties
-
- spring-boot-starter-security
-
Permette di securizzare tutti gli endpoint by default usando httpBasic oppure formLogin
-
- Database
- com.h2database.h2
-
//da usare con spring-boot-starter-data-jpa //application.yaml spring: datasource: url: jdbc:h2:mem:mydb username: sa password: password driverClassName: org.h2.Driver jpa: spring.jpa.database-platform: org.hibernate.dialect.H2Dialect - Precaricare dei dati in H2
- Recuperare dalla classe di configurazione del livello di persistenza i metodi datasource() e il transactionManager()
- Creare uno script sql con le query che si vogliono eseguire per riempiere il nostro db H2 (es: /data/fill.sql).
- Aggiungere alla nostra classe di test le 2 seguenti annotazioni:
-
@SqlConfig(dataSource = "dataSourceH2", transactionManager = "transactionManager") @Sql({ "/data/fill.sql" }) public class MyTest { }
-
-
- spring-boot-starter-data-jdbc (JDBC)
- Un applicazione usa le API offerte da questa libreria per comunicare con il JDBC manager
- Permette di scrivere direttamente nell’applicazione gli statement SQL necessari per leggere o modificare i dati del DB.
- E’ dipendente dal DB.
- La transazione é gestita esplicitamente con l’uso di commit e rollback.
-
//Questa annotazione indica a Spring quale costruttore utilizzare per materializzare la data tabella del DB in un oggetto //nel caso tale oggetto abbia più di un costruttore @PersistenceCreator
- spring-boot-starter-data-jpa (JPA)
- Permette di fare bind di oggetti Java con un database relazionale. E’ uno dei possibili approcci al ORM.
- Permette di usare delle annotzioni per describere come la data classe Java si mappa sulla data tabella.
- La transazione é implicita.
- Le applicazoni basate su JPA usano in effetti JDBC negli strati inferiori:
- In altri termini JPA agisce da livello di astrazione che nasconde allo sviluppatore le chiamate interne a JDBC rendendo l’iterazione con il DB molto più semplice.
- E’ indipendente dal DB.
- javax.persistence package.
- Usa Java Persistence Query Language (JPQL) per interrogare il DB.
- Per interagire con le entity usa EntityManagerFactory. Questa restituisce un EntityManager che realizza le oerazioni CRUD sulle istanze.
-
@Entity @Table(name = "employee") public class Employee implements Serializable { @Column(name = "employee_name") private String employeeName; } -
//definire relazione 1-a-molti tra la tabella "employee" e "communication" @Entity @Table(name = "employee") public class Employee implements Serializable { @OneToMany(mappedBy = "employee", fetch = FetchType.EAGER) @OrderBy("firstName asc") private Set communications; }
- org.hibernate (Hibernate)
- La principale differenza conn JPA è che Hibernate è un framework mentre JPA è una specifica API.
- Hibernate è l’implementazione di tutte le linee guida JPA.
- E’ un Object-Relational Mapping (ORM) usato per salvare oggetti Java in DB relazionale.
- Usa Hibernate Query Language (HQL) per interrogare il DB.
- Per interagire con le entity usa la SessionFactory. Questa restituisce un’interfaccia Session che agisce come un’interfaccia a runtime tra l’applicatione Java e Hibernate.
-
<dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-core</artifactId> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-orm</artifactId> </dependency>
- com.h2database.h2
- org.springdoc vs io.springfox
- Per poter aggiungere automaticamente Swagger alle nostre REST API in un progetto Spring é possibile usare la vecchia libreria “springfox” oppure sostituirla con la nuova “org.springdoc” che supporta OpenAPI 3.0.
- SpringDoc
-
//aggiungere la libreria SpringDoc <dependency> <groupId>org.springdoc</groupId> <artifactId>springdoc-openapi-ui</artifactId> <version>1.6.4</version> </dependency>
- URL specifiche OpenAPI 3.0 degli endpoins della nostra applicazione Spring
-
//JSon http://<my-url>/v3/api-docs //Yaml http://<my-url>/v3/api-docs.yaml
-
- Customizzazione dell’ URL
-
//Settare il nuovo path nel file "application.properties" springdoc.api-docs.path=<my-new-path> (es: /api-docs)
-
- URL interfaccia Swagger
-
http://localhost:8080/swagger-ui.html
-
- Swagger-UI properties
-
//Sempre nel file "application.properties" é possibile aggiungere delle entry per customizzare l'interfaccia Swagger springdoc.swagger-ui.path=/swagger-ui-custom.html springdoc.swagger-ui.operationsSorter=method
-
-
-
spring-boot-starter-actuator
- In sostanza, Actuator aggiunge delle funzionalità alla nostra applicazione per monitorare le prestazioni in un ambiente di produzione.
- Monitorare la nostra app, raccogliere metriche, comprendere il traffico o lo stato del nostro database diventa banale con questa dipendenza.
-
spring-boot-starter-test
- /src/test/java/<my-app>
- Le classi devono contenere la parola test
-
//contiene le seguenti librerie - org.jUnit //de-facto standard per unit testing in applicazioni Java - Spring Test & Spring Boot Test //Utilities e test d'integrazione per applicazioni Spring Boot applications - AssertJ //Fluent assertion library - Hamcrest //Una libreria per oggetti matcher objects - Mockito //Mocking framework per Java - JSONassert //Assertion library per JSON - JsonPath //XPath per JSON
-
spring-boot-starter-hateoas
- Permette di scrivere output hypermedia-driven (rendendo le nostri API RESTful)
-
org.slf4j
- Libreria per il logging
-
public class MyClass { private static final Logger LOGGER = LoggerFactory.getLogger(MyClass.class); public void MyMethod() { LOGGER.trace("writing here my trace..."); LOGGER.info("writing here my info..."); } }
- org.apache.commons
- Libreria per implementazione delle “tuple”
-
<dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> </dependency>
- com.zaxxer.HikariCP
- Pool di connessioni
-
<dependency> <groupId>com.zaxxer</groupId> <artifactId>HikariCP</artifactId> </dependency> //classe PersistenceConfig //attivo il pool id connessioni @Bean public DataSource dataSource() { DataSourceBuilder<?> dataSourceBuilder = DataSourceBuilder .create() .driverClassName(env.getProperty("jdbc.postgres.driver-class-name")) .username(env.getProperty("jdbc.postgres.username")) .password(env.getProperty("jdbc.postgres.password")) .url(env.getProperty("jdbc.postgres.connection-url")); return dataSourceBuilder.build(); }
Spring REST API
- Controller
- @RestController
- Indica che i dati restituiti da ciascun metodo (della classe a cui si applica tale annoazione) verranno scritti direttamente nel “body” della “HTTP Response” invece di eseguire il rendering dei dati.
-
@RestController @RequestMapping("/api/book") public class BookController { @Autowired private BookRepository repository; //Caso senza QUERYSTRING //http://<my-site>/apoi/book/{id} @GetMapping("/{id}") public Book findById(@PathVariable long id) { return repository.findById(id) .orElseThrow(() -> new BookNotFoundException()); } //Caso con QUERYSTRING //http://<my-site>/api/book/searchByName=?name=<valore> @GetMapping("/searchByName") public Book findByName(@ModelAttribute("name") String name) { } @GetMapping("/") public Collection<Book> findBooks() { return repository.getBooks(); } @PutMapping("/{id}") @ResponseStatus(HttpStatus.OK) public Book updateBook(@PathVariable("id") final String id, @RequestBody final Book book) { return book; } }
- @RestController
Spring Data
- dd
ORM Hibernate
- Glossario
- JPA é un insieme di linee guida (la specificazione)/
- Hibernate é un’implementazione delle specifiche JPA.
- Spring Data é uno strato aggiuntivo cje integra hiberante in Spring. Non necessario per poter utilizzare Hibernate in un progetto.
- 3 Regole d’oro
- Conoscere lo stato della sessione (@PersistenceContext).
- Sapere se siamo o non siamo in una sessione.
- Un oggetto é nella sessione di Hibernate se é nel map Hibernate la cui chiave é l’id dell’oggetto + il nome della classe dell’oggetto.
- Sapere se siamo o non siamo in una transazione.
- Verificare il SQL generato da Hibernate
- Conoscere lo stato della sessione (@PersistenceContext).
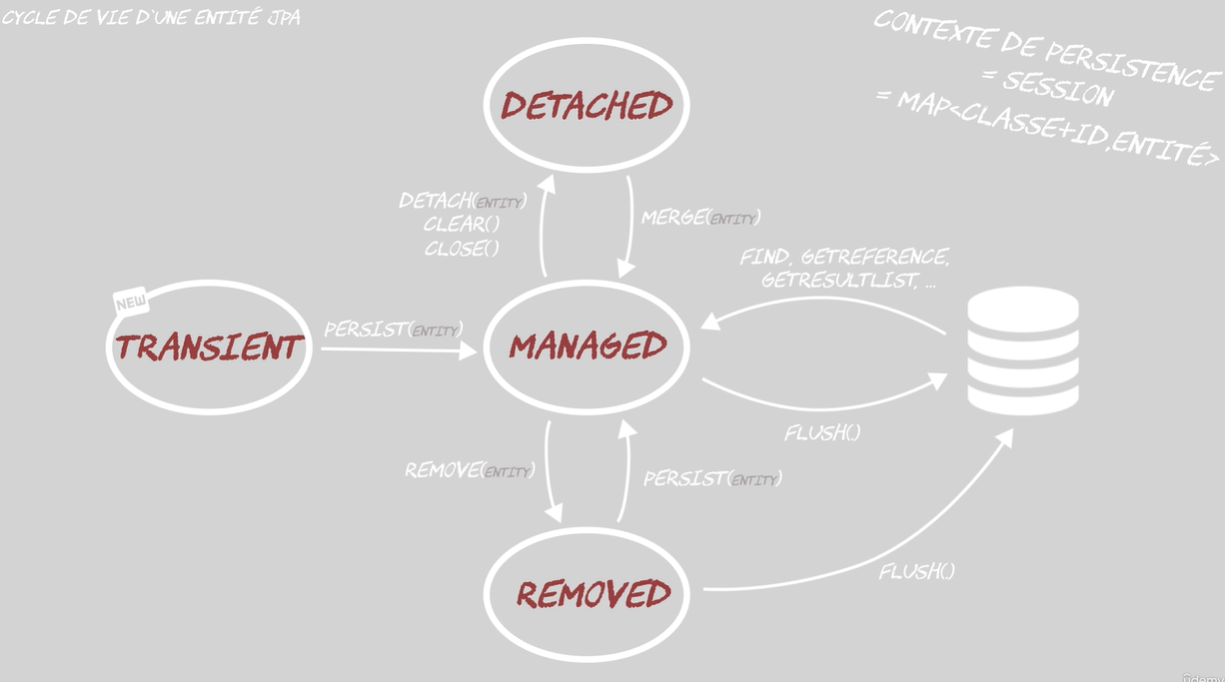
- Ciclo di vita di un’entità
-
- Stato degli oggetti nel “persistence context”
- Transient (== detached di Entity Framework)
- Oggetto creato nell’applicazione (new) ma non ancora aggiunto al context
- Managed (== added)
- Dopo aver creato l’oggetto, tramite il metodo “.persist()” lo aggiungo al context.
- Removed (== deleted)
- Tramite il metodo “.remove()” é possibile rimuove un’oggetto che era “Managed”
- Session = managed + removed
- Gli oggetti negli stati “managed” e “Removed” sono gestiti da Hibernate, appartengono cioé al “persistence context” che é possibile chiamare anche “sessione”.
- Map = Classe + ID entità
- Detached (== unchanged)
- Il metodo “.detach()” permette di ritirare l’oggetto dal context. Tale oggetto si trova in stato “Detached”.
- Il metodo “.merge()” permette di riaggiungere l’oggetto al context.recuperandolo dal DB.
- Tale oggetto si troverà allora nello stato “Managed”.
- Se ci sono delle differenze tra l’oggetto e quello recuperato nel DB, viene fatto l’insert/update.
- Transient (== detached di Entity Framework)
- Sessione
- La sessione in Hibernate é detta anche cache di primo livello.
- Se domandiamo al contesto di persistenza degli oggetti che conosce già, li cerca nella cache senza andare a prenderli nel DB.
- In questo caso la cache dura quanto dura la sessione.
- Stato degli oggetti nel “persistence context”
- PersistenceContext (==DbContext)
- entityManager
-
@PersistContext EntityManager entityManager;
-
-
contains
-
var isPersisted = entityManager.contains(movie); //true o false
-
- persist
-
//movie.status = transient entityManager.persist(movie); //movie.status = managed
-
- find (recupera i dati tramite una query nel DB)
-
Movie movie = entityManager.find(Movie.class, id);
-
- createQuery
-
List<Movie> movies = entityManager.createQuery("from Movie", Movie.class).getResultList();
-
- merge
- Evitare di utilizzare il metodo merge() su un entità che é in stato “managed”. Infatti Hibernate lancia un aggiornamento degli snapshots associti all’entintà consumando delle risorse inutilmente.
-
Movie movie = entityManager.merge(movie); //update or insert
- remove
-
entityManager.remove(movie); //delete
-
- getReference (recuperare solo la classe proxy senza fare una query nel DB. Le proprietà dell’oggetto non sono inizializzate)
- getReference ritorna un oggetto di tipo proxy il quale implementa intrinsecamente lo ‘automatic dirty checking’
- é utile quando non é necressario fare il fetch di tutti i dati dell’oggetto nel DB ma é sufficiente il proxy con la possibilità di fare set
- I dati saranno caricati (da Hibernate) alla domanda solo qualora necessari questo se l’oggetto é in stato managed
- I proxy hibernate non sono serializzabili.
-
Movie movie = entityManager.getReference(Movie.class, id);
- flush (== SaveCanches())
- Il metodo flush forza l’entityManager a inviare tutte le eventuali modifiche (efettuate sugli oggetti) al DB.
- entityManager
- Flush automatico
- Alla chiusura di ogni sessione, il contesto di persistenza esegue un flush automatico delle modifiche presenti verso il DB.
- Normalmente se si fa una routine che aggiunge un oggetto nel DB e poi richiede di leggere tutti gli oggetti presenti allora Hibernate automaticamente farà 2 flush.
- Un primo per inserire la nuova entità.
- Il secondo per rileggere il contenuto aggiornato della relativa tabella.
- Invece di fare aggiungi e leggi ripetutamente, sarebbe meglio centralizzare gli insert e leggere solo alla fine.
-
//nella classe PersistenceConfig private Properties additionalProperties() { -- nessun azione sul DB all'avvio dell'applicazione properties.setProperty("hibernate.hbm2ddl.auto", "none"); -- formatto le query nelle tracce properties.setProperty("hibernate.format_sql", "true"); -- settare la modalità di flush desiderata -- di default = AUTO //il flush viene fatto solo al commit della transazione properties.setProperty("org.hibernate.flushMode", "COMMIT"); }
- Lazy Initialization Exception
- Con Hibernate é possibile lavorare con le classi proxy che vengono recuperate direttamente dalla sessione/cache senza interrogare il DB
- Le proprietà delle classi prowy non sono inizializzate ma caricate “on demand” (solo quando veramente richieste).
- Quando si lavora con un’etità proxy e si cerca di accedere a uno dei sui attributi fuori sessione per cui Hibernate deve fare una chiamata al DB si avrà un’errore del tipo “Lazy Initialization Exception”
- @Transaction => Se la mia query é racchiusa in un metodo con questa annotazione allora non avro’ la “Lazy Initialization Exception” in quanto la sessione é aperta d’ufficio e i dati sono disponibili quando richiesti.
-
@Test @Transactional public void Test_getReference(Integer movieId) { //Hibernate recupera il proxy per l'oggetto "movie" senza interrogare il DB Movie movie = repository.getReference(movieId); //a questo punto hibernate fa la SELECT nel DB per recuperare la proprietà "name" //se non ci fosse l'attributo @Transactional avrei una // "Lazy Initialization Exception" perché Hibernate non avrebbe // una sessione aperta pronta al recupero della proprietà richiesta "name" String name = movie.getName(); }
- Con Hibernate é possibile lavorare con le classi proxy che vengono recuperate direttamente dalla sessione/cache senza interrogare il DB
- Dirty checking
- Il contesto di persistenza quando viene a conoscenza di un’entità (raccolta dal DB o attacca manualmente) ne prende una “foto” cosi ad ogni flush automatico é capace di sapere quali query fare sul DB.
- Stoccare troppe referenze nel context puo’ portare ad aumentare la memoria utilizzata ma il problema principale é piuttosto legato alla CPU. Troppi calcoli per decidere quali modifiche riportare nel DB.
- Classe di configurazione
-
//esempio di file di configurazione di Hibernate @Configuration @EnableTransactionManagement @ComponentScan(basePackages = { "com.<my-project>.<my-package>" }) public class PersistenceConfig { @Bean public LocalContainerEntityManagerFactoryBean entityManagerFactory() { LocalContainerEntityManagerFactoryBean em = new LocalContainerEntityManagerFactoryBean(); //em.setDataSource(dataSourceH2()); em.setDataSource(dataSourcePostgres()); //package where looking for model entities em.setPackagesToScan(new String[] { "com.hibernate4all.tutorial.model" }); JpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter(); em.setJpaVendorAdapter(vendorAdapter); em.setJpaProperties(additionalProperties()); return em; } @Bean public DataSource dataSourceH2() { DriverManagerDataSource dataSource = new DriverManagerDataSource(); dataSource.setDriverClassName("org.h2.Driver"); dataSource.setUrl("jdbc:h2:mem:db;DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=FALSE"); dataSource.setUsername("sa"); dataSource.setPassword(""); return dataSource; } @Bean public DataSource dataSourcePostgres() { DriverManagerDataSource dataSource = new DriverManagerDataSource(); dataSource.setDriverClassName("org.postgresql.Driver"); dataSource.setUrl("jdbc:postgresql://localhost:5432/dbname"); dataSource.setUsername("postgres"); dataSource.setPassword("password"); return dataSource; } @Bean public PlatformTransactionManager transactionManager() { JpaTransactionManager transactionManager = new JpaTransactionManager(); transactionManager.setEntityManagerFactory(entityManagerFactory().getObject()); return transactionManager; } private Properties additionalProperties() { Properties properties = new Properties(); //hibernate create and drop the persistence layer (DB) at each application run //based on declared entities into persistence context properties.setProperty("hibernate.hbm2ddl.auto", "create-drop"); properties.setProperty("hibernate.dialect", "org.hibernate.dialect.H2Dialect"); return properties; } }
-
- target/generated-sources
- JPA Static Metamodel Generator => JPA definisce una “typesafe Criteria” API che permette alle query che usano i “Criteria” queries di essere costruite in modo fortemente-tipizzato, utilizzando le classi cosidette static metamodel
-
//Questo plugin permette di aggiungere automaticamente nella cartella "/target/generated-sources" //le varie entità definite nel nostro progetto in modo da poterle referenziare nei vari moduli <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <annotationProcessorPaths> <annotationProcessorPath> <groupId>org.hibernate</groupId> <artifactId>hibernate-jpamodelgen</artifactId> <version>5.4.3.Final</version> </annotationProcessorPath> </annotationProcessorPaths> </configuration> </plugin> /target /generated-sources /annotations /com /<my-project> /model /Entity1_ /Entity2_ .. /EntityN_
- Notazioni
- @PersistenceContext (== DbContext di Entity Framework)
- L’insieme delle entità che l’aplicazione ha delegato alla gestione di Hiberante.
- @Entity
- HasCode e Equals é opportuno sovrascriverle per un entità se:
- Si una un SET<entità>
- Si pensa di fare il “retach” di un’istanza detached
- Se si ha una chiave funzionale tra le proprietà dell”entità é utile usare direttamente solo questo campo (senza usare gli altri)
- Equals(Object o)
- Evitare di usare le associazioni esterne. Usare solo i campi di proprietà dell’entità.
- Set Vs List
- Version Hibernate < 5.8 => usare SET.
- Per le altre versioni
- List se si vuole avere liste ordinate.
- List é più performante.
- Set se si vuole una lista di valori univoci (bisogna definire correttamente HasCode e Equals)
-
import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; @Entity @Table(name = "Movies") public class Movie { public enum Color { red,green,yellow } @Id //Field access @GeneratedValue(strategy = GenerationType.SEQUENCE | GenerationType.IDENTITY | GenerationType.AUTO) private Long id; @Column(unique = true, name = "nameNew", nullable = false, length = 4000) @Min(value = 0 , message = "Value should be greater then equal to 0") @Max(value = 10 , message = "Value should be less then equal to 10") private String name; @Enumerated //indico a Hibernate che il campo color é un enum private Color color; @Transient //permette di non mappare nel DB tale attributo della classe private String nonPresenteInBase @Override public boolean equals(Object o) { if (this == o) return true; if ((!(o instanceof Movie))) return false; Movie movie = (Movie) o; //CASO 1 //Se l'entità ha almeno un campo che é un identità funzionale (es: codice fiscale, targa..) //allora possiamo appoggiarci su questo campo per implementare // equals() e hasCode() (usate da Hibernate) return Objects.equals(name, movie.name); //CASO 2A //(caso transient) Se l'entità non ha un campo (diverso da ID) // che possa essere legittimamente considerato univoco //allora uso solmo il campo ID se non nullo if(id == null && ((Movie) o).getId() == null) { return Objects.equals(name, ((Movie) o).getName()) && Objects.equals(description, ((Movie) o).getDescription()) && Objects.equals(certification, ((Movie) o).getCertification()); } //CASO 2B //(caso managed) oppure una combinazione con un senso // funzionale degli altri campi se ID é nullo //uso l'id se non nullo return id != null && Objects.equals(id, ((Movie) o).getId()) } @Override public int hasCode() { //usare una costante return 31; } //lasciare la generazione di default //anche qui non aggiungere nessun campo di entità esterne @Override public String toString() { return "Movie{" + "id=" + id + ", name='" + name + '\'' + ", description='" + description + '\'' + ", certification=" + certification + ", color=" + color + '}'; } } - Entità fluent
- E’ possibile rendere la nostra entità fluent implementando i setter in modo che restituiscano l’entità stessa
-
public Movie setColor(Color color) { this.color = color; return this; } //utilizzo dell'entità che é diventata fluent Movie.setName("Fuga da Alcatraz").setDescription("Miglior film").setColor("red");
- Field Access e mapping implicito
- Mettendo @Id su le proprietà della nostra classe, indichiamo ad Hibernate di scorrere tutte le altre proprietà (mapping implicito) per decidere le colonne della tabelle nel DB.
- Avremmo potuto mettere @Id su un getter allora Hibernate avrebbe scorso tutti i metodi con get… per cercare le colonne (questo secondo caso é meno utilzzato).
- HasCode e Equals é opportuno sovrascriverle per un entità se:
- @Repository
-
import java.util.List; import org.springframework.stereotype.Repository; import <my-projet>.model.Movie; @PersistenceContext EntityManagr entityManager; @Repository public class MovieRepository { public void persist(Movie movie) { entityManager.persist(movie); } public List<Movie> getAll() { throw new UnsupportedOperationException(); } }
-
- @PersistenceContext (== DbContext di Entity Framework)
- Relazioni
- 1-a-molti (bidirezionale)
-
//un movie puo' avere molte review //la tabella con la chiave esterna é review //quindi l'oggetto review contiene il campo movie @Entity class Movie { //la chiave esterna é detenuta da "Review.movie" @OneToMany(cascade = CascadeType.ALL, orphanRemoval = true, mappedBy = "movie") private List<Review> reviews = new ArrayList<>(); public Movie addReview(Review r){ if(r != null) { this.reviews.add(r); r.setMovie(this); } return this; } public Movie removeReview(Review r){ if(r != null) { this.reviews.remove(r); r.setMovie(null); } return this; } } @Entity class Review { @ManyToOne(fetch = FetchType.LAZY) //evita di caricare automaticamente l'entità correlata @JoinColumn(name = "movie_id") private Movie movie; }
-
- Molti-a-molti
- @ManyToMany é utilizzabile solo se la tabella d’associazione non ha delle colonne in più oltre alle chiavi esterne.
- Prediligere SET su LIST se si pensa di fare parecchie sopressioni nella tabella d’associazione. Infatti LIST si comporta in una maniera meno performante nelle remove().
-
//un genere puo' appartenere a molti movie //un movie puo' avere molti generi @Entity class Genre { //il proprietario della relazione é l'altro lato //non ho quindi bisogno di configurare il comportamento da //tenere sull'altra entità tramite l'attributo cascade //Set é meglio di List nel molti a molti @ManyToMany(mappedBy = "genres") private Set<Movie> movies = new HastSet<>(); //il setMovies() non é da implementare public Set<Movie> getMovies() { return movies; } } @Entity //entità principale della relazione molti-a-molti class Movie { //é il lato principale della relazione, bisogna definire le cascade //Quando faccio un "movie.persist" voglio fare lo stesso sui genre associati //Quando faccio un "movie.merge" voglio fare lo stesso sui genre associati //NON metto CascadeType.DELETE perché non voglio che venga eliminato il // genere quando elimino un movie associato //per conseguenza non posso usare neanche CascadeType.ALL @ManyToMany(cascade = { CascadeType.PERSIST, CascadeType.MERGE }) //definisco la tabella di gestione della relazione molti-a-molti @JoinTable(name = "movie_genre", joinColumns = @JoinColumn(name="movie_id"), inverseJoinColumns = @JoinColumn(name="genre_id")) private Set<Genre> genres = new HastSet<>(); //il setGenres() non é da implementare public Set<Genre> getGenres() { return Collections.unmodifiableSet(genres); } public Movie addGenre(Genre g) { if(g != null) { this.genres.add(g); g.getMovies().add(this); } return this; } public Movie removeGenre(Genre g) { if(g != null) { this.genres.remove(g); g.getMovies().remove(this); } return this; } }
- Molti-a-Molti con proprietà aggiuntive
- E’ necessario modellizzare la tabella ternaria (che ospita le proprietà aggiuntive di cui ha bisogno la relazione molti-a-molti)
-
//un "actor" puo' essere legato da più "movie" //un "movie" puo' essere legato a più "actor" //la relazione molti-a-molti tra "actor" e "movie" ha la proprietà aggiuntiva "character" @Entity class Actor { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; //qui ci sono le proprietà di Actor ... //la chiave esterna é detenuta da MovieActor.actor @OneToMany(cascade = CascadeType.ALL, orphanRemoval = true, mappedBy = "actor") private List<MovieActor> moviesActors = new ArrayList<>(); } @Entity class Movie { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; //qui ci sono le proprietà di Movie ... //la chiave esterna é detenuta da MovieActor.actor @OneToMany(cascade = CascadeType.ALL, orphanRemoval = true, mappedBy = "actor") private List<MovieActor> moviesActors = new ArrayList<>(); public List getMoviesActors() { return moviesActors; } public void addActor(Actor actor, String character) { MovieActor movieActor = new MovieActor(this, actor).setCharacter(character); moviesActors.add(movieActor); actor.getMoviesActors().add(movieActor); } } //modellizzazione della tabella d'associazione tra "Actor" e "Movie" @Entity @Table(name="movie_actor") class MovieActor { ///////////////////////////////////////////////////////////////////////// //classe embedded che rappresenta la chiave esterna @Embeddable public static class MovieActorId implements Serializable { private static final long serialVersionUID = 6323699701758787853L; @Column(name = "movie_id") private Long movieId; @Column(name = "actor_id") private Long actorId; public MovieActorId() { } public MovieActorId(Long movieId, Long actorId) { this.movieId = movieId; this.actorId = actorId; } @Override public boolean equals(Object o) { if (this == o) return true; if ((!(o instanceof MovieActorId))) { return false; } MovieActorId other = (MovieActorId) o; return Objects.equals(movieId, other.movieId) && Objects.equals(actorId, other.movieId); } @Override public int hashCode() { return Objects.hash(movieId, actorId); } } //////////////////////////////////////////////////////////////// @EmbeddedId private MovieActorId id; @ManyToOne(fetch = FetchType.LAZY) @MapsId("movieId") private Movie movie; @ManyToOne(fetch = FetchType.LAZY) @MapsId("actorId") private Actor actor; //proprietà aggiuntiva della relazione molti-a-molti private String character; public MovieActor() { } public MovieActor(Movie movie, Actor actor) { this.movie = movie; this.actor = actor; this.id = new MovieActorId(movie.getId(), actor.getId()); } }
- 1 a 1 (unidirezionale)
-
//un movie puo' avere un solo movie_detail e un movie_detail é associato a un solo movie //caso unidirezionale (nessuna implementazione nella classe movie) //si implementa solamente movie in movie_detail e non viceversa //se si implementasse anche l'altra direzione della relazione, Hibernate // caricherebbe sempre i dati di movie_detail insieme a quelli di movie //invece noi, una volta recuperato l'oggetto movie, si vuole avere i dati // di movie_detail solo alla domanda. //Nella base di voglio generare una tabelle movie_table(movie_id,plot) @Entity @Table(name='movie_detail') public class MovieDetail { @Id //indica che questo campo é l'identificativo dell'entità private Long id; private String plot; //EAGER (in fase di lettura dell'entità "MovieDetail" visto che carico tutti i "Movie" associati avro' il problema N+1) @OneToOne @MapsId //permette di mappare la chiave primaria (utilzzabile anche con @ManyToOne //indica di utilizzare il valore di questo campo per l'identificativo (id) dell'entità //in altre parole movie_detail.id = movie_id private Movie movie; }
-
- 1-a-molti (bidirezionale)
- Ereditarietà
- Hibernate può mappare una gerarchia di oggetti.
- 4 possibili implementazioni. Quale scegliere ?
- Se si ha una super classe con tanti campi e le classe figlie ne hanno pochi in più allora meglio orientarsi verso il caso 1 o caso 2 (se si ha bisogno di caricare delle relazioni esterne)
- Se invece si ha una situazione più varia con classi figlie con molti campi meglio orientarsi verso il caso 3
- 1 – Creare nel DB solo le tabelle per le entità figlie (@ID sulle entità figlie)
- Svantaggi
- Hibernate é costretta a fare un’interrogazione SQL per ognuna delle tabelle figlie.
- Se si cambia un campo dell’oggetto padre, é necessario cambiarlo anche nelle tabelle dei figli presenti nel DB.
- Lavorare con le associazioni presenti nelle classi figlie non é semplice.
-
@MappedSuperclass public abstract class Padre { protected String name; protected String description; --getter and setter (name + description) } @Entity public Figlio1 extends Padre { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; } @Entity public Figlio2 extends Padre { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; } --- RECUPERARE I FIGLI - ESEMPIO DI POLIMORFISMO //Hibernate fa 2 select, una per ognuna delle classi figlie List<Padre> padri = entityManager .createQuery(select w from <com.myproject.model>.padre w, Padre.class).getResultList(); Long contaFiglio1 = padri.stream().filter(o -> o.getClass() == Figlio1.Class).count(); Long contaFiglio2 = padri.stream().filter(o -> o.getClass() == Figlio2.Class).count();
- Svantaggi
-
- 2 – Creare nel DB solo le tabelle per le entità figlie (@ID sull’entità padre)
- Vantaggi
- Viene fatta una sola select con tutti i figli (UNION con dei NULL nelle SELECT per poter gestire i campi che esistono in un figlio ma sono nulli negli altri e viceverda) e le LEFT JOIN con le relazioni esterne desiderate.
- E’ più seplice lavorare con le associazioni presenti nelle classi figlie.
- Svantaggi
- Se si cambia un campo dell’oggetto padre, é necessario cambiarlo anche nelle tabelle dei figli presenti nel DB.
-
@Entity @Inheritance(strategy = InheritanceType.TABLE_PER_CLASS) public abstract class Padre { @Id @GeneratedValue(strategy = GenerationType.SEQUENCE) protected Long id; protected String name; protected String description; --getter and setter (id + name + description) } @Entity public Figlio1 extends Padre { //senza id } @Entity public Figlio2 extends Padre { //senza id } --- RECUPERARE I FIGLI - ESEMPIO DI POLIMORFISMO //Hibernate fa 2 select, una per ognuna delle classi figlie //non ho bisogno di usare <com.myproject.model>.padre ma solo padre // (ora Hibernate conosce l'entità direttamente) List<Padre> padri = entityManager .createQuery(select w from padre w left join fetch w.tabella_esterna, Padre.class).getResultList(); Long contaFiglio1 = padri.stream().filter(o -> o.getClass() == Figlio1.Class).count(); Long contaFiglio2 = padri.stream().filter(o -> o.getClass() == Figlio2.Class).count(); // esempio di select con 2 figli e una terza tabella (associazione esterna) select distinct watchable0_.id as id1_9_0_, reviews1_.id as id1_7_1_, watchable0_.description as descript2_9_0_, watchable0_.clazz_ as clazz_0 from ( select id, description, name, certification, null::int4 as seasons, 1 as clazz_ from Figlio1 union all select id, description, name, null::int4 as certification, seasons, 2 as clazz_ from Figlio2 ) tab left outer join <Tabella-esterna> tab_ext on tab.id = tab_ext.movie_id
- Vantaggi
- 3 – Creare nel DB solo una tabella per tutte le entità figlie (= coincide al caso Table-per-hierarchy pattern di Entity Framework)
- Campi della tabella unica = campi del padre + campo unici del figlio1 + campo unici del figlioN + campo discriminante
- Nel DB non ci sono più le tabelle figlie ma un’unica tabella con i campi somma dei campi padre + tutti i figli + colonna discriminante (per sapere a quale figlio corrispondono i dati presenti su quella riga)
-
@Entity @Inheritance(strategy = InheritanceType.SINGLE_TABLE) @DiscriminatorColumn(name="children_type") public abstract class Padre { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) protected Long id; protected String name; protected String description; --getter and setter (id + name + description) } @Entity @DiscriminatorValue("figlio1") public Figlio1 extends Padre { //senza id //campi specifici } @Entity @DiscriminatorValue("figlio2") public Figlio2 extends Padre { //senza id //campi specifici } - Vantaggi
- Viene fatta una sola select con tutti i figli senza bisogno di una UNION e le LEFT JOIN con le relazioni esterne desiderate.
- E’ più seplice lavorare con le associazioni presenti nelle classi figlie.
- Non é necessario gestire le tabelle figlie nel DB (c’é solo il padre)
- Svantaggi
- Le colonne proprie ad un figlio non possono essere NOT NULL, in quanto il valore NULL é necessario perché tali colonne non esistono negli altri figli e vengono mappate in un unica colonna. Per ovviare a questo limite é opportuno validare tali campi direttamente nel codice (backend)
- 4 – Creare nel DB padre + figli (= coincide al caso Table-per-type pattern di Entity Framework)
- Implementare l’ereditarietà direttamente nel DB tramite delle chiavi esterne
- Tabella padre con gli attributi comuni
- Tabelle figlie con la chiave esterna che punta al padre + colonne specifiche.
-
@Entity @Inheritance(strategy = InheritanceType.JOINED) public abstract class Padre { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) protected Long id; protected String campo_comune_1; protected String campo_comune_2; protected String campo_comune_N; --getter and setter (id + tutti i campi_comuni) } @Entity public Figlio1 extends Padre { //senza id //campi specifici } @Entity public Figlio2 extends Padre { //senza id //campi specifici }
- Implementare l’ereditarietà direttamente nel DB tramite delle chiavi esterne
- 2 – Creare nel DB solo le tabelle per le entità figlie (@ID sull’entità padre)
- Lettura dei dati
- Problema N + 1 (caricamento EAGER)
- Quando interrogo un’entità che é legata con una relazione 1 a 1 ad un’altra con la modalità EAGER alla fine avro’ N+1 query da fare
- la query sulla tabella legata alla mia entità.
- ma anche le N query (una per ogni riga appena recuperata) per andare a prendere i dati dell’entità legata dalla relazione 1 a 1 e caricata in modalità EAGER.
-
//Al caricamento di MovieDetail oltre alla query su MovieDetail // vengono generate altre N sulla tabella Movie (EAGER) public class Movie {} public class MovieDetail { @OneToOne @MapsId private Movie movie; }
- Soluzione
- Caricare l’entità esterna in modalità LAZY
-
@OneToOne(fetch = FetchType = LAZY)
-
- Usare inner join
-
entityManager .createQuery("select DISTINCT m from MovieDetail m join fetch m.movie", MovieDetail.class).getResultList();
-
- Spezzare la query in due passaggi (recuperare prima l’entità principale e poi la relazione esterna corrispondente)
- Attenzione: potrebbe trasformare il problema in un problema di prodotto cartesiano
- Caricare l’entità esterna in modalità LAZY
- Quando interrogo un’entità che é legata con una relazione 1 a 1 ad un’altra con la modalità EAGER alla fine avro’ N+1 query da fare
- Lettura entità tramite ID
-
//Find //Hibernate esegue una query SQL e recupera tutti i dati dell'entità "movie" Movie movie = repository.Find(movieId); //getReference //Hibernate non esegue alcuna query SQL e recupera un proxy dell'entità "movie" //Tale proxy non ha tutte le proprietà dell'entità che dovranno essere caricate da Hibernate "alla domanda". Movie movie = repository.getReference(movieId);
-
- Lettura di associazioni => Fetch plan
-
//Fetch plan Quando in un'entità abbiamo delle referenze esterne possiamo impostare la proprietà fetch E' possibile cioé decidere se caricare una referenza esterna (LIST o entità singola) direttamente quando si carica l'entità (eager loading) o "alla domande" (lazy loading) @Entity public class Movie { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; //EAGER @OneToMany(cascade = CascadeType.ALL, orphanRemoval = true, mappedBy = "movie", fetch = FetchType.EAGER) private List<Review> reviews = new ArrayList<>(); //LAZY @OneToMany(cascade = CascadeType.ALL, orphanRemoval = true, mappedBy = "movie") private List<Award> awards = new ArrayList<>(); }
-
- Hql
- Linguaggio di Hiberbate.
- Jpql
- Linguaggio dello standard JPA.
- Vantaggio
- Codice leggibile (la query é simile al SQL)
- Svantaggio
- Non é facile modificare le query una volta fatte (es: cambiare il nome di una tabella).
- Le query possono diventare lunghe sequenze di caratteri.
-
List<Movie> movies = entityManager.createQuery("SELECT m FROM movie m WHERE m.name = :pName, Movie.class) .setParameter("pName", name) .getResultList(); Movie movie = entityManager.createQuery(sql, Movie.class).getSingleResult();
- Criteria Jpql
-
var movies = repository.findWithCertification(Operator.lessThanOrEqualTo, 2); public enum Operator { lessThan, lessThanOrEqualTo, equal, greaterThanOrEqualTo,greaterThan } public List<Movie> findWithCertification(Util.Operator operator, Certification certification) { CriteriaBuilder builder = entityManager.getCriteriaBuilder(); CriteriaQuery<Movie> query = builder.createQuery(Movie.class); //select * from Watchable Root<Movie> root = query.from(Movie.class); //where m.certification Predicate predicat = null; switch (operator) { case lessThan -> { predicat = builder.lessThan(root.get(Movie_.CERTIFICATION), certification); } case lessThanOrEqualTo -> { predicat = builder.lessThanOrEqualTo(root.get(Movie_.CERTIFICATION), certification); } case equal -> { predicat = builder.equal(root.get(Movie_.CERTIFICATION), certification); } case greaterThanOrEqualTo -> { predicat = builder.greaterThanOrEqualTo(root.get(Movie_.CERTIFICATION), certification); } case greaterThan -> { predicat = builder.greaterThan(root.get(Movie_.CERTIFICATION), certification); } } query.where(predicat); return entityManager.createQuery(query).getResultList(); }
-
- Join
-
//Jpql //la parola chiave DISTINCT permette a Hibernate di ripulire il risultato in memoria //setHint => possiamo invece evitare che sia applicato alla query SQL effettivamente generata //la parola chiave FETCH significa che nella SELECT si caricano anche i // dati della tabelle dell'associazione esterna (es: movie.reviews) List<Movie> movies = entityManager .createQuery("SELECT DISTINCT m FROM Movie m LEFT JOIN FETCH m.reviews", Movie.class).getResultList() .setHint(QueryHints.HINT_PASS_DISTINCT_THROUGH, false) //Join doppio //Movie.reviews = LIST //Movie.genres= SET List<Movie> movies = entityManager .createQuery("SELECT DISTINCT m FROM Movie m LEFT JOIN FETCH m.reviews LEFT OUTER FETCH m.genres", Movie.class).getResultList() .setHint(QueryHints.HINT_PASS_DISTINCT_THROUGH, false) //Criteria CriteriaBuilder cb = entityManager.getCriteriaBuilder(); CriteriaQuery<Order> cq = cb.createQuery(Order.class); SetJoin<Order, Item> itemNode = cq.from(Order.class).join(Order_.items); cq.where( cb.equal(itemNode.get(Item_.id), 5 ) ).distinct(true);
-
- Join multipli con almeno 2 LIST
- MultipleBagFetchException =>
- Hibernate ha problemi a fare un multiple join su 2 o più entità esterne di tipo LIST (che potrebbero quindi legate tra loro)
- Prodotto cartesiano =>
- Visto che fa delle left outer join allora se ho delle join multiple allora il risultato che ottengo é TUTTE le righe del prodotto cartesiano tra le entità di cui sto facendo le join che é un comportamento che non voglio.
- Soluzione veloce => Sostituire tutte le LIST con delle SET. Soluzione non efficace.
- Soluzione efficace =>
- Spezzo la multiple join in più join doppie e sfrutto la cache di primo livello nativa di Hibernate
- ATTENZIONE: Le verie query DEVONO condividere la sessione.
-
//Join doppio con 2 list //Movie.reviews = LIST //Movie.awards = LIST //spezzo la query in 2 passaggi //Le varie query devono condividere la sessione @Transaction public List<Movie> getMoviesJoinReviewsAndAwards() { //prima query dove recupero le "reviews" associate ai "movie" List<Movie> movies = entityManager .createQuery("select DISTINCT m from Movie m left join fetch m.reviews", Movie.class) .setHint(QueryHints.HINT_PASS_DISTINCT_THROUGH, false) .getResultList(); //seconda query dove recupero gli awards dei movie che avevo recuperato nella query precedente return entityManager .createQuery("select DISTINCT m FROM Movie m LEFT JOIN FETCH m.awards where m in (:movies)", Movie.class) .setParameter("movies", movies) .setHint(QueryHints.HINT_PASS_DISTINCT_THROUGH, false) .getResultList(); } -
//Esempio 2 @Transactional public MovieDetail getDetail(Long movieId) { MovieDetail detail = entityManager .createQuery("select DISTINCT d from MovieDetail d " + " inner join fetch d.movie m " + " left join fetch m.reviews " + " left join fetch m.genres " + " where d.id in (:movieId)", MovieDetail.class) .setParameter("movieId", movieId) .setHint(QueryHints.HINT_PASS_DISTINCT_THROUGH, false) .getSingleResult(); //Hibernate (stando operando nella stessa sessione) é capace // di raggruppare i risultati di una seconda query. // In questo caso, visto che Movie.awards é una LIST come movie.reviews // non possono essere caricate con la stessa query // percio' creo una seconda query che andrà a sommarsi alla prima entityManager .createQuery("select DISTINCT m FROM Movie m LEFT join fetch m.awards WHERE m in (:movies)", Movie.class) .setParameter("movies", detail.getMovie()) .setHint(QueryHints.HINT_PASS_DISTINCT_THROUGH, false) .getResultList(); return detail; }
- MultipleBagFetchException =>
- SQL native
- Utile se si vogliono usare delle funzioni si SQL che non possono essere utilizzate in Hibernate (es: select reverse(name) from movie)
- Query complesse
-
//esempio 1 Query query = em.createNativeQuery( "select id from users where username = ?"); query.setParameter(1, "lt"); BigDecimal val = (BigDecimal) query.getSingleResult(); //esempio 2 public List<Object[]> getTopReviewers() { List<Object[]> authors = entityManager .createNativeQuery("select author, count(*) conta from review r group by author") .getResultList(); //authors.stream().forEach(t -> LOGGER.trace("Author: " + t[0] + " (" + t[1] + ")")); return authors; } //esempio 3 con Tuple public List<Pair<String, BigInteger>> getTopReviewersWithTuple() { List<Pair<String, BigInteger>> result = new ArrayList<>(); List tuples = entityManager .createNativeQuery("select count(r), author FROM review r GROUP BY author", Tuple.class) .getResultList(); tuples.stream().forEach(t -> result.add(Pair.of((String) t.get(1), (BigInteger)t.get(0)))); return result; }
- getResultStream (non troppo usato)
-
//la sessione deve essere aperta per poter scorre il cursore return entityManager.createQuery("<my-query>") .setHint(QueryHints.HINT_FETCH_SIZE, 50) //indico a PostgreSQL di recuperare solo 50 righe e non tutte alla volta .getResultStream() .skip(start) .limit(maxResult) .filter(predicate) //filtro gestito in JAVA dopo aver recuperato i dati dal DB .sorted(comparator) .collect(Collector.toList())
-
- Problema N + 1 (caricamento EAGER)
- Paginazione
- JPA offre uno standard per la paginazione.
- La paginazione é fatta in-memory e non direttamente nel DB, significa cioé che ogni volta bisogna comunque recuperare l’integralità dei dati prima di gestire la paginazione stessa.
-
public List<Movie> getAllPagination(int start, int maxResult) { return entityManager.createQuery("selct m from Movie m order by m.name", Movie.class) .setFirstResult(start) .setMaxResults(maxResult) .getResultList(); }
- Migrazione
- Parlando in un ORM la migrazione é un punto di primaria importanza. Si tratta infatti di riportare nel DB le modifiche fatte nelle entità. Ci sono 2 approcci principali
- Partendo dal codice
- Hibernate puo’ agire sul livello di persistenza (DB) ad ogni restart dell’applicazione settando nel modo desiderato la proprietà “hibernate.hbm2ddl.auto” nel metodo AdditionalProperties() della classe di configurazione:
-
//Al restart dell'applicazione web Hibernate: //1 - non realizza nessuna azione sul "livello di persistenza" properties.setProperty("hibernate.hbm2ddl.auto", "none"); //2 - crea il "livello di persistenza" in base alle @Entity definite nel "model" properties.setProperty("hibernate.hbm2ddl.auto", "create"); //3 - riporta ogni cambiamento effettuato nel "model" al "livello di persistenza" properties.setProperty("hibernate.hbm2ddl.auto", "update"); //4 - utile per i TEST - come caso "crea" ma alla chiusura dell'applicazione web Hibernate fa // il drop del "livello di persistenza" properties.setProperty("hibernate.hbm2ddl.auto", "create-drop");
- Direttamente nel DB
- Flywaydb => Tramite Flywaydb é possibile gestire i cambiamenti di struttura del DB direttamente tramite script
- Aggiungere dipendenza
-
//pom.xml <dependency> <groupId>org.flywaydb</groupId> <artifactId>flyway-core</artifactId> </dependency>
-
- Aggiungere scripts di modifica del DB
-
//percorso standare dove "flywaydb" cerca gli script da applicare alla base <my-project>/src/main/resources/db/migration/... (aggiungere qui gli scripts)
-
- Tabella flyway_scheme_history
- Flywaydb memorizza gli script applicati alla DB tramite la tabella “flyway_scheme_history”.
- Ogni volta che viene aggiunto un file nella relativa cartella del progetto,, Flywaydb lo applicherà al DB e aggiornerà la tabella con lo storico delle modifiche cosi’ da poter sapere a che punto siamo e eventualmente ripetere certe modifiche.
- Disabilitare Flywaydb
-
//application.properties spring.flyway.enabled=false
-
- Aggiungere dipendenza
- Flywaydb => Tramite Flywaydb é possibile gestire i cambiamenti di struttura del DB direttamente tramite script
- Meccanismi di cache
- Problematiche generali
- E’ un meccanismo per cui dei dati sono duplicati in modo da renderli di più facile accesso per la risorsa che li richiede
- Questo meccanismo porta dei benefici ma deve essere poi gestito.
- Come sincronizzare i dati presenti nella cache con quelli principali presenti nella nostra sorgente dati.
- Come gestire gli accessi concorrenti
- Cosa succede se i dati della cache diventano grossi
- Implementare lq cache in Hibernate solo in estrema ratio se le performance sono insufficienti.
- Ricordarsi che normalmente abbiamo già naturalmente delle cache
- Il DBMS legge i dati da un sistema di file una prima volta se non ancora trattati.
- Il DBMS li recupera invece direttamente dalla memoria se già letti.
- Il DBMS usa anche degli INDICI che in soldoni duplica anch’esso una parte dei dati.
- Hibernate ha già la gestione della sessione che é una sorta di cache di primo livello.
- Cache di primo livello (sessione)
- Quando le query sono parte di una sessione allora condividono i dati, cio’ simula una sorta di cache.
- Cache di secondo livello (ehcache)
- E’ una cache gesita a livello della Java virtual machine (JVM).
- Aggiungere al progetto la libreria e configurarla
-
//Passo 1: aggiungere la dipendenza al pom.xml <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-ehcache</artifactId> </dependency> //Passo 2: aggiungere delle proprietà nella classe PersistenceConfig private Properties additionalProperties(){ //(gestione per entità) attivo la cache di 2° livello a livello di entità properties.setProperty("hibernate.cache.use_second_level_cache", "true"); //(gestione per query) attivo la cache di 2° livello a livello di query (comando <createQuery>) properties.setProperty("hibernate.cache.use_query_cache", "true"); //indico a Hibernate dove memorizzare i dati in cache properties.setProperty("hibernate.cache.region.factory_class", "org.hibernate.cache.ehcache.EhCacheRegionFactory"); }
-
- (gestione per entità) Aggiungere le entità alla cache
-
//esempio cache entità singola @Entity //attivo la cache sull'entità "genre" @Cacheable //strategia di cache @org.hibernate.annotations.Cache(usage = CacheConcurrencyStrategy.NONSTRICT_READ_WRITE) public class Genre { ... } //esempio cache collezione class Movie { @org.hibernate.annotations.Cache(usage = CacheConcurrencyStrategy.NONSTRICT_READ_WRITE) private final Set<Genre> genres = new HashSet<>(); }
-
- (gestione per query) Indicare quali query gestire in cache
-
@Override public List<Genre> getAll() { return entityManager.createQuery("from Genre g", Genre.class) .setHint(QueryHints.HINT_CACHEABLE, "true") .getResultList(); }
-
- Problematiche generali
- Tips
- Distinct
- Uso DISTINCT se ho un FETCH con una campo che una collezione.
- Prima di fare una decidere come implementare una query di lettura in hibernate:
- verificare come le relazioni sono mappare: unilaterali o bilaterali.
- verificare se le relazioni esterne sono é EAGER o LAZY
- OneToOne di default é EAGER
- StackOverFlow error
- Quando non si usano dei DTO ma direttamente le entità nel nostro MODEL che sono correlate tra loro, fare attenzioni alle relazioni bidirezionali che potrebbero creare dei cicli infiniti.
- @JsonIgnore
- Spezzo la catena biridezionale che crea l’impossibilità di serializzare il mio oggetto
-
//un "movie" puo' avere molte "review" class Movie { @OneToMany(cascade = CascadeType.ALL, orphanRemoval = true, mappedBy = "movie") private List<Review> reviews = new ArrayList<>(); } una "review" é legato ad un "movie" class Review { @ManyToOne @JoinColumn(name = "movie_id") @JsonIgnore private Movie movie; }
- Distinct
- Statistics
-
@Test void findAll_nominal_case_perftest() { //attivo le statistiche hibernate SessionFactory factory = entityManagerFactory.unwrap(SessionFactory.class); Statistics stats = factory.getStatistics(); stats.setStatisticsEnabled(true); List<Movie> movies = repoMovie.getAll(); //Controllo che la query che ritorna tutti i Movie generi solo 1 qurey //Se percaso attivo il fetch=EAGER in alcune delle referenze esterne della mia entità Movie allora le // mi attendo che le query generate siano N + 1 assertThat(stats.getPrepareStatementCount()).as("One SELECT to get all the movies").isEqualTo(1L); }
-
Hibernate – Problematiche di produzione
- Pool di connessioni (alla base di dati)
- Funzionamento di default (senza pool)
- Per poter recuperare i dati nel Db, Hibernate apre una nuova connessione normalmente in modalità auto-commit (con l’impossibilità quindi di aprire una transazione)
- Con un pool di connessioni attivo succede che Hibernate crea un certo numero di connessioni che costituiscono il nostro pool e che saranno a disposizione delle varie richieste di connessione di cui la procedura che stiamo eseguendo avrà bisogno.
- Postgres
-
//visualizzo stato delle connessioni al DB select * from pg_stat_activity where datname = '<my-database>'
-
- @Transactional =>
- Permette di “prenotare” una connessione del pool.
- Metta la modalità auto-commit = false, permette cioé di poter avviare una transazione.
- Funziona solo su metodi di classi iniettate da Spring (@Bean) e public
- Proprietà
- Propagation
- Metodi in lettura
-
//se esiste una transazione, la nostra query semplicemente si aggiunge //se invece non ne esiste una, la nostra query NON ne crea una nuova. @Transactional(Propagation = propagation.SUPPORTS) public MyMethod()
-
- Metodi in scrittura
-
//se esiste una transazione, la nostra query semplicemente si aggiunge //se invece non ne esiste una, la nostra query ne crea una necessariamente. @Transactional(Propagation = propagation.REQUIRED) (valore di Default, attributo non necessario) public MyMethod()
-
- Metodi in lettura
- ReadOnly
-
//Ogni modificazioni nella DB verrà impedita //Disattiva il sistema di dirty checking di Hibernate. @Transactional(Readonly = true) public MyMethod()
-
- Propagation
- Funzionamento di default (senza pool)
- Look ottimistico
- Le entità devono avere una proprietà “version”
-
class Movie { //lool ottimistico @Version private short version; } //query con look ottimistico attivo update movie set name = '<new_name>', version=<old_version> + 1 where id=<my_id> and version = <old_version>
-
- Quando prendo possessione dei dati su cui devo agire ne leggo la versione.
- Subito prima di lanciare il commit delle mie modifiche leggo di nuovo la versione dei dati
- se questa non é cambiata allora il commit é confermato.
- se questa é cambiata allora lancio un’eccezione e il commit sarà annullato.
- vs Look pessimistico
- Ogni volta che prendo possesso di un set di dati, li loccko e nessun altro li potrà modificare/leggere finché non faccio il commit delle mie modifiche.
- Le entità devono avere una proprietà “version”
Risorse