
Oracle è un DBMS (database management system) ed è tipicamente composto dai seguenti elementi:
- kernel code (codice che gestisce l’organizzazione e l’immagazzinamento dei dati);
- repository dei metadati (normalmente chiamato data dictionary);
- query language;
di tipo relazionale (RDBMS), che implementa cioè il modello relazionale:
- struttura (oggetti predefiniti ospitano e accedono ai dati);
- fisica
- data files (ogni database Oracle ha 1 o più file che contiene i dati immagazzinati nel DB);
- control files (ogni database Oracle ha 1 file di controllo che contiene i metadati che specificano la struttura fisica del DB, ad esempio il nome e la posizione dei data files);
- log files (ogni database Oracle ha 1 online redo log che contiene una copia delle modifiche apportate ai dati. Sono usati per il ripristino del DB dopo un problema hardware, software o di rete);
- logica
- data blocks (una data block corrisponde ad un determinato numero di byte ed è il più basse livello di granularità nel quale sono immagazzinati i dati);
- extents (uno specifico insieme di blocchi logicamente contigui, ottenuto in una singola allocazione);
- segments (un insieme di extent, allogati per uno schema object, undo data o dati temporanei);
- tablespaces (ognuna delle unità logiche in cui è divisa la struttura logica del DB. E’ il contenitore logico di un segment. Ogni tablespace è legato ad almeno un data file fisico);
- la struttura fisica e logica sono indipendenti;
- fisica
- operazioni (azione ben definiti permettono alle applicazioni di manipolare la struttura e i dati);
- logiche (si specifica quale contenuto è richiesto);
- fisiche (si determina come ottenere il contenuto richiesto);
- regole di integrità (regole di integrità governato le operazioni sulla struttura e i dati);
Un database relazionale è un database che ospita i dati in un insieme di semplici ‘relazioni‘. Una relazione è un insieme di ‘tuple‘. Una tupla è un insieme non ordinato di attributi. Una tabella è la rappresentazione bi-dimensionale di una relazione nella forma di righe (tuple) e colonne (attributi). Uno schema (database schema) è un insieme di strutture logiche (schema objects, tra cui tabelle e indici) e generalmente ha lo stesso nome dello user che ne è l’owner. Alcuni database objects (ruoli e profili) non risiedono negli schema.
Istanza
Quando un’applicazione si connette a un database Oracle, si connette ad un’istanza del database. L’istanza serve l’applicazione allocando altre aree di memoria nella SGA (System Global Area) e facendo partire altri processi tra i processi di background. Ogni processo di background o processo server ha una parte esclusiva di memoria che contiene dati e informazioni di controllo chiamata PGA (Program global area).
Oracle Net Listener
E’ un processo eseguito sul server o nella rete (che unisce applicazione client e il server con l’istanza di Oracle) che riceve le richieste di connessione dal client e gestisce il traffico di queste richieste verso il server. Quando la connessione è stabilita, client e server dialogano direttamente. E’ possibile lavorare con processi in modalità dedicated server or shared server, in quest’ultimo caso cìè un dispatcher che permette a molte applicazioni client di connettersi alla stessa istanza senza il bisogno di un servizio server dedicato.
SqlPlus
Per accedere ad un’istanza remota di Oracle è necessario settare i transname.ora
local_SID =
(DESCRIPTION =
(ADDRESS = (PROTOCOL= TCP)(Host= hostname.network)(Port= 1521))
(CONNECT_DATA = (SID = remote_SID))
)e digitare nel command prompt di windows
sqlplus user/pass@local_SIDSchema
E’ una collezione logica di database objects:
- tabelle (immagazzinano i dati in righe);
- indici (contengono una entry per ogni riga indicizzata);
- partizioni (parti di una tabella o indice molto grande);
- viste (rappresentazioni customizzate di una o più tabelle o viste. Non contengono dati);
- sequence (può essere condiviso da più utenti per generare un intero. Generalmente usato per generare primary key);
- dimensioni (definisce una relazione padre-figlio tra coppie di insiemi di colonne, dove tutte le colonne di un insieme devono venire dalla stessa tabella);
- sinonimi (alias per un’altro database object);
- packages (una pl/sql package raggruppa logicamente pl/sql tipi, ps/sql variabili e pl/sql sottoprogrammi che sono named pl/sql blocks cioè storedprocedure);
e ha lo stesso nome dello user che lo gestisce. Ci sono alcuni database object che non sono parte di uno schema:
- user account;
- ruoli;
- dictionary;
- context;
La maggior parte degli oggetti di uno schema è memorizzata in strutture logiche di memoria chiamate segmenti e in raggruppamenti di questi, chiamati tablespace. Un tablespace può contenere oggetti di più schemas e gli oggetti di uno schema possono essere contenuti in più tablespace. I dati di ogni database object può essere contenuto in uno o più file fisici. Mentre esistono alcuni database object che non contegono dati ma solo metadati (viste, sequence).
Sys e System
L’account amministrativo Sys è creato automaticamente alla creazione del database. L’utente Sys ha i diritti per eseguire tutte le attività di amministrazione sul db. Lo schema Sys contiene tutte le tabelle e le viste del data dictionary. Queste tabelle non devono essere manipolate dagli utenti.
L’account amministrativo System è creato automaticamente alla creazione del database. Lo schema System ha ulteriori tabelle e viste che mostrano informazioni di tipo amministrativo e tabelle ad uso interno di tool e opzioni del database.
Tabella
Una tabella è un’unità di base nell’organizzazione dei dati di un db. Spesso corrisponde ad un’entità.
- tabelle relazionali;
- heap-organized (default option): immagazzina le righe senza nessun ordine particolare;
- index-organized: immagazzina le righe secondo la chiave primaria;
- external table: è una tabelle di sola lettura, i cui metadati sono memorizzati nel database ma i cui dati sono immagazzinati esternamente al database;
- tabelle di oggetti (ad esempio una tabella di un tipo a sua volta creato dall’utente);
- CREATE or REPLACE TYPE department_type AS OJBECT (name varchar(20));
- CREATE or REPLACE TABLE department_type_table AS department_type;
- CREATE or REPLACE TYPE department_table_type AS TABLE OF department_type;
Indici
Lo scopo principale di avere un indice è accelerare le query di ricerca riducendo essenzialmente il numero di record/righe in una tabella che devono essere esaminati. Un indice è una struttura di dati (più comunemente un albero B) che memorizza i valori per una colonna specifica in una tabella.
Dato un valore che è stato indicizzato, l’indice punta direttamente alle righe contenenti quel valore. In una tabella heap-organized che non abbia indici è necessario eseguire un full table scan per recuperare un valore. Predisporre un indice nei seguenti casi:
- le colonne indicizzate sono interrogate frequentemente e ritornano una piccola percentuale delle righe totali;
- le colonne indicizzate sono delle chiavi esterne;
- quando si pensa di inserire una chiave unica e si vuole specificare manualmente l’indice e le sue opzioni;
- gli indici sono strutture fisiche memorizzate nel database. Mentre le chiavi sono strutture logiche.
Un indice può essere reso invisibile o inutilizzabile. Così non sarà più utilizzato dall’optimizer, Se inutilizzabile, sarà eliminato il segmento dove è stato memorizzato.
Indice composto:
- è un indice su più colonne. Porre l’ordine secondo un senso di priorità, infatti una SELECT sarà velocizzata se nella WHERE ci saranno tutte le colonne dell’indice composto o le prime. Porre per primi le colonne con cardinalità elevata: cioè il numero di possibili valori in relazione al numero di righe della tabella.
- se più indici hanno lo stesso set di colonne e non differiscono per tipo o schema di partizionamento allora devono usare diverse permutazioni delle colonne.
- indici non-univoci che cioè possono avere più righe con gli stessi valori sono ordinati utilizzando le colonne della chiave più il rowid ascendente.
Tipi di indici:
- b-tree (balanced-tree), è il tipo di default ed è adatto per gli indici selettivi (poche righe corrispondono ad una entry della chiave) e le chiavi primarie. E’ una lista ordinata di valori divisi in range ed è formato da rami (contenenti i range di valori) e le foglie (contenenti i puntatori ai dati, valore indicizzato + rowid). L’altezza di un indice è il numero di blocchi per andare dal ramo all’ultima foglia. Il livello del ramo è l’altezza meno 1.
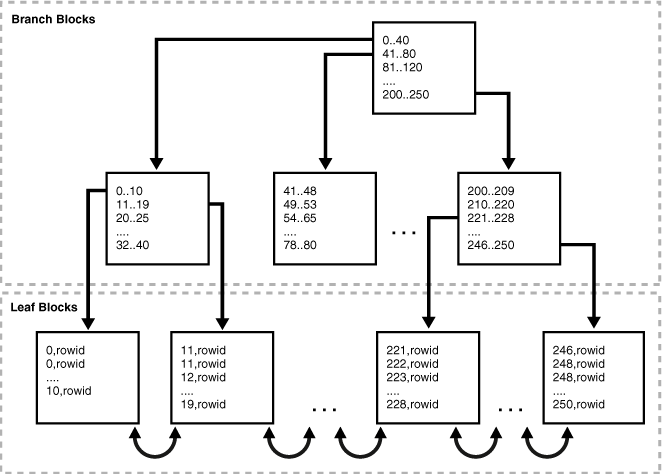
Ne esistono i seguenti 4 sottotipi:
- tabelle index-organized: in una tabella index-organised i dati sono loro stessi degli indici;
- reverse-key: in questo caso gli indici sono memorizzati con i bytes ivertici per poter utilizzare molti blocchi;
- descending: memorizzano i dati di una o più colonne i ordine discendente;
- b-tree cluster: invece di memorizzare il puntatore alla riga che contiene i dati dell’indice, punta ai blocchi di memoria che contengono quelle righe;
- bitmap o Bitmap join: usa un bitmap per puntare a righe multiple;
- function-based: contiene colonne che possono essere trasformate tramite funzioni;
- application domain: gestisce dati di uno specifico application-domain. Non rispecchia la classica struttura di un indice e può essere immagazzinato anche fuori da Oracle;
Gli indici, una volta creati, sono mantenuti da Oracle a fronte di ogni operazione DML sui dati in modo trasparente agli utenti. Per questo è meglio gestirli in modo ragionato per non sovraccaricare il database di eccessivo lavoro. Se un’istruzione SQL accede solo colonne indicizzate allora il database legge direttamente l’indice e non la tabella. In caso di colonne miste tipicamente il database legge alternativamente index-block e table-block.
Full Scan Index: viene scorso l’intero indice e il predicato ha almeno una colonna indicizzata (a volte anche senza). Può non essere necessario il sorting poiché i dati sono già ordinati tramite la chiave dell’indice.
Fast Full Scan index: è un FULL INDEX SCAN dove i dati richiesti sono tutti campi presenti nell’indice e senza la necessità di un ordinamento. Non deve apparire una riga con tutti NULL e perciò una delle colonne dell’indice deve essere NOT NULLABLE o i valori NULL eliminati grazia alla clausola WHERE.
Index Range Scan: quando è scorso in modo ordinato un indice dei quali 1 o più colonne fanno parte del predicato e 0,1 o più valori sono possibili per una sola chiave. E’ usato a seconda della selettività e qunado nel predicato c’è la richiesta di un range (between, >, <). L’indice cerca la foglia corrispondente a valore più basso del range, dopodichè si sposta orizzontalmente attraverso le foglie adiacenti.
Index Unique Scan: diversamente dal INDEX RANGE SCAN deve avere 0 o 1 valore possibile associato ad una chiave. Il predicato deve contenere tutte le colonne dell’indice di tipo unique e usare l’operatore di =. L’indice interrompe la ricerca alla prima occorrenza poichè non ce ne possono essere altre.
Index Skip Scan: risulta performante se esistono pochi valori della principale colonna dell’indice e molti nelle restanti colonne contenute nell’indice composito. Il database opera creando dei sottoindici, uno per ogni valore della colonna principale e scansiona solo quello presente nella riga ricercata dal predicato. Non è necessario che il predicato contenga il campo principale dell’indice.