
- Agile
- Ruoli in progetti tradizionali
- Architettura stateless vs stateful
- Acid
- Controllo della concorrenza
- Architecture
- Memory Management
- Fondamenti della OOP
- Tipi di relazione tra classi
- I 4 pilastri della OOP
- HTTP Basics
- EOL characters
- Relazioni del DB
- JSON vs YML
- URI vs URL vs URN
- Content Delivery Network
- Accelerazione Hardware
- Virtualizzazione in Windows
- OPC UA (Open platform communications – Unified Architecture)
- LPR/LPD Protocol
- EDI (Electronic Data Interchange)
Agile
- E’ un insieme di idee e principi che fungono da stella polare per il management e lo sviluppo di un software (2001)
- Tali idee e principi rispondono a 4 valori fondamentali:
- Gli individui e le loro iterazioni più che i processi e gli strumenti.
- Dei software funzionali piuttosto che una documentazione esaustiva
- La collaborazione con i clienti piuttosto che la negoziazione contrattuale
- L’adattamento al cambiamento piuttosto che il rispetto di un progamma
- Declinati in 12 principi:
- Soddisfare il cliente in priorità.
- Accogliere favorevolmente i cambiamenti.
- Consegnare più spesso possibile delle versioni operazionali dell’applicazione.
- Assicurare una cooperazione permanente tra il cliente e l’equipe.
- Costruire dei progetti intorno a degli individui motivati.
- Prediligere la conversazione vis à vis.
- Misurare l’avanzamento di un progetto in termini di funzionalità dell’applicazione.
- Far avanzare il progetto ad un ritmo sostenibile e costante.
- Fare semplice.
- Responsabilizzare l’équipe.
- Apportare un’attenzione continua a l’eccellenza tecnologia.
- Aggiustare a intervalli regolari i proprio comportamento e i propri processi per essere più efficaci possibile.
- Esempi di technologie agili
- Intégration continue
- Test driven development (TDD)
- Conception pilotée par le domaine (DDD pour domain-driven design)
- Équipe transverse
- Burndown chart
- Programmation en binôme
- Planning poker
- Réusinage de code
- Timeboxing
- Récit utilisateur
- Suggerisce un approccio strutturato e iterativo alla gestione dei progetti e allo sviluppo del prodotto, più pragmatico dei metodi tradizionali.
- Riconosce la volatilità dello sviluppo del prodotto e fornisce una metodologia per l’auto-organizzazione dei team per rispondere al cambiamento senza uscire dai binari.
- Soprattutto oggi giorno nessuno ha il lusso di sviluppare un prodotto per anni o addirittura mesi in una scatola nera.
- Coinvolge al massimo il cliente
- Permette una grande reattività alle domande del cliente
- Principali tipi di implementazione di questi principi:
- Kanban =>
- E’ un metodo visivo di gestione dei progetti utilizzato per tenere traccia delle attività e ridurre le inefficienze in un progetto.
- Il cuore del metodo Kanban è la scheda Kanban (Kanban board) in cui le fasi del progetto sono suddivise in colonne.
- Le attività vengono scritte su schede che avanzano da una colonna all’altra, fino al completamento dell’attività
- Il team Kanban cerca di ottimizzare i tempi di sviluppo (di ogni singola user story) intervenendo regolarmente nella modifica del flusso di lavoro (sfrutta la visualizzazione dei task)
- Viene limitato il carico in progress per massimizzare l’efficienza.
- Il team lavora senza vere scadenze prefissate ma in flusso continuo.
- Non esistono ruoli predefiniti come nello scrum.
- Scrum =>
- E’ una metodologia Agile progettata per progetti complessi
- Si basa su brevi cicli di sviluppo chiamati sprint, che generalmente durano da 1 a 4 settimane.
- Utilizza un approccio iterativo per completare i progetti.
- Invece di consegnare un progetto tutto in una volta, i team completano e consegnano le attività in più fasi.
- Ciò rende più facile adattarsi ai cambiamenti e alle priorità in evoluzione.
- Scrum team
- Uno Scrum team è auto-organizzato, piccolo (in genere non più di nove persone) e comprende
- uno Scrum Master
- un Product Owner.
- il resto del team è chiamato team di sviluppo.
- Uno Scrum team è auto-organizzato, piccolo (in genere non più di nove persone) e comprende
- 4 tappe importanti
- Daily scrum => Incontro quotidiano (dovrebbe essere centrato sui task e non sulle persone).
- Sprint review => Alla fine di uno sprint si mostrano gli sviluppi realizzati.
- Sprint retrospective => Riunione equipe per revisionare task.
- Sprint planning => Definire il peso (in giorni) delle prossime tache.
- Kanban =>
- Tabella Riassuntiva
Scrum Kanban Origine Software development Lean manufacturing Idealogia Impara attraverso le esperienze, Auto-organizza e assegna le priorità
Rifletti su vittorie e sconfitte per migliorare continuamente.
Usa gli elementi visivi per migliorare i lavori in corso Cadenza Sprint regolari a lunghezza fissa Flusso continuo Pratiche Sprint planning Daily scrum
Sprint review
Sprint retrospective
Visualizza il flusso di lavoro Limita il lavoro in corso
Gestisci il flusso
Incorpora i circuiti di feedback
Ruoli Product owner, scrum master, development team Nessun ruolo richiesto
Ruoli in un progetto tradizionale
-
- MOA (maitre d’ouvrage)
- il cliente che ha bisogno da risolvere.
- AMO (maitre d’ouvrage délégué)
- la persona delegata dal MOA (che a volte non possiede l’esperienza sul campo necessaria a pilotare un progetto) a fare da interfaccia con il MOE.
- MOE (maitre d’ouvre) (project manager?):
- E’ scelto dal MOA e pensa i il progetta il piano da seguire, organizza, coordina, supervisiona i differenti utilizzatore che lavorano su un progetto ed è responsabile del deploy
- MOA (maitre d’ouvrage)
Architettura stateless vs stateful
- Applicazione statefull (con stato)
- Il server salva i dati di ciascuna sessione client e utilizza tali dati la prossima volta che il client effettua una richiesta.
- Applicazione stateless (senza stato)
- Il server non salva i dati del client generati in una sessione per l’uso nella sessione successiva. Al contrario, i dati della sessione vengono archiviati sul client e passati al server secondo necessità..
- Normalmente viene comunque gestire lo stato in qualche forma (non lato-server) =>
- Ogni sessione viene eseguita come se fosse la prima volta e le risposte non dipendono dai dati di una sessione precedente
- Le applicazioni Cloud e il loro bisogno di scalabilità (sono prettamente delle architetture distribuite) hanno un rinnovato interesse per le appplicazioni stateless. Questo perché:
- quando i componenti di un’app sono stateless, possono essere facilmente ridistribuiti in caso di errore e ridimensionati per adattarsi alle modifiche del carico.
- quando le app sono stateless, possono essere facilmente collegate ad altre app tramite le API (Application Program Interface).
- La programmazione funzionale (spesso usata per microservizi e containerizzazione) ha suscitato interesse per le app stateless.
- Essendo un approccio allo sviluppo del software che utilizza segmenti molto piccoli di codice immutabile. Ogni funzione esegue il proprio compito come se fosse la prima volta ed è a conoscenza, ma non dipende da, altre funzioni del programma.
- Poiché tutte le parti del programma sono stateless, i programmatori possono assemblare funzioni in più modi senza doversi preoccupare delle dipendenze che interrompono il programma.
Acid
- (A)tomicità => è garantito che un’insieme di operazioni legate in transazione o verrà completamente committato o rifiutato
- (C)onsistenza => ogni cambiamento al db lo deve mantenere in uno stato valido, in rispetto dei vincoli e trigger
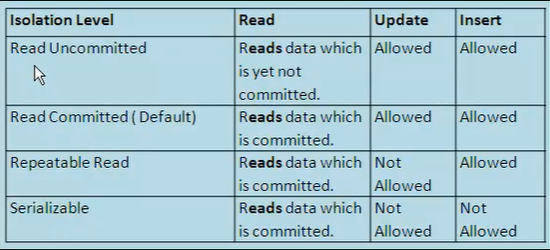
- (I)solamento (controllo della concorrenza, è definita a livello del DB ed è una proprietà che definisce come e quando i cambiamenti fatti da una transazione sono visibili alle altre) =>
-
- Serializable Read =>
- Massimo livello di isolamento.
- Ogni transazione lavora come se fosse l’unica.
- Può esssere implementato con il blocco in scrittura e lettura le intere tabelle coinvolte.
- Snapshot =>
- Altrimenti non blocco e se il sistema riconosce una collisione verrà applicato un comportamento ottimistico o pesssimistico.
- Repeteable Read =>
- Implementato con un blocco in scrittura e lettura i dati selezionati.
- Non permette update quando anche quando leggo. Ma permette insert =>
- Non evita il fenomeno dei “phantom read” [non essendoci il range-lock, è vero che un’altra transazione non può modificare o eliminare i miei dati ma potrebbe aggiungerne e da li generare delle letture fantasma a fronte di una seconda rilettura degli stessi dati]
- Read Committed =>
- Leggo solo i dati che sono stati committati
- Implementato senza bloccare in lettura (che è un’operazione onerosa) ma solo in scrittura.
- Quindi se leggo non blocco in modifica i dati letti. E se scrivo non blocco in lettura i dati scritti.
- Non evita il fenomeno delle “non-repeatable read” [se all’interno della stessa sessione leggo due volte lo stesso dato che non essendo bloccato può essere modificato e quindi una seconda rilettura darebbe un valore diverso].
- Default per SQL SERVER e ORACLE.
- Read Uncommitted =>
- Leggo anche i dati che non sono stati committati
- Nessun isolamento in quando non viene effettuato nessun blocco.
- Cado tra gli altri nel fenomeno delle “dirty read” [leggere dati non ancora committati].
- Esempio =>
- La prima transazione viene eseguita e poi fa il rollback
- La seconda transazione viene eseguita nel frattempo leggendo lo stesso record. Farà una ‘dirty read’ a causa del fatto che ha potuto leggere dei dati modificati ma non commitati
- Serializable Read =>
![]()
![]()
-
- Dove è possibile impostare il livello d’isolamento =>
- (D)urabilità: =>
- una transazione committata rimante tale anche in caso di caduta nel sistema, questo perchè è memorizzata in una regione non-volatile di memoria in attesa si essere applicata al db stesso.
Controllo della concorrenza
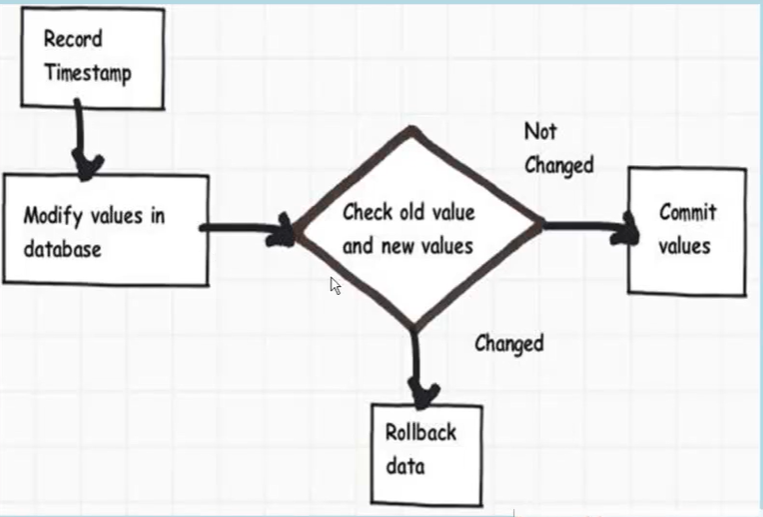
- Optimistic Locking (posso accettare dati sporchi, come su un sito) =>
- E’ un approccio di gestione dei conflitti che li lascia arrivare ma deve rilevarli prima di fare il commit che crea il conflitto stesso.
- E’ implementato leggendo un record e tenendo traccia della sua versione (rowid, hash, timestamp). Quando scrivo controllo che la versione è quella e proseguo. Se nel frattempo ho avuto un accesso concorrente allo stesso record, abortisco (TRANSACTION ROLLBACK) e riprovo.
- Per funzionare è necessario che prima di ogni operazione di update e delete il sistema faccia una select sul record per conoscerne la versione e usarla per modificarne/eliminarne il valore.
- E’ un approccio che aumenta la concorrenza ma diminuisce la prevedibilità. E’ applicabile a sistemi con alti volumi e architettura 3-tier dove non sia necessario mantenere attiva una connessione per la sessione e ai sistemi dove mi aspetto poche collisioni
- Pessimistic Locking (non posso accettare dai sporchi, come in una banca) =>
- E’ un approccio di gestione dei conflitti che cerca di evitarli. Infatti implementa il blocco di un record per uso esclusivo finchè non ho finito.
- Aumenta l’integrità ma bisogna fare attenzione al DEADLOCK. E’ necessario un collegamento continuo al DB (tipico nelle strutture 2-tier).
Architecture
- 2-Tier architecture (Client Layer, Data Layer) =>
- la business logic è nascosta lato client (user interface) o lato server (database)
- 3 Tier architecture (Client Layer, Business Layer, Data Layer) =>
- più sicura dell’architettura a 2 livelli, aggiunge un livello di astrazione tra l’interfaccia cliente e la base di dati.
Memory manegement
- Call stack (pile d’esecution) :
- Porzione di memoria dove si registrano le chiamate attive di un programma in particolare gli indirizzi del chiamante, che prendono l’ultima posizione dalla pile e vengono liberati quando la routine chiamata finisce l’operazione e ritorna il controllo all’istruzione segnata in testa alla pile.
- Se si annidano troppe chiamate a subroutine senza che queste finiscano prima la loro esecuzione si arriva al fenomeno dello stack overflow.
- Array di memoria.
- LIFO.
- è una pila.
- allocazione di memoria statica.
- contiene il valore variabili di tipo valore.
- contiene il riferimento alla memoria heap delle variabili di tipo referenza.
- accesso veloce.
- accessibile solo all’owner thread.
- la ricorsione potrebbe riempire velocemente questo tipo di memoria.
- le variabili sono pulite una volta fuori dallo scope.
- Heap memory :
- è un’area di memoria in cui vengono allocati blocchi per memorizzare determinati tipi di oggetti.
- I dati possono essere memorizzati e rimossi in qualsiasi ordine.
- allocazione di memoria dinamica.
- contiene il valore delle variabili di di tipo referenza.
- accesso lento.
- accessibile a tutti i threads.
- la recursione riempie meno velocemente questo tipo di memoria.
- ripulita dal GC (garbage collector).
- Se una variabile risiede nello stack o nell’heap è importante soprattutto nel caso del multithreading.
- Closures :
- Higher-order function (HOF) => Nel caso un metodo ritorni una funzione (es: factory pattern) e tale funzione usi una variabile di tipo valore definita in tale metodo allora esiste un problema di sincronia tra la durata in memoria della funzione in uscita e della variabile.
- Il compilatore “promuove’ quindi la variabile dallo stack all’heap affinché essa possa essere esiste per la stessa durata della funzione.
- Dietro la scena il compilatore crea una classe dove mette la variabile presente nel metodo e la funzione ritornata dal metodo.
-
Func<int, int> calculator = CreateCalculator(); var res = calculator(2); //84 Func<int, int> CreateCalcultator() { var factor = 42; return n => n * factor; } //Internamente il compilatore accorgendosi che la funzione calculator(..) internamente usa // la variabile 'factor' fa in modo che essa risiede in memoria // per la stessa durata della funzione stessa. Quindi la variabile 'factor' non risiede // più nello stack del funzione CreateCalculator() ma nell'heap //Il compilatore crea una classe che lega la variabile e la funzione e utilizza // un'istanza di tale classe (memorizzata nell'heap) //Percio' la variabile 'factor' viene passata dallo stack all'heap // e tale variabile e la funzione calculator sono 'closures' (best friends)
-
- Memoria virtuale :
- E’ una tecnica di gestione della memoria che riguarda la traduzione di indirizzi di memoria virtuale (dei numeri binari) generati dai programmi in esecuzione in indirizzi di RAM reale, compito a carico del sistema operativo e della MMU (Memory Management Unit).
- Fin quando c’è memoria disponibile, la traduzione di indirizzi virtuali-reali avviene direttamente nella RAM libera.
- Quando uno o più processi richiedono ulteriore memoria ma la RAM è esaurita, le PAGINE di RAM occupate che non servono all’elaborazione vengono copiate su disco nel FILE di PAGING, quindi liberate e messe a disposizione dei processi che le richiedono. Se le stesse pagine serviranno di nuovo all’elaborazione, verranno di nuovo copiate questa volta dal FILE di PAGING alla RAM (swapping).
Fondamenti della OOP
- OOP vs Programmazone procedurale :
- Problemi (RESM)
- Reusabilità => Astrazione, incapsulamento (Classi e oggetti).
- Estendibilità => Ereditarietà
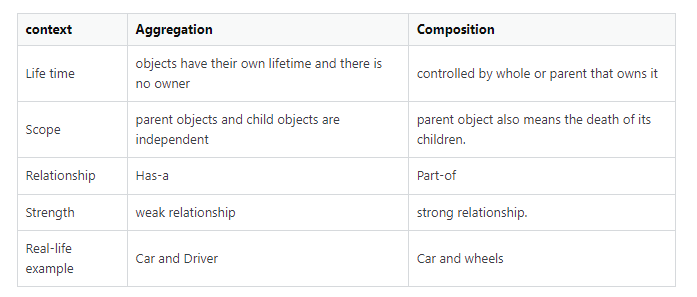
- Aggregazione (B è usato da A ma esiste anche come entità singola).
- Composizione (B appartiene ad A e non esiste come entità singola).
- Simplicitià => Polimorfismo + Astrazione, incapsulamento.
- Mantenibilità => Tutte le soluzioni ai 3 problemi precedenti danno un codice più facile da mantenere.
- Problemi (RESM)
- Cosa é:
- Invece di pensare un programma come un insieme di funzioni tecniche lo si pensa come un insieme di oggetti (classi).
- E’ un approccio alla concezione che obbliga a pensare la nostra applicazioni in termini di oggetti del mondo reale.
- Oggetti / Classi :
- Una classe deve riflettere le entità del dominio di applicazione => Real team objects.
- Nomi (entità/data) => diventano attributi/fields della classe.
- Verbi (azioni/comportamenti) => diventano metodi/funzioni della classe.
- Una classe può essere considerato come una cosa che può fare un’insieme di attività.
- Tale classe è resa viva quando la si istanzia e la si carica in memoria.
- Pascal case:
- nome delle classi.
- nome dei metodi.
- Camel case:
- nomi degli attributi
- nomi dei parametri dei metodi.
- Una classe deve riflettere le entità del dominio di applicazione => Real team objects.
- Static class :
- Classi fisse che non rappresentano il business model della nostra applicazione:
- Sono delle utility.
- Slegate concettualmente dagli oggetti del mio business model.
- Sono fisse e non possono essere estese o ereditare.
- Una classe statica rappresenta il concetto di singleton :
- una sola istanza di tale oggetto in memoria .
- il costruttore viene eseguito una e una sola volta.
- Sono utili per il caching.
- No abstract, no inheritance, no interfaces, no polimorfismo.
- Perche usare static?
- Raggruppare metodi non legati al nostro business model.
- Condividere dati comuni.
- Fare il caching.
- Classi fisse che non rappresentano il business model della nostra applicazione:
- Partial class :
- (main reason) Permettono di customizzare del codice auto-generato (es: Entity Framework).
- E’ una classe scritta in 2 o più file ma viene compilata come un’unica classe.
- Possono essere anche usate per:
- Semplificare una classe grossa spezzandola in più file.
- Lavorare in più persone su una sola classe.
- Tipi di class members :
- Instance
- Sono metodi accessibili solo dopo aver istanziato la classe.
- Static
- Sono metodi accessibili direttamente dalla classe.
- Fissi che non possono essere estesi, ereditati.
- Instance
- OOP è un processo a 3 fasi :
- Template creation:
- Creare classi e la loro logica interna.
- Instantiate:
- Creare oggetti/istanze di queste classi e farle vivere nella RAM del computer.
- Runtime:
- Interagire con questi oggetti per ottenere le funzionalità desiderate.
- Template creation:
- Costruttore :
- E’ un metodo chiamato quando un’istanza della classe è creata.
- E’ un metodo con lo stesso nome della classe e senza nessun tipo di ritorno.
- L’obiettivo è di mettere l’oggetto in uno stato “iniziale”.
- Il compiler ne crea uno in automatico.
- E’ possibile creare più versioni del costruttore (constructor overloading).
- Nel costruttore inizializzare sempre eventuali liste presenti negli attributi della classe.
-
public class Customer { public int Id; public string? Name; public List<Order> Orders; public Customer() { Orders = new List<Order>(); } public Customer(int id) : this() { Id = id; } public Customer(int id, string name) : this(id) { Name = name; } }
-
- Inizializzatore di oggetti (object initializers) :
-
var customer = new Customer { FirstName = "John", LastName = "Fitz" };
-
- Modificatori di accesso (Access modifiers) :
- Sono parole chiave usate per settare l’accessibilità di classi e membri.
- Black box / Loose coupling:
- Implementano l’incapsulamento.
- Una classe deve nascondere al mondo esterno le sue implementazioni interne per aumentarne l’affidabilità (in caso di modifiche) ed estendere così il principio del loose coupling.
- Top-level
- Internal (default).
- Public.
- Non top-level (classi e membri)
- Private (default).
- Possibili valori =>
- Private:
- Accessibilità di tipi o membri solo all’interno della propria classe o struct.
- Public:
- Accessibilità in tutto il codice del proprio assembly.
- Accessibilità in qualsiasi altro assembly che lo referenzia.
- Protected (meglio non usarlo):
- Accessibilità nella propria classe.
- Accessibilità nella classi derivate dalla propria classe.
- Internal:
- Accessibilità all’interno del proprio assembly (cioè del codice che è parte della stessa compilazione).
- Protected Internal:
- Accessibilità nel proprio assembly.
- Accessibilità in una classe derivata in un altro assembly.
- Private Protected [obsolete]:
- Accessibilità solo all’interno in classi derivate dalla stessa che fanno parte dello stesso assembly
- Private:
- Regole generali =>
- I namespaces sono public per default e non accettano nessun altro modificatore.
- La classe base deve avere un’accessibilità uguale o maggiore della classe derivata.
- Un metodo non può ritornare un tipo con accessibilità inferiore alla propria.
- Costanti :
- Le costanti assumono un valore al momento in cui sono definite (e non in un secondo momento nel codice).
- Sono static di default.
- Fields/Campi :
- Fields != Proprietà :
- I campi stoccano dati e non hanno nessuna logica.
- I campi di una classe possono essere inizializzati:
- Nel costruttore.
- Direttamente nella dichiarazione.
- Le variabili usate da appoggio per le proprietà devono avere lo stesso tipo.
- Normalmente sono:
- Private.
- camelCase.
- Fields != Proprietà :
- Attributi :
- Sono informazioni che possono essere associate alle classi, metodi, proprietà (Per es: [Obsolete(“This method is outdated”, true)])
- Custom attribute =>
-
class Customer { [Check(MaxLenght=10)] public string Name {get; set;} } //Inherited (false|true): indico se l'attributo è visibile anche in una classe che eredita dalla mia //AllowMultiple (false|true): indico se è possibile usare l'attributo su più proprietà (o metodi) di una classe [AttributeUsage(AttributeTargets.Property, Inherited = false, AllowMultiple = true)] class Check : Atribute { public int MaxLenght {get; set;} }
-
- E’ possibile usare la reflection per leggere gli attributi e creare della logica in funzione dei loro valori recuperati a runtime.
- Proprietà :
- E’ un membro della classe che contiene un get e un set per gestire un’attributo della classe.
- Incapsula e nasconde il proprio funzionamento al programma finale che la richiama.
- Proprietà != campi
- Una proprietà esegue un metodo mentre una campo/variabile inizializza un pezzo di memoria.
- Proprietà readOnly != constanti
- Le proprietà readonly non devono necessariamente essere inizializzate al momento creazione ma anche nel costruttore.
- Assumono un valore solo a runtime e questo valore può essere cambiato (nel costruttore).
- Non può ritornare un tipo void.
- Accessor get/set =>
- Devono essere dichiarate con un accessor get/set.
- Gli accessor possono contenere della logica.
- I due accessor devono essere definiti in un unico pezzo di codice, non posso essere dichiarazioni separate.
- ReadOnly => è una proprietà con il solo accessor get;
- WriteOnly => è una proprietà con il solo accessor set.
- Proprietà auto-implementate
-
//Il compilatore crea una variabile privata al posto nostro public DateTime BirthDate { get; set; }
-
- Può essere static.
- Può essere abstract:
- Nella classe derivata ci sarà una proprietà con lo stesso nome e il modificatore override.
- Altrimenti si comporta come se ci fosse new. La proprietà della classe derivata deve implementare gli stessi Accessor della presenti nella proprietà abstract della classe padre.
- E’ un membro della classe che contiene un get e un set per gestire un’attributo della classe.
- Indexers :
-
<return type> this[<parameter type> index] { get { // return the value from the specified index of an internal collection } set { // set values at the specified index in an internal collection } } - E’ un modo semplificato per accedere agli elementi di una collezione all’interno di una classe.
- Sono simili alle proprietà ma i loro Accessor prendono dei parametri.
- Hanno bisogno di get, set.
- Sono definiti con la parola chiave this.
- Non possono essere static.
- ArrayList e List usano al loro interno gli indexers per implementare la ricerca degli elementi.
- Può essere un numero o una stringa.
-
//esempio 1 class Program { var cookie = new HttpCookie(); var name = cookies["name"]; public class HttpCookie { public string this[string key] { get {...} set {...} } } } //esempio 2 class Program { public void Main(strings[] args) { var customerAge23 = Customers[23]; var customerNamePippo = Customers['pippo']; } public class Customer { public string Name; public int Age; public List<Customer> customers = new List<Customer>(); public Customer this[int age] { get { foreach(Customer cust in customers) { if(cust.age == age) return cust; } return null; } set {} } public Customer this[string name] { get { foreach(Customer cust in customers) { if(cust.name == name) return cust; } return null; } set {} } }
-
- Metodi e i propri parametri :
- Signature :
- la signature di un metodo è data da:
- nome del metodo.
- ordine dei parametri.
- tipo dei parametri (c# riconosce il metodo chiamato dai tipi dei parametri chiamati e non solo dai loro nomi)
- Il nome di un parametro deve essere univoco.
- la signature di un metodo è non dipende da:
- Il tipo del parametro di ritorno del metodo.
- I modificatori di accesso (ad es static, private).
- la signature di un metodo è data da:
- Overloading (= metodi con lo stesso nome ma signature differenti)
-
public class Point { public int X; public int Y; public void Move(int x, int y) { this.X = x; this.Y = y; } public void Move(Point newlocation) { this.Move(newlocation.X, newlocation.Y); } }
- Operator overloading:
- E’ possibile ridefinire (overload) la più parte degli operatori predefiniti in C# (es: +,-) affinché svolgano delle operazioni specifiche su classi custom:
-
//Esempio 1 var o1 = SomeClass(10); var o2 = SomeClass(20); var o3 = o1 + o2; class SomeClass { private int someValue; public SomeClass(int val) { someValue = val; } public static SomeClass operator +(SomeClass arg1, SomeClass arg2) { return new SomeClass(arg1.someValue + arg2.someValue); } } //Esempio 2 Class Box { private double length; private double length; private double length; public static Box operator+ (Box b, Box c) { Box box = new Box(); box.length = b.length + c.length; box.breadth = b.breadth + c.breadth; box.height = b.height + c.height; return box; } } var box1 = new Box(); var box2 = new Box(); var box3 = box1 + box2;
-
- Passare parametri a un metodo:
- Valore (viene passato al metodo il valore della variabile a) :
-
metodo(int a)
-
- Referenza (viene passato al metodo l’indirizzo di memoria della variabile a) :
-
metodo(ref int a)
-
- Parametro in output (viene passato al metodo l’indirizzo di memoria della variabile a) :
-
metodo(output int a)
-
- tramite array (deve essere all’ultimo posto tra i parametri del metodo) :
-
metodo(params int[] a) //esempi di utilizzo my_class.metodo(new int[]{1,2,3,4}); my_class.metodo(1,2,3,4);
-
- Valore (viene passato al metodo il valore della variabile a) :
- Signature :
Tipi di relazione tra classi (meccanismi di condivisione del codice)
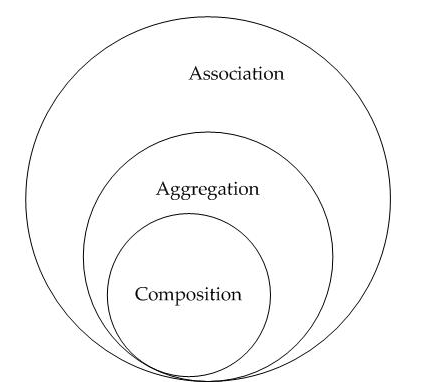
-
- Ereditarietà (Inheritance):
- E’ una relazione del tipo Is-A (es: un macchina è un veicolo).
-
public class macchina : veicolo { .. }
-
- In UML è una freccia che va dal figlio al padre.
- Sintassi dedicata in c#.
- Pros =>
- Reusabilità del codice.
- Facile da capire.
- Cons =>
- Tight coupling.
- Fragile.
- E’ una relazione del tipo Is-A (es: un macchina è un veicolo).
- Associazione
- E’ una relazione del tipo Has-A.
- E’ in modo generale una relazione tra 2 classi generalmente semanticamente debolmente correlate:
- In cui non é facile identificare un’entità owner e una posseduta.
- Un ordine puo’ avere tanti clienti e un cliente puo’ avere tanti dottori.
- Aggregazione
- E’ una relazione del tipo Has-A +Whole-Part/Child-Parent.
- E’ un tipo speciale di associazione dove esiste un’entità owner e una posseduta e le due possono esistere anche separatamente.
-
//A Playlist has many songs //Le canzoni posso esistere senza una playlist public class PlayList { private List<Song> songs; } oppure public class Computer { private Monitor monitor; } oppure public class Foo { private Bar bar Foo(Bar bar) { this.bar = bar; } }
- Composizione =>
- E’ una relazione del tipo Has-A + Whole-Part/Child-Parent + Part-of (es: una macchina ha un motore).
- E’ un tipo speciale di aggregazione dove l’entità posseduta non puo’ esistere senza l’owner:
-
//A flat has many rooms //Le stanze non posso esistere senza appartamento public class Flat { private Room bedroom; public Flatt() { bedroom= new Room(); } } oppure public class Foo { private Bar bar = new Bar(); }
-
- In UML è un rombo nero più una piccola freccia che va verso il componente collegato.
- Non c’è una sintassi particolare in c#:
- Semplicemente la classe collegata è un campo privato e inizializzato nel costruttore della classe consumer).
- Una relazione di ereditarietà può essere tradotta in una relazione di tipo composizione.
- Pros =>
- Loose coupling.
- Grande flessibilità.
- Cons =>
- Può essere più difficile da capire.
- Ereditarietà (Inheritance):
I 4 pilastri della OOP
- 4 Pilastri della OOP
- Incapsulamento / Encapsulation :
- Riduce la complessità nascondendola.
- Aumenta la riusabilità.
- Ereditarietà / Inheritance :
- Elimina ridondanza del codice e permette la estendibilità del codice.
- Polimorfismo / Polymorphism :
- Sostituisce semplificandoli i comandi switch/if.
- Un oggetto può apparire differentemente e agire diferentemente a secondo delle condizioni.
- Astrazione / Abstraction :
- Riduce la complessità nascondendola:
- Esponendo solo le proprietà/metodi necessari.
- Nascondendo le implementazioni non necessarie in fase di design della mia applicazione.
- Isola l’impatto delle modifiche.
- Astrazione e incapsulamento vanno insieme.
- La prima offre un’approccio concettuale.
- La seconda ne esplicita l’implementazione (l’incapsulamento implementa l’astrazione).
- Riduce la complessità nascondendola:
- Incapsulamento / Encapsulation :
- Incapsulamento :
- Centralizzazione :
- L’incapsulamento è legato al concetto di “impacchettare” in un oggetto i dati e le azioni che sono riconducibili ad un singolo componente così da poterle meglio gestire:
- attributi
- metodi
- L’incapsulamento è legato al concetto di “impacchettare” in un oggetto i dati e le azioni che sono riconducibili ad un singolo componente così da poterle meglio gestire:
- Occultamento dell’informazione / Information hiding
- Tale concetto esprime l’abilità di nascondere al mondo esterno tutti i dettagli implementativi più o meno complessi che si svolgono all’interno di un oggetto.
- Mostrarne solo le funzionalità disponibili.
- Access modifier
- Permettono l’implementazione dell’incapsulamento.
- Centralizzazione :
- Ereditarietà :
- E’ un tipo di relazione tra 2 classi che permette a una classe figlia di ereditare delle caratteristiche da una classe genitore:
- Upcasting (conversione implicita da oggetto derivato => a oggetto base)
-
DerivedCls derivedObj = new DerivedCls(); BaseCls baseObj = derivedObj; //conversione implicita
- C# può castare un oggetto figlio alla classe padre in modo implicito.
- Nell’uso pratico è possibile quindi passare un oggetto figlio anche quando quello atteso è un oggetto di tipo padre.
-
- Downcasting (conversione esplicita da oggetto base => a oggetto derivato)
-
DerivedCls derivedObj = (DerivedCls)baseObj; //conversione esplicita necessaria
- Può causare un’ InvalidCastExeption:
-
//Risolvo usando la parola chiave as DerivedCls derivedObj = baseObj as DerivedCls if(derivedObj != null) { ... } //grazie alla parola chiave as, non avrò un'InvalidCastException ma l'oggetto bc2 rimarrà nullo //Risolvo usando la parola chiave is if (baseObj is DerivedCls) { DerivedCls derivedObj = (DerivedCls)baseObj; }
-
- Nell’uso pratico posso castare per esempio un oggetto generico sender nella sua specializzazione (es: button).
-
Button button = (Button)sender;
-
-
- Classe genitore (superclasse / classe base / generalizzazione) :
- Permette di accentrare della caratteristiche comuni condivise da più entità.
- Downcasting non è sempre possibile (potendo quest’ultima contenere delle proprietà e dei metodi che la classe base non ha):
- Usare parola chiave as per non ricevere un’ InvalidCastException
- Verificare se possible castare la padre dalla classe figlio con la parola chiave is
- Attenzione: qualora il downcasting sia possibile allora il padre si comporta come il figlio (indipendentemente se nel figlio si usa override o new).
- Classe figlia (sottoclasse / classe derivata / specializzazione) :
- Permette di specializzare il comportamento di entità che hanno delle caratteristiche comuni (implementate nella classe padre).
- Upcasting :
- E’ possibile castare un oggetto figlio alla sua classe padre (un figlio può essere visto come un oggetto della classe padre).
-
DerivedCls derivedObj = new DerivedCls(); BaseCls baseObj = derivedObj; //un oggetto referenza può essere implicitamente convertito //nella sua classe base
- Metodo classe genitore definito come virtual :
- Quando un metodo di una classe base è dichiarato virtual, il comportamento del metodo è deciso solo a runtime.
- Abbiamo il permesso di sovrascrivere tale metodo nelle classi derivate :
- Se il flglio fa l’override del padre allora quando il figlio si comporta come padre eseguirà il proprio metodo (e non quello del padre).
- Il modificatore override ci dice che il metodo figlio prende il sopravvento rispetto a quello del padre che per essere chiamato va usata la parola chiave base.
- Se la classe figlia fa un override di un metodo virtual allora il metodo non può cambiare i parametri passati al metodo o il tipo di ritorno.
- Se il figlio fa il new del padre allora quando il figlio si comporta come padre eseguirà il metodo del padre (e non il proprio).
- Il modificatore new ci dice che il metodo figlio pur avendo lo stesso nome di quello della classe padre è da esso completamente slegato (spezza la catena):
- Se il flglio fa l’override del padre allora quando il figlio si comporta come padre eseguirà il proprio metodo (e non quello del padre).
-
class Padre { public virtual string Metodo1() { return "padre"; } } //Caso OVERRIDE class Figlio : Padre { public override string Metodo1() { return "figlio"; } } //il figlio agisce da padre Padre padre = (Padre) new Figlio(); // avere fatto l'override permette all'oggetto padre di accedere al method1 che è definito nella classe figlio. padre.medodo1() => "figlio"; //Caso NEW class Figlio : Padre { public new string Metodo1() { return "figlio"; } } //il figlio agisce da padre Padre padre = (Padre) new Figlio(): // avendo usato la parola chiave new, l'oggetto padre non può accedere al metodo del figlio e eseguirà il suo metodo: padre.medodo1() => "padre";
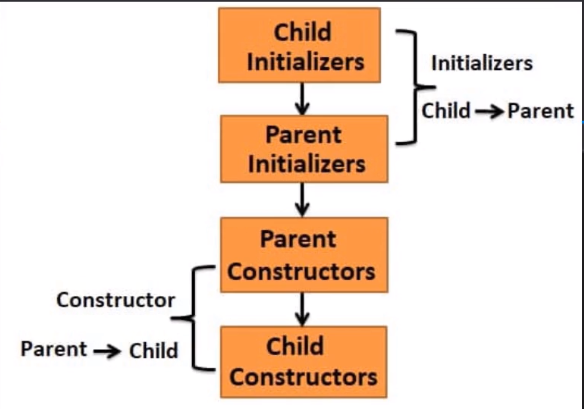
- Costruttore :
- La classe figlia eredita tutto tranne costruttori e decostruttori.
- Quando istanzio una classe figlia vengono eseguiti:
- Il costruttore della classe base (per primo).
- Successivamente il costruttore della classe figlia.
- Base :
- La chiave riservata base può essere usata nella classe derivata per chiamare le implementazione del costruttore o i metodi definiti nella classe base :
-
public class Car: Vehicle { public Car(sting param1): base(param1) { ... ... } public ControllaMotore() { base.ControllaMotore(); } }
- Tipi di ereditarietà =>
- Multilivello
- Una classe eredita da una classe che a sua volta eredità da una classe.
- Multipla
- Una classe eredita da più di una classe.
- Attenzione: C# non supporta l’ereditarietà multipla
- In quanto una classe può derivare da una e una sola classe.
- Può essere realizzata invece tramite interfacce.
- Ibrida
- Multilivello + Multipla
- Gerarchica
- Una classe base ha più classi figlie (vehicle ha car, bike)
- Multilivello
- Vantaggi :
- Estendibilità e mantenibilità del codice (potendo accentrare caratteristiche comuni alle entità della mia applicazione)
- Comportamento polimorfico.
- Svantaggi :
- I metodi virtual si eseguono più lentamente.
- La dipendenza circolare non è permessa.
- Le classi base e figlie sono strettamente legate (modifiche in una posso avere impatto nell’altra).
- Shadowing :
- Quando un elemento del padre (es: proprietà) è completamente ridefinito dalla classe figlia (es: facendone un metodo).
- E’ simile ad usare la parola chiave new nel figlio (rompo la catena di eredità).
- Polimorfismo :
- Cosa é :
- Dà la possibilità di aggiungere della logica senza impattare il codice precedentemente scritto.
- Possibilità di un oggetto di assumere più forme, cioè la possibilità di un oggetto (classe) di mostrare più implementazioni di una singola funzionalità (in base alla situazione).
- Permette di sostituire le lunghe dichiarazioni scritte usando ‘if’ o lo ‘switch case’ tipici della programmazione procedurale.
- Consente ad oggetti diversi ma correlati (dalla classe da cui ereditano) di rispondere in modo diverso allo stesso tipo di messaggio.
- Cambiare l’implementazione di un metodo ereditato.
- Vantaggioso per la di manutenzione del codice.
- Tipi :
- Polimorfismo statico o a compile time (Method overloading o Early Binding).
- Polimorfismo dinamico o a run time (Method overriding o Late Binding).
- Cosa é :
- Astrazione :
- Permette di rappresentare in modo più semplice le cose esponendo solo le proprietà necessarie nascondendo i dettagli di implementazione.
- E’ possibile implementare l’astrazione tramite
- Classi astratte.
- Metodi astratti.
- Interfacce.

-
- Classe astratta =>
- Se una classe ha anche un solo metodo abstract deve essere dichiarata come abstract.
- Una classe abstract non può essere istanziata => Deve essere ereditata.
- Classe pura
- Una classe astratta con tutti i metodi astratti è detta pura => Attenzione a non usarla come alternativa ad un’interfaccia
- Una classe abstract è una classe padre definita parzialmente la quale dovrà essere fornita dalle classi derivate:
- Lo scopo di una classe abstract è fornire una definizione comune che molteplici classi derivate posso condividere.
- Le classi derivate faranno override dei metodi abstract definiti nel padre.
-
public abstract class Shape { //CASO 1 => la classe figlia DEVE implementare questo metodo public abstract void Draw(); //CASO 2 => La classe figlia (Circle) ha a disposizione tale metodo come se fosse presente in essa public void TurnOn() { Console.WriteLine("Turning on"); } //CASO 3 => La classe figlia ha a disposizione tale metodo come se fosse presente in essa (come CASO 2) // la classe figlia puo' decide di implementare diversamente tale metodo (come CASO 1) public virtual void TurnOff() { Console.WriteLine("Turning on"); } } public class Circle : Shape { public override void Draw() { //implementazione specifica per la classe Circle } }
-
- Classi e membri sealed (opposto delle classi abstract) =>
- Una classe sealed non può essere derivata.
- Un metodo sealed non può essere sovrascritto (overridden).
- Aumentano le performance.
- Raramente usato.
- Metodi astratti
- Non devono contenere implementazione e quindi non può essere chiamati.
- Tutti i metodi definiti abstract devono essere implementati nella classe derivata.
- Si usa un membro astratto quando non ha senso implementarlo in una classe. Tale metodo è implicitamente virtual (il figlio ne deve fare l’ovverride)
- Un metodo di una classe abstract può essere vuoto solo se marcato con i modificatori
- abstract
- extern
- partial
- Interfacce :
- Cose é :
- Un’interfaccia definisce un contratto specificando i membri che una classe che implementa tale l’interfaccia deve avere.
- Cioè ne dichiara solo le funzionalità che questa deve fornire.
- Avere un contratto da rispettare significa avere più controllo sulla gestione dei cambiamenti
- Interfacce != ereditarietà
- Interfacce != abstract :
- Ha lo stesso effetto di una classe abstract con tutti i metodi abstract.
- Eppure le interfacce definiscono un modello più generico rispetto alle classi astratte pure.
- Eppure usare un’interfaccia ha un costo di computazione inferiore rispetto ad una classe abstract.
- Un’interfaccia è implementata.
- Aiuta a identificare l’astrazione.
- Le interfacce posso essere usate per implementare il polimorfismo runtime.
- Tutti i metodi di un interfaccia sono abstract.
- Segregazione dell’interfaccia.
- Un’interfaccia definisce un contratto specificando i membri che una classe che implementa tale l’interfaccia deve avere.
- Eredità multipla :
- E’ possibile ereditare da più interfacce.
- E’ la maniera per gestire un cambiamento in un’interfaccia (un nuovo metodo) senza danneggiare la presente implementazione.
- Proprietà generali :
- Non ha nessuna implementazione dei suoi membri ma solo le loro definizioni.
- Non possono contenere access modifier.
- Non accetta field ma solo proprietà e metodi.
- Per convenzione iniziano con il prefisso I.
-
public interface IInterfaceExample { void MetodoDaImplementare(); }
-
- Classe che implementa l’interfaccia =>
- Una classe può implementare una o più interfacce.
- I metodi della classe che implementa l’interfaccia devono essere public.
- Vantaggi :
- Loose coupled :
- Le interfacce danno la possibilità di progettare applicazioni debolmente accoppiate nella quali è possibile cambiare un componente senza impattare sugli altri. Infatti interponendo tra 2 classi un’interfaccia se ne riduce la dipendenza.
- Standardizzazione :
- del vocabolario.
- delle implementazioni.
- All’interno di una classe non è opportuno inizializzare altre classi ma è meglio iniettare le dipendenze a tali classi nel costruttore (che si aspetterà delle interfacce) e passare le classi concrete solo in fase di inizializzazione della classe.
- In una classe che dipende da un’interfaccia (e non da una classe concreta) semplicemente cambiando la classe concreta fornita a runtime è possibile modificare il comportamento senza modificare il codice al suo interno =>
- Maggiore testabilità (per poter eseguire un unit test su una classe è necessario isolarla perciò implementazioni che utilizzano le interfacce rendono i test più facili diminuendo la dipendenza tra classi).
- Estensibilità del codice
- Comportamento polimorfico (è solo a runtime passando una o l’altra implementazione dell’interfaccia che viene deciso quale comportamento avrà la classe che dipende da tale interfaccia).
- Rispetto del principio Open-close (le interfacce permettono di progettare classi che rispettano tale principio, cioè classi aperte alle estensioni ma chiuse alla modifiche).
- Loose coupled :
- Cose é :
- Classe astratta =>
HTTP Basic
- HTTP Status Code =>

-
- 100 => Codici per informazioni scambiate tra server e client
- 101:
- Il server risponde al client che ha positivamente switch di protocollo
- 101:
- 200 (Richiesta HTTP ha avuto esito positivo)
- 100 => Codici per informazioni scambiate tra server e client
-
-
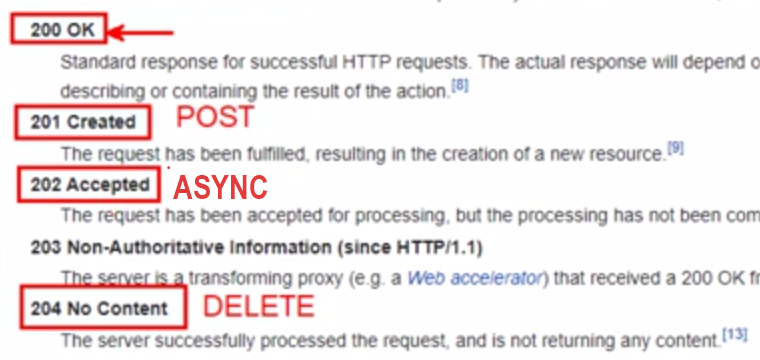
- *** 200 Ok ***:
- Il server risponde con successo alla richiesta del client
- *** 201 Created ***:
- Il server risponde che la richiesta del client di creare (POST) una risorsa è andata a buon fine
- Da usare in risposta a richieste con method=POST
- 202 Accepted:
- Il server risponde che la richiesta è stata presa in carico e ne è stata schedulata l’esecuzione
- Da usare per comunicazioni asincrone con lunghe elaborazioni
- *** 204 No content ***:
- Il server ha processato con successo la richiesta e non è stato ritornato nessun contenuto
- Da usare in risposta a richiesta con method=DELETE
- *** 200 Ok ***:
- 300 (Operazioni di redirezione)
- 301 Moved Permanently:
- Il server risponde con l’indirizzo a cui la risorsa richiesta è stata permanentemente redirezionata
- Da usare per avvisare il client che la risorsa in questione è da ora in poi è disponibile all’URI fornito nella risposta
- 307 Temporary Redirect:
- Il server risponde con l’indirizzo a cui la risorsa richiesta è stata temporaneamente redirezionata
- 301 Moved Permanently:
- 400 => (Problema lato client, nella formulazione della richiesta HTTP)
- *** 400 Bad Request ***:
- Da usare quando il client invia una richiesta che malformata sintatticamente, che non può essere interpretata dal server
- 401 Unathorized:
- Rifiuto specifico per il richiedente.
- Da usare quando il server rifiuta allo spefifico chiamante qualcosa che generalmente è permessa.
- 403 Forbidden:
- Rifiuto generalizzato.
- Da usare quando il server rifiuta in modo generale di fare ciò che la ‘richiesta HTTP’ sta chiedendo.
- 404 Not Found:
- Pagina non richiesta
- 405 Method Not Allowed:
- Simile a 403,
- Da usare quando la risorsa richiesta e non permessa è specificatamente un metodo
- *** 400 Bad Request ***:
- 500 => (Problema lato server)
- *** 500 Internal Server Error ***:
- Il server risponde con un messaggio generico di errore quando una condizione inaspettata si verifica e un messaggio di dettagliato non è utilizzabile
- 501 Not Implemented
- Il server risponde che ha potuto elaborare la richiesta del client ma la risorsa richiesta non è stata ancora implementata.
- Da usare quando una particolare funzione non è stata ancora implementata
- 504: il server non ha rispostoi
- *** 500 Internal Server Error ***:
-
- Request-Headers
- L’intestazione della richiesta del client è formata da molte coppie chiave-valore
- Accept => Indica il formato dei dati che il client accetta come risposta dal server.
- Authorization => Il client invia informazioni sulla sua identità
-
Authorization: Basic user:password Authorization: Bearer Token (OAuth2.0)
-
- Round-trip cookies
- Il client può reinviare al server alcuni cookies che il server gli aveva precedentemente inviato.
- L’intestazione della richiesta del client è formata da molte coppie chiave-valore
- Response-Headers
- L’intestazione della risposta del server è formata da molte coppie chiave-valore
- Cookies
- Il server può inviare al client alcune informazioni memorizzate in cookies.
- Round-trip cookies
- Il server può ricevere indietro alcuni cookies che aveva precedentemente inviato al client.
- Cookies
- L’intestazione della risposta del server è formata da molte coppie chiave-valore
EOL characters
- Windows => CRLF
- Linux/Unix => LF
- Mac OS => CR
- Mac OSX (dopo 2015) => LF
Relazioni del DB
- Grado (degree) => unario o binario (nella maggior parte dei casi).
- Molteplicità => 0 a 1, 1 a 1, 1 a molti, molti a molti.
- Direzione => unidirezionale o bidirezionale.
JSON vs YML
-
Principi per trasformare JSON in YML - Un file YML inizia con --- - Per le stringa non ha bisogno di single quote (') o double quote ("") - Non ha bisogno delle virgole a fine linea - Gli array diventano una lista di elementi ognuno su una linea presetuti da hyphen (-) - Le parentesi graffe sono sostituite dall'indentazione (come in Python)-- esempio JSON => { "name": "The ultimate docker Course", "price": 149, "is_published": true, "tags": ["software", "devops"], "author": { "first_name": "Mosh", "last_name": "Hamedani" } }-- esempio YML => --- name: The ultimate docker Course price: 149 is_published: true tags: - software - devops author: first_name: Mosh last_name: Hamedani
URI vs URL vs URN
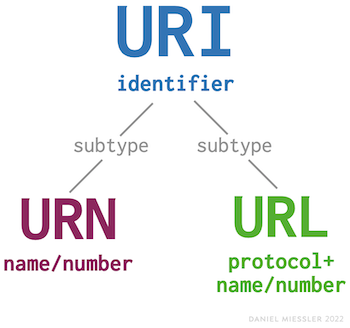
- URI (Universal Resource Identifier) => Identifica univocamente un nome o una posizione.
- URL (Universal Resource Locator) => Identifica univocamente una posizione e come raggiungerla (protocollo).
- URN (Uniform Resource Name) => Identintifica univocamente una risorsa dal nome preceduto da urn.
Content Delivery Network (CDN)
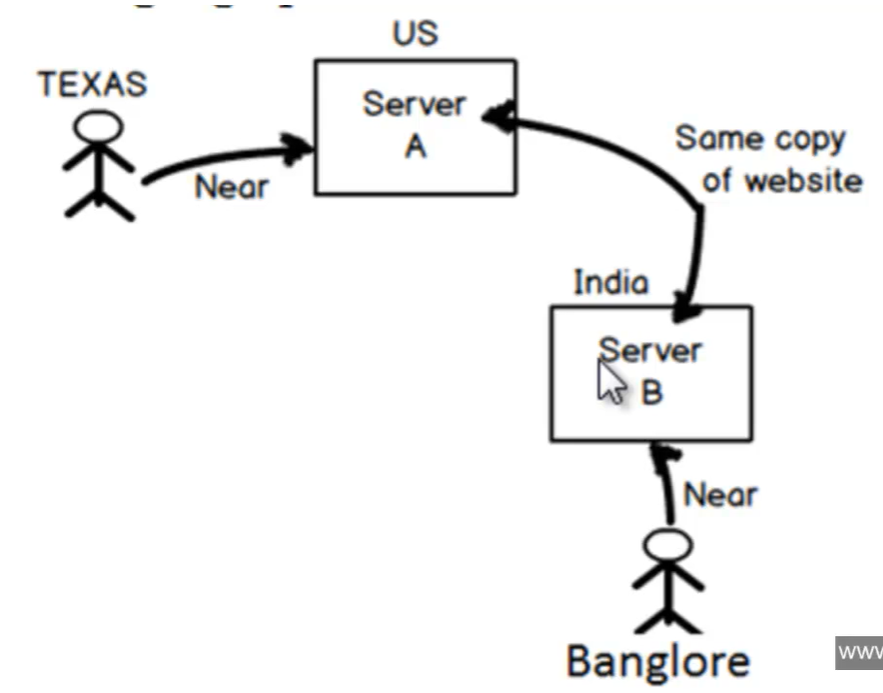
- E’ una tecnica che permette di servire del contenuto web in funzione delle localizzazione dell’utente che lo richieste
- Lo stesso contenuto è deployato in più server (geograficamente distanti) e sarà il server più vicino all’utente che ne richiede dei contenuti a servire tali dati.
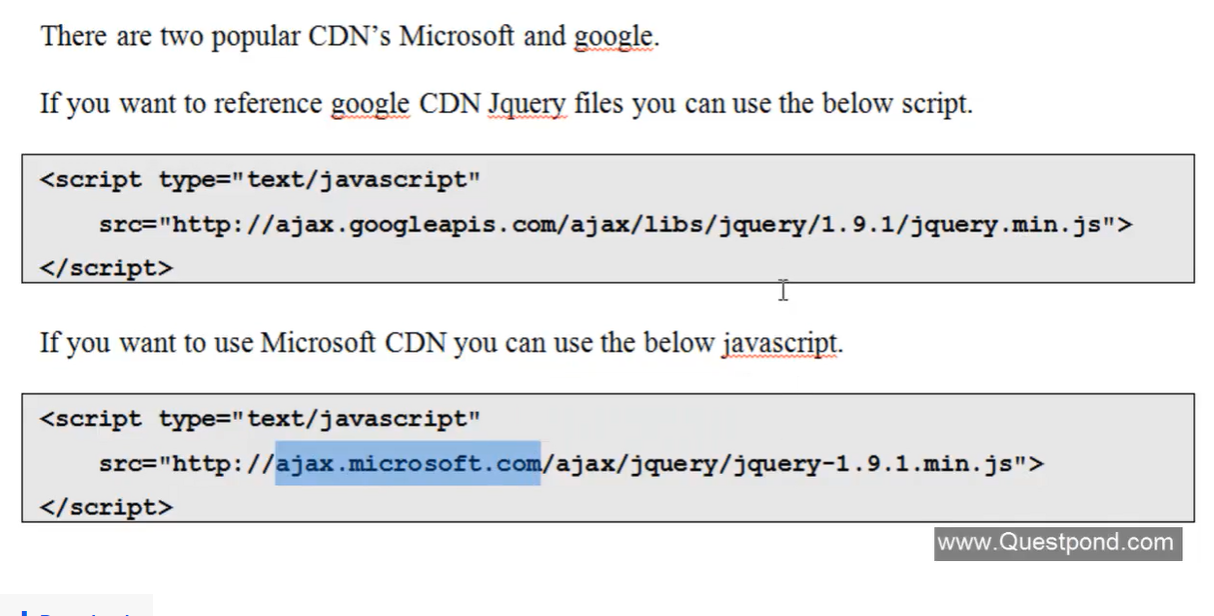
- Questo concetto può essere sfruttato quando si referenziano delle librerie (come JQuery).
- Invece di referenziare il file presente nel proprio server è meglio usare un URL CDN fornito da Microsoft o Google.
Accelerazione Hardware
- L’accelerazione hardware è l’uso di hardware progettato per eseguire funzioni specifiche in modo più efficiente rispetto al software in esecuzione su una CPU generica.
- Si parte dal principio che qualsiasi trasformazione dati possibile via software (eseguito su una CPU generica) può anche essere calcolata via hardware personalizzato o in una combinazione di entrambi.
- Per cercare di migliorare le operazioni d elaborazione generalmente si può investire tempo e denaro per migliorare il software, migliorare l’hardware o entrambi. Ci sono vantaggi e svantaggi in entrambi gli approcci.
- Esiste una scala nella gerarchia di specificità di un hardware:
- Hardware generico (CPU)
- Hardware più specifico (GPU)
- Hardware programmabile (FPGAs)
- Hardware specializzato per un’applicazione (ASICs)
- Intel Hardware Accelerated Execution Manager (HAXM)
-
//windows shell //verifico se HAXM é supportato ed in esecuzione sul computer >sc query intelhaxm
-
Virtualizzazione in Windows
- Windows Features
- Hyper-V
- E’ il software per creare macchine virtuali (Hypervisor) di Microsoft.
- Permette di eseguire versioni complete di un altro sistema operativo sul proprio computer.
-
//disable Hyper-V bcdedit /set hypervisorlaunchtype off //enable Hyper-V bcdedit /set hypervisorlaunchtype auto
- Virtual Machine Platform (VPM)
- E’ una versione meno potente di Hyper-V (Microsoft non chiarisce precisamente le differenze).
- Da attivare se si vuole usare WSL (Windows subsystem for Linux).
- Puo’ essere usato per creare applicazioni MSIX per un App-V o MSI.
- Windows Hypervisor Platform
- E uno stack di API che permettono agli sviluppatori terzi di usare le funzionalità del Windows hypervisor.
- Permette l’esecuzioni di applicazioni virtualizzate (es: App-V) in Windows senza il bisogni di attivare Hyper-V.
- Windows Sandbox
- Permette di eseguire una versione temporanea di Windows nel proprio computer.
- Windows Subsystem For Linux (WSL)
- Permette di eseguire comandi Linux su un computer Windows.
-
wsl --install (kernel linux, wls, hyper-v, virtual machine platform) wsl -l -v //visualizza le distribuzioni Linux installate in WLS [-l = --list, -v= --verbose] wsl -l -o //visualizza le distribuzioni Linux installabili wls --set-default-version 2 //setto la versione di default wls --set-version <distroname> 2 //setto la versione della mia distro wls --s <distroname> //setto la distro di default [-s = --set-default] //un asterisco appare vicino alla distro wsl --unregister <distroname> wsl --update wsl -d <distroname> //avvio la distribuzione [-d = --distribution] wsl --shutdown //stoppo la distribuzione wsl -d <distroname> <istruzione> //é possibile scrivere dei comandi direttamente senza entrare nella shell della distribuzione wsl <istruzione> //eseguo dei comandi nella distrubuzione di default sudo apt-get update //metto a giorno i pacchetti nella distribuzione Linux scelta sudo apt-get upgrade -y //metto a giorno la distribuzione stessa //Utilizzare la distribuzione Linux con interfaccia grafica - Metodo 1 Win-Kex - Metodo 2 Via il Remote Desktop di Windows - Installare il desktop environment XFCE (specifico alla nostra distribuzione) sudo apt-get install kali-desktop-xfce -y //XFCE - desktop environment per Kali oppure sudo apt install xfce4 //XFCE - desktop environment per Ubuntu sudo apt-get install ubuntu-desktop - Installare e lanciare il server RDP sudo apt-get install xrdp -y //xRDP //Emulatore di un server RDP (remote desktop) sudo service xrdp start //lancio il servizio per eseguire il server RDP - Recuperare l'IP per poter accedere alla nostra distribuzione Linux via RDP ip address //recupero indirizzo IP della macchina linux per poter accedervi (eth0)
- Hyper-V
OPC UA (Open platform communications – Unified Architecture)
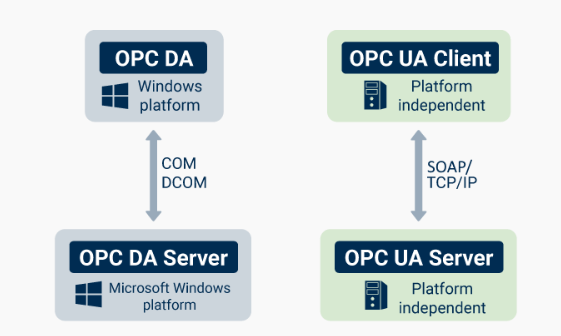
- Sviluppato dalla OPC Fundation.
- Uno dei principali standard di comunicazione per l’ Industry 4.0 e IoT.
- Standardizza l’accesso a macchinari, apparecchiature e sistemi industriali e ne permette lo scambio di dati.
- OPC Classic
- Legato a Windows.
- Limitato utilizzo.
- OPC UA
- E’ l’evoluzione della versione classica dello standard.
- Con la crescita sul mercato di piattaforme alternative a Windows (Cloud, IoT decive, Linux) é stata sviluppata una versione indipendente dalla piattaforma (Windows).
- Passa da COM/DCOM a TCP/IP o in alternativa SOAP.
- OPC Server
- E’ la base del sistema OPC.
- E’ un software che implemente lo standard OPC.
- Fornisce le interfacce di comunicazione al mondo esterno.
- E’ sviluppato e fornito dal produttore del macchinario .
- Puo’ essere embedded nel controller del macchinario o un’applicazione stand-alone.
- Comunicazione del tipo Pub/Sub
- I partecipanti in una comunicazione OPC UA sono divisi tra publisher e subscriber.
- I device (pub) e il software (client OPC) comunicano via un broker senza la necessita di fare affidamento a una relazione 1-a-1 tipica delle comunicazioni client/server.
- OPC Client
- Per poter interagire con il macchinario desiderato é necessario sviluppare un client OPC.
LPR/LPD Protocol
- Line Printer Daemon protocol/Line Printer Remote protocol
- E’ un protocollo di stampa di rete per l’invio di jobs di stampa a una stampante remota.
- E’ supportato dal CUPS (Common Unix Printing System) presente nelle distribuzioni Linux e Mac OS X.
- Server LDP é all’ascolto sulla porta TCP 515.
EDI (Electronic Data Interchange)
- Standard per lo scambio di comunicazioni commerciali che tradizionalmente avvengono via carta/fax/email.
- Ordini di acquisto (PURCHASE ORDER) / Avviso anticipato di consegna (DESADV) / Fatture (INVOICE).
- I documenti passano direttamente dall’applicazione del soggetto che invia (es: sistema logistico) all’applicazione del soggetto che riceve (es: sistema di gestione degli ordini).
- Come EDI lavora
- Fase 1 – Creazione del documento originale che si vuole trasmettere
- Fase 2 – Traduzione di tale documento nel relativo formato standard EDI utilizzando i corretti segmenti e header
- Fase 3 – Trasmissione dei dati
- Diretta (Point-to-point)
- Tramite EDI Network provider