
- Concetti base
- Come migliorare le performance
- Indici
- Execution plan
- Comandi
- Cursor
- Use cases
- Connection String
- SQL Server Integration Services (SSIS)
- Temporary Data (CTE, Temp Table, Temp variable)
- Risorse
Concetti base
- Sql Server engine é composto da:
- Storage engine.
- Query Processor
- Elabora le query ricevute e calcola il piano di esecuzione.
- Transact-SQL :
- La versione SQL di Microsoft.
- Query Processor =>
-
- L’esecuzione di un comando sql è un processo a 4 fasi:
- Parsing phase
- Syntax control (l’engine che esegue un comando sql per prima costa fa un controllo della sintassi).
- Biding phase
- Naming resolution (gli oggetti presenti nel SQL statement in esecuzione esistono?).
- Compile / Optimizing process (produce l’execution plan / plan cache):
- L’optimizer lavora sulla base della stima dei costi (di esecuzione) di una query per elaborarne il ‘piano di esecuzione’.
- Tali costi dipendono da:
- Physical operator cost.
- Stima del # di record in una tabella (cardinality estimate).
- Stima della percentuale di righe da un input per soddisfare un predicato (selectivity).
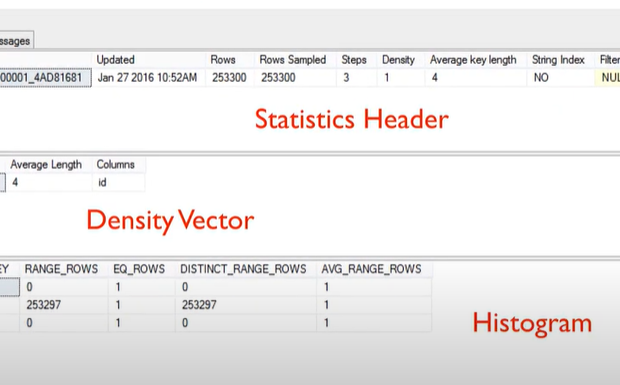
- Data statistics
- Sono creati
- Automaticamente l’optimizer.
- Alla creazione di un indice
- Per ognuna di queste tabelle consulta dei ‘Data statistics’
- Quante righe ha una tabella?
- Esiste una PK nella tabella?
- La tabella è estesa su più di pagine sql
-
SELECT * FROM sys.stats WHERE object_id = object_id('<table_name>') DBCC SHOW_STATISTICS('<table_name>',id); --Histogram --Density information --String statistics
- Sono creati
- Tali costi dipendono da:
- L’optimizer lavora sulla base della stima dei costi (di esecuzione) di una query per elaborarne il ‘piano di esecuzione’.
- Parsing phase
- L’esecuzione di un comando sql è un processo a 4 fasi:
-
-
-
- Query Processor Tree
- La fase di parsing/binding traduce lo statement SQL (o T-SQL) in un albero di operazioni logiche (di alto livello) detto ‘Query Processor Tree’ .
- L’engine optimizer guarda il ‘Query Processor Tree’ e valuta se ci sono altre tabelle interessate dal comando sql.
- Genera dei possibili piani di esecuzione candidati
- Traduzione dell’albero di operazioni logiche in operazioni fisiche.
- L’insieme di tutti i possibile piani di esecuzione é detto ‘Search space‘.
- Estimated Plan (basato sulle statistiche)
- Dopodiché calcola i costi e genera un ‘estimated plan’
- Utilizza gli attuali dati statistici ‘statistics’ per ipotizzare il migliore piano di esecuzione possibile
- Non utilizza gli attuali dati presenti nelle tabelle
- Actual Plan (basato sui dati veri e propri)
- Viene generato anche un ‘actual plan’ (non necessariamente identico all’ ‘estimated plan’)
- Utilizza gli attuali dati presenti nelle tabelle per decidere qual’è il miglior piano di esecuzione possibile
- Live Statistics Plan
- Mostra il piano di esecuzione effettivamente usato salvato ‘In-memory’.
- Query Processor Tree
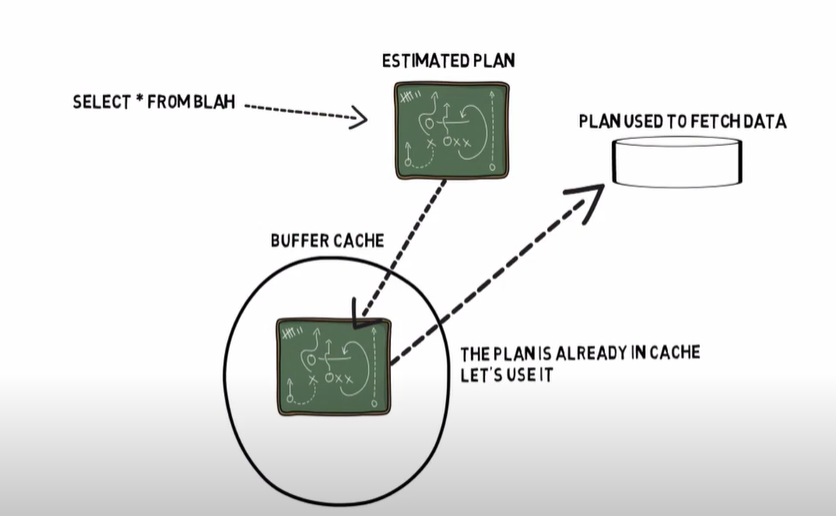
- Executing (usa il plan cache):
- Viene eseguito la query secondo il ‘piano di esecuzione’.
- Plan reuse:
- Il piano di esecuzione eseguito viene memorizzato in una parte di memoria detta plan cache.
- Lazy Writer: recupero il piano di esecuzione dalla cache.
-
- Tale procedura deve mantenere un equilibrio tra il tempo speso in ognuna delle 3 fasi.
- Ricompilazione
- In generale si vuole evitare una ricompilazione del ‘piano di esecuzione’ già presente nella cache.
- Cambiare un indice.
- Eliminare un indice.
- Aggiornare gli ‘statistics’ .
- Chiamare esplicitamente la procedure sp_recompile .
-
- Scan count :
- Indica quante volte l’engine scorre la tabella
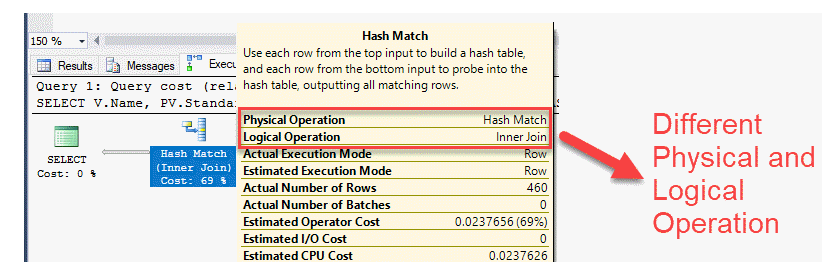
- Logical operator vs Physical operator =>
-
- Logical operator =>
- Gli operatori logici descrivono l’operazione relazionale utilizzata per elaborare un’istruzione.
- Descrivono concettualmente quale operazione deve essere eseguita.
- Physical operator =>
- Gli operatori fisici implementano l’operazione descritta dagli operatori logici.
- Ogni operatore fisico è un oggetto o una routine che esegue un’operazione.
- Gli operatori fisici inizializzano, raccolgono dati e dispongono.
- Logical operator =>
-
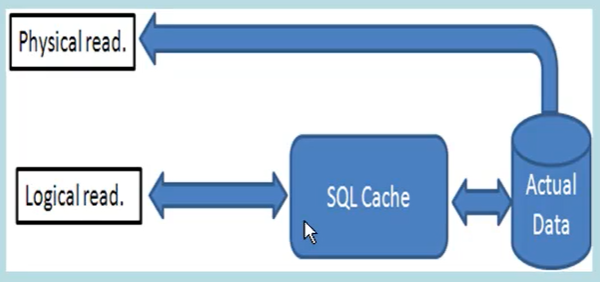
- Physical read vs Logical read :
- Physical read
- Quando i dati sono letti tramite un’operazione I/O direttamente nella base di dati.
- Logical read
- Quando i dati sono letti tramite un’operazione di I/0 dalla cache.
- E’ un dato che conta maggiormente rispetto ai ‘Physical read’ in quanto questi ultimi contano solo la prima volta dopodiché la quzry viene eseguita dalla cache e quindi tramite ‘Logical read’.
- Physical read

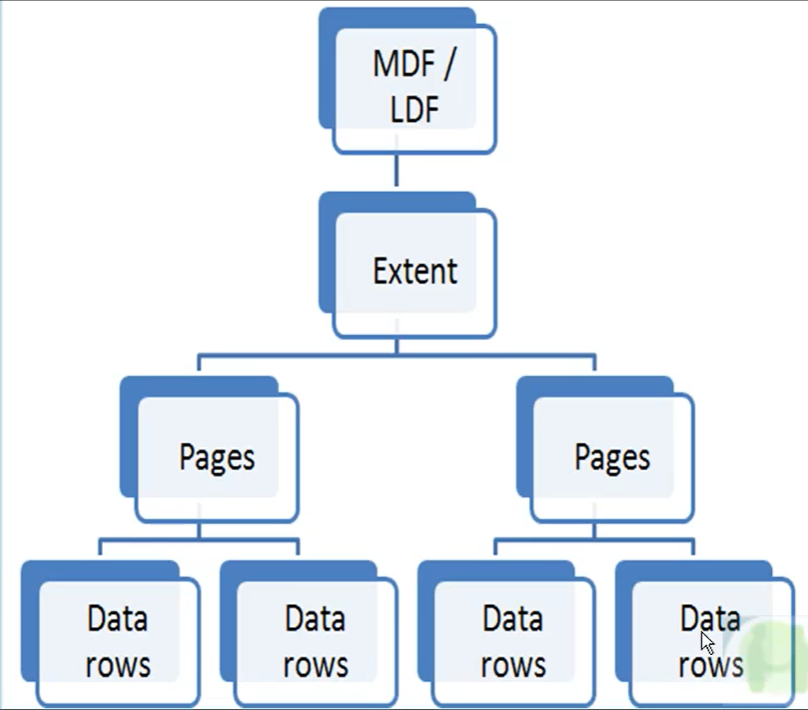
- Struttura fisica dello storage in Sql Server =>
-
- MDF (Main data file)
- E’ il file principale.
- E’ l’insieme dei dati che costituiscono il DB.
- LDF (Log data file)
- E’ un file di supporto.
- Contiene i log alle operazioni (es: CRUD) effettuati sui dati del DB (presenti in MDF).
- Puo’ arrivare a consumare molto spazio di memoria in funzione del numero di modifiche e di transazioni che hanno luogo sul DB.
- Extent :
- Raggruppamenti logici di pages.
- Pages :
- Sono le unità fondamentali dell stoccaggio dei dati (dove i dati sono immagazzinati).
- Dimensione max di 8kb.
- MDF (Main data file)
- Indexed view
- Sono viste persisted e non volatili come le normali viste.
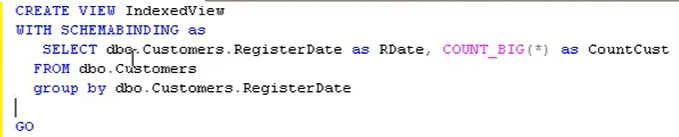
-
- Sono sconsigliate per tabelle che mutano spesso, i costi per tenere aggiornate le viste persisted sarebbero elevati
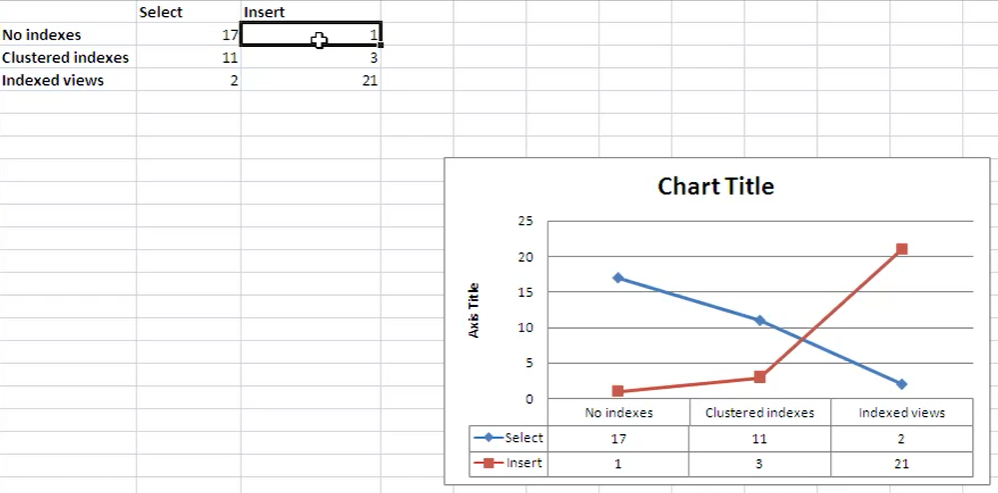
- Come si vede nel grafico qui sotto, con una ‘indexed views’ aumentano drasticamente le operazioni in caso di insert.
- Sono sconsigliate per tabelle che mutano spesso, i costi per tenere aggiornate le viste persisted sarebbero elevati
- OLTP vs OLAP =>
- Quando decido gli indici devo pensare a quale delle 2 filosofie privilegiare.
- OLAP (Online Analytical Processing) :
- Ottimizzato per l’analisi dei dati aggregati/storici.
- Data Warehouse o Data Mining sono esempi di OLAP.
- L’elaborazione è un po’ lenta.
- Viene utilizzato principalmente per la lettura dei dati.
- Posso usare gli indici per velocizzare le query in SELECT.
- Preferire gli indici tipo columnstore.
- Le tabelle nel database OLAP non sono normalizzate (es: i dati posso essere ridondanti).
- OLAP cube
- Ogni cubo include dati categorizzati in diverse dimensioni (es: aree geografiche di vendita, periodo di tempo, clienti).
- OLTP (Online Transaction Processing):
- Ottimizzato per operazioni quotidiane (elaborare transazioni).
- OLTP è un sistema che gestisce un numero molto elevato di transazioni online brevi (ad esempio un ATM).
- Utilizza i tradizionali DBMS.
- L’elaborazione dura millisecondi.
- Gestisce tutte le transazioni di Insert, Update, Delete.
- Non avrò un numero troppo alto di indici.
- Le tabelle nel database OLTP sono normalizzate (es i dati non possono essere ridondanti).

- Interleaved execution (>= Sql Server 2017)
- Permette di gestire la situazione in cui una o più tabelle non hanno un numero di righe predeterminato.
- L’execution plan è capace di valutare l’operatore successivo dopo aver effettivamente eseguito i passi precedenti.
- Ciò permette di adattare meglio il piano di esecuzione alla reale quantità di dati.
- Index Fragmentation =>
- Nella operatività di una tabella con indici è possibile che alcune posizioni di memoria all’interno delle pages in cui sono memorizzati gli indici di frammentino:
-
SELECT * FROM sys.dm_db_index_physical_stats(...) SELECT * FROM sysdm_db_index_usage_stats
-
- Deframmentare un indice =>
- E’ necessaria allora un’operazione di deframmentazione, per ricompattare gli indici nelle pages (8kb)
- In produzione è meglio schedularla
- Nella operatività di una tabella con indici è possibile che alcune posizioni di memoria all’interno delle pages in cui sono memorizzati gli indici di frammentino:
- Page split =>
- Operazioni sulle tabelle portano ad aumentare gli page split dovuto alla gestione degli indici.
- Il problema è quando abbiamo molti indici e molte operazioni di insert/update/delete sulla corrispondente tabella.
- I numero di page split dovrebbe essere tenuto basso.
- Usare Performance Monitor Tool per vedere la quantità di Page split (vedi sotto).
- Parallelismo
- Per query complesse, l’optimizer utilizza più thread alla volta operando in parallelismo cercando di essere più veloce.
- E’ possibile settare un costo (in secondi) utilizzato poi dall’optimizer per decidere se attivare o meno l’uso del parallelismo:
- Server Properties (click dx sul server) -> aprire ‘Server properties’ -> Advanced -> ‘Cost Threshold for Parallelism’
- ******* Cross apply / Outer apply *******
- Consente di passare i valori da una tabella (o vista) a una funzione o sottoquery.
-
//esempio1 // Abbiamo Table1 e Table2. Table1 ha una colonna chiamata rowcount. // Per ogni riga di Table1 dobbiamo selezionare le prime 'rowcount' righe di table2 // ordinate per table2.id //se avessi usato CROSS JOIN avrei ricevuto un errore alla linea //SELECT TOP (t1.row_count) *, in quanto il lato destro della join non conosce t1.row_count //Invece usando CROSS APPLY l query funziona correttamente. SELECT t1.Id, sub.* FROM table1 t1 CROSS APPLY ( SELECT TOP (t1.row_count) * FROM table2 t2 WHERE t2.ProductId = t1.Id ORDER BY id ) sub ORDER BY t1.id, t2.id //esempio2 //ipotizzo di aver creato la funzione "GetSalesByProduct" che ritorna la somma delle vendite //del dato prodotto (p.ProductID) partendo dalla tabella [Product] SELECT p.ProductID, p.Name, x.TotalSales FROM [Product] p CROSS APPLY GetSalesByProduct (p.ProductID) AS x;
- Parameter sniffing :
- Se ho una stored procedure con dei parametri in ingresso
- Alla sua prima esecuzione viene creato e messo in cache un piano di esecuzione basato su tali parametri d’ingresso.
- Alle esecuzioni successive viene utilizzato il piano presente in cache indipendentemente dai parametri in ingresso.
- How to fix
- Create SQL Server Stored Procedures using the WITH RECOMPILE Option
- Use the SQL Server Hint OPTION (RECOMPILE)
- Use the SQL Server Hint OPTION (OPTIMIZE FOR)
- Use Dummy Variables on SQL Server Stored Procedures
- Disable SQL Server Parameter Sniffing at the Instance Level
- Disable Parameter Sniffing for a Specific SQL Server Query
-
//Modo 1 //Usare RECOMPILE //Ad ogni esecuzione avrà un nuovo piano di esecuzione (soluzione non ottimizzata) CREATE PROCEDURE my_procedure @param1 datetime AS SELECT field1 FROM table1 WHERE orderDate = @para1 OPTION (RECOMPILE) GO //Modo 2
Come migliorare le performance
- ‘Unique keys‘ (es: PK) migliorano le performance di un ‘table scan’ (o di qualsiasi altro ‘physical operator’).
- ‘Table scan’ per piccole tabelle vs ‘Seek Scan’ per grandi tabelle.
- Usare ‘Covering Index’ per ridurre ‘RowID lookup’.
- Usare tipi numerici piuttosto che campi di tipo stringa.
- Usare le ‘indexed view‘ per SQL complesse.
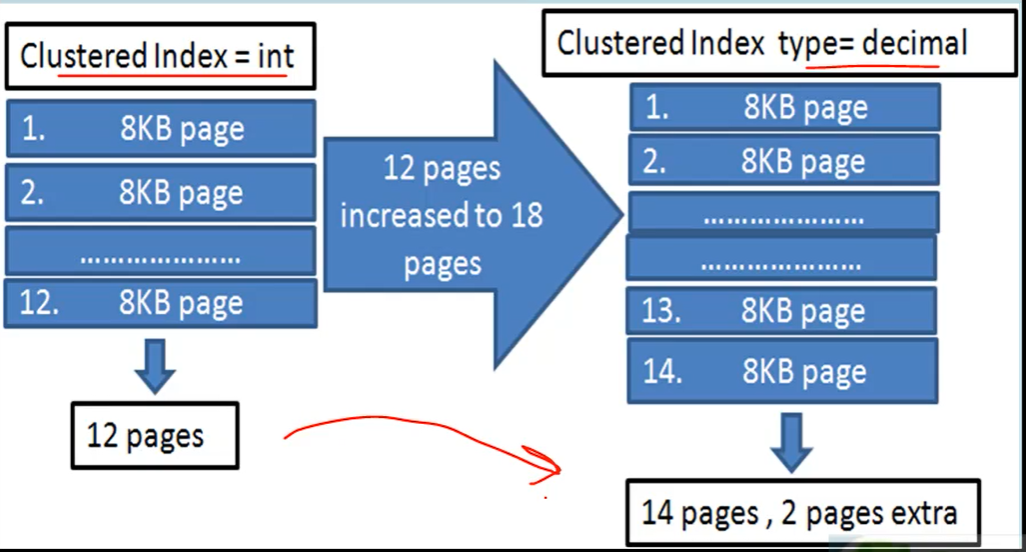
- Cercare di mantenere le dimensioni dell’indice più piccole possibili :
- Aumentando la dimensione di un indice aumentano il numero di pages usate per memorizzarli.
- L’engine del DB deve fare molti salti tra un page e gli altri spendendo molte risorse.
- Solamente avendo un tipo di colonna diverso (es: passando da int a decimal) l’indice aumenta di dimensione e di conseguenza anche il numero di pagine da allocare.
- Missing index Details.. (non presente nei Trivial Plan)
- Click dx sul piano di esecuzione.
- Visualizzo gli eventuali suggerimenti da parte della sql engine rispetto ad eventuali indici mancanti o da migliorare.
- Unused Index =>
- Eliminare indici non usati.
- Tools monitoraggio performance del DB =>
- Perché usare tools =>
- Ricercare le query lente (Wait stats).
- Scovare dead locks.
- Evidenziare grosse operazioni di I/0.
- Performance Monitor Tool (Tool in Windows Os) => E’ un tool di Windows che cattura delle informazioni sulle perfromance di tutti i processi attivi nel sistema operativo
- Click su ‘Add counters’
- Selezionare ‘SQLServerAccess Methods’
- Selezionare ‘Page split/sec’
- Query store
- Wait stats
- Extented events
- E’ meno pesante del Sql Profiler
- Creo nuova sessione =>
- Click Dx e creare una nuova sessione e darle un nome
- Scelgo il template (è possibile scegliere ‘nessun template’)
- Scelgo l’evento da catturare (Es: cerco ‘wait_info’) mettendolo nei ‘Selected events’
- Scelgo i campi da catturare (Es: sql_text, task_time)
- E’ possibile applicare dei filtri sui valori di tali campi da visualizzare (aprire tab ‘Filter’)
- Per rimuove informazioni non volute (relative a operazioni di sistema ad esempio)
- E’ possibile iniziare subito la sessione di cattura dei dati scelti o schedularla
- Perché usare tools =>
-
-
- Start session =>
- Dopo aver creato la sessione sarà possibile vederla aprendo il folder ‘Sessions’ (vedi immagine sopra)
- Watch live data =>
- Dopo aver avviato la sessione di cattura posso vederne i risultati
- Se non vedo tutti i campi desiderati => Click Dx ‘Choose columns’
- Start session =>
-
-
- Sql Server Profiler (vedi sotto)
- Aggiornare gli indici dopo un certo periodo =>
- Misurare il carico di lavoro (workload) =>
- Sql Server profiler :
- E’ un listener che ascolta le query che si stanno eseguendo nel DB.
- In un ambiente di produzione bisogna stare attenti perchè lanciare il ‘Sql Sever Profiler’ potrebbe avere effetti negativi sulle performance.
- Filtrare il profiling => E’ possibile filtrare per poter vedere solo le query che competono alla tabella che sto valutando
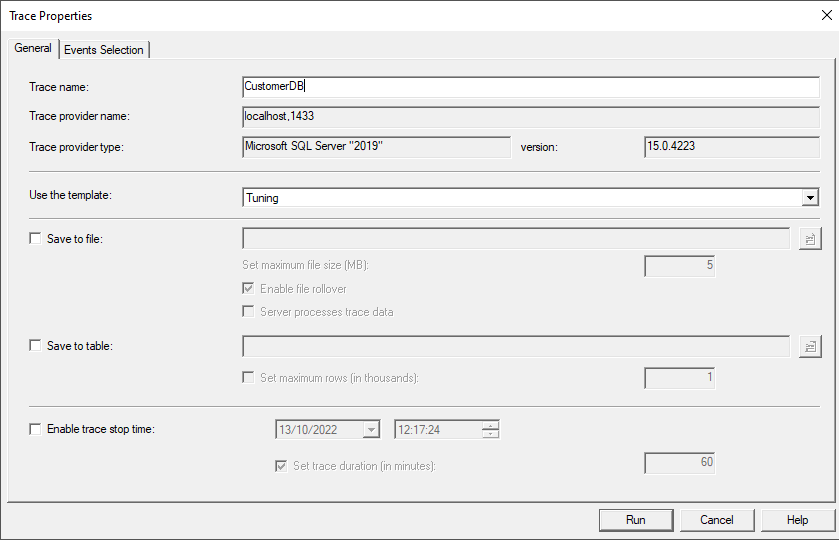
- Aprire il ‘Tools => Sql server profiler’
- Impostate il Template
- Nel ‘tab general’ selezionare nella dropbox ‘Use the template’ il template = tuning
- Sql Server profiler :
- Misurare il carico di lavoro (workload) =>
-
-
-
-
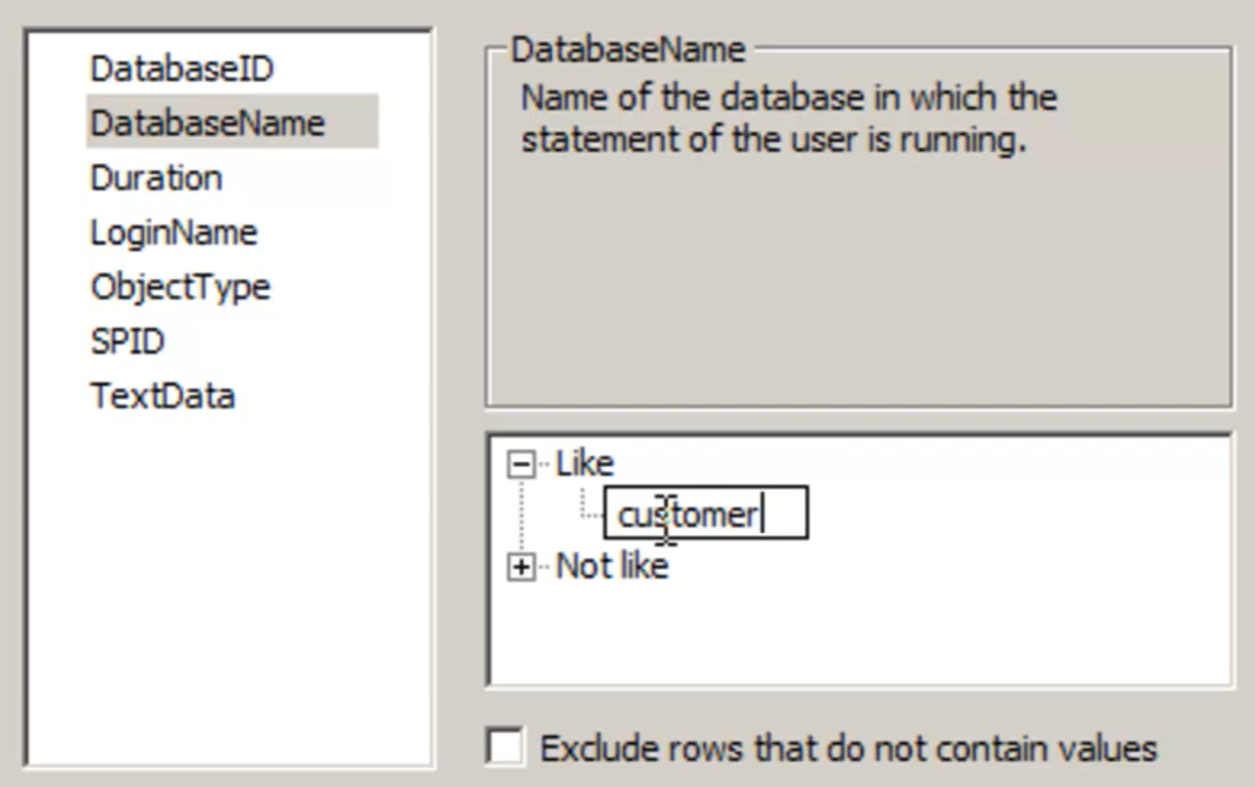
- Aggiungere il filtro
- Nel ‘tab Events selections’ cliccare su ‘Column filters’
- Aggiungere il filtro desiderato (es: DatabseName = ‘customer’)
- Aggiungere il filtro
-
-
-
-
-
-
-
- Salvare il file di trace
- Stoppare il profiling
- File => Save as => Trace File (.trc)
- Indicare il path dove salvare il file
- Salvare il file di trace
-
-
- Analizzare il workload =>
- Tuning Advisor :
- Analizza se gli indici attuali sono ottimizzati per tale carico
- Analizzare il file di workload
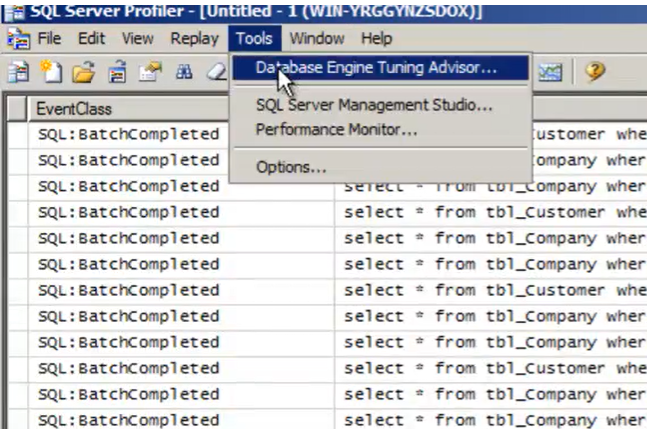
- Dal Sql server Manager aprire ‘Tools => Sql server profiler’
- Dal Sql Server profiler aprire ‘Tools => ‘Database Engine Tuning Advisor’
- Tuning Advisor :
-
-
-
-
-
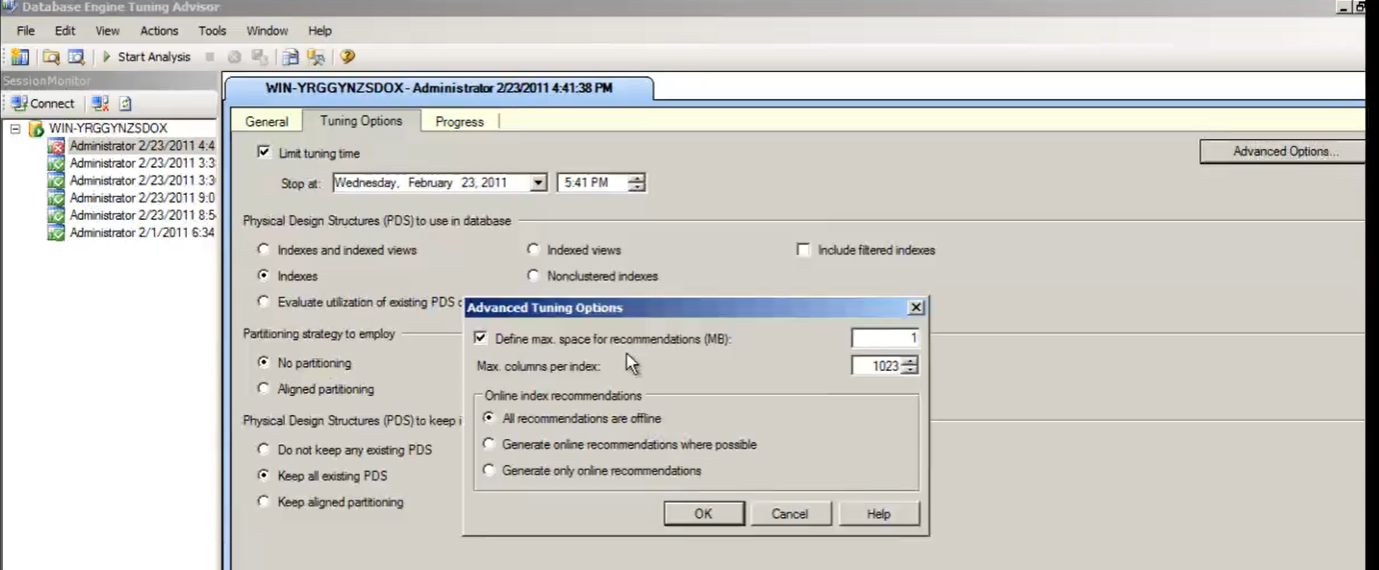
- Caricare il file di workload
- Indicare quale tabella analizzare
- Cliccare su ‘Start Analysis’
- ‘Tab tuning options’ => A volte è necessario aggiungere dei MB (temporary space) dedicati all’analisi
-
-
-
-
-
-
-
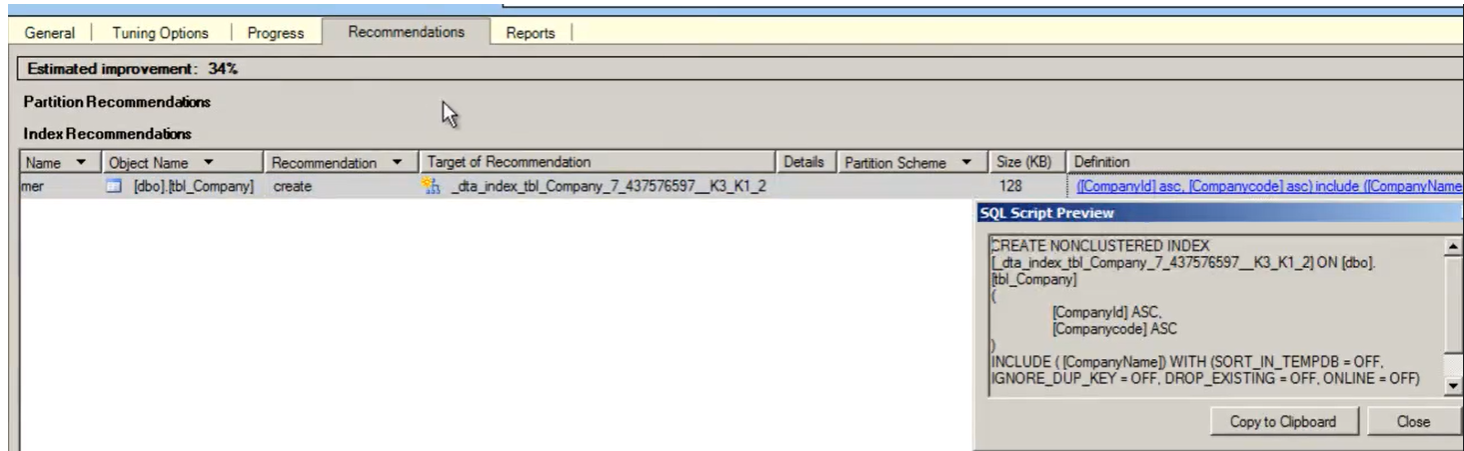
- ‘Tab raccomandations’ => Leggere la raccomandazione che dà
-
-
-
- Tecniche per migliorare le prestazioni =>
- Selezionare solo le colonne richieste:
-
//Non usare mai SELECT * FROM ..
-
- Filtrare il set di dati trattato (WHERE clause)
- Isolare solo i dati che interessano.
- Evitare di processare dati che non servono.
- Usare Temp Table o CTE
- Migliorano la struttura di una stored procedure / qurey
- Aiutano il debug
- DRY
- Evitare di ripetere più volte una stessa operazione (join o modifica su un campo)
- Usare Indici
- Alleggerire il costo delle aggregazioni:
- Query con sub-select:
- verificando con il piano di esecuzione, cercare di aggregare il più tardi possibile.
- Query con sub-select:
- Nest repeated data
- Invece di andare a leggere i dati denormalizzati (es: dettaglio degli ordini), aggregarli in un campo aggiuntivo nella tabella padre (es: ordini).
- Disattivare il contatore di righe interessate da un SQL statement:
-
SET NOCOUNT ON
-
- Usare il nome dello schema prima di oggetti o tabelle
-
SELECT EmpID, Name FROM dbo.Employees
-
- Evitare se possibile di usare dynamic query.
- Usare EXISTS invece di count
-
//No SELECT count(1) FROM Employees //Yes IF(EXISTS (SELECT 1 FROM Employees))
-
- Usare TRANSICITON solo quando strettamente necessario.
- Evitare di applicare delle trasformazioni ai campi utilizzati nelle WHERE soprattutto se sono indicizzati (index seek non viene applicato):
-
//ipotizzo di avere un indice sul campo orderData o countryCode //la prima query é da evitare perché si inficia l'efficacia dell'indice SELECT * FROM <table> WHERE CONVERT(orderData) = '20100101' //usa index scan SELECT * FROM <table> WHERE countryCode like '%IT%' //usa index scan SELECT * FROM <table> WHERE orderData = '20100101' //usa come atteso index seek SELECT * FROM <table> WHERE countryCode = 'IT' //usa come atteso index seek
-
- Indici multi-colonna (seek not happening)
- L’engine segue la regola da sinistra a destra.
- Se ad esempio voglio usare nella WHERE il secondo (oppure il terzo) campo di indice multi-colonna a 3 campi, allora devo inserire nella WHERE anche il primo (oppure il primo e secondo) affinché l’engine usi come atteso l’ ‘index seek’ e non l’index scan’.
-
//ipotizzo di avere un indici multi-colonna IX_person_LastName_FirstName_MiddleName SELECT * FROM Person WHERE FirstName = 'Ken' //usa index scan SELECT * FROM Person WHERE FirstName = 'Ken' AND LastName = 'Jefferson' //usa come atteso index seek
- Evitare la conversione implicita :
-
SELECT * FROM <table> WHERE LastName = N'Jefferson'
-
- Nelle query dinamiche usare i parametri esplicitamente (evitare di cablare i parametri direttamente nello statement)
- Si evitare sql plan cache
-
DECLARE @ID INT = 1 //cablando il parametro direttamente nella query creo in realtà una query diversa //ad ogni cambio di parametro obbligando l'engine a creare tanti piani di esecuzione e //usare molto la cache SET @SQLString = N'SELECT * FROM <table> WHERE ManagerID = ' + @ID EXECUTE sp_execytesql @SQLString //invece definendo esplicitamente il parametro per la nostra query facciamo in modo che l'engine //la riconosca come unica, eseguendo un solo piano di esecuzione indipendentemente dal //valore passato come parametro. SET @Param1Definition = N'@ManagerID int; SET @SQLString = N'SELECT * FROM <table> WHERE ManagerID = @ManagerID ' EXECUTE sp_execytesql @SQLString, @Param1Definition, @ManagerID = @Id
- Selezionare solo le colonne richieste:
- General Engine Improvements :
- DBCC.
- In-memory worker pool.
- Increase log-writers.
- TempDb configuration.
- Spatial improvements.
Indici
- Sono creati per aumentare la velocità per il recupero di dati da tabelle e viste.
- Un indice contiene 1 o più colonne.
- È necessario bilanciare tra le velocità di recupero dei dati e l’aggiornamento dei dati (nel b-tree) quando si cerca di creare l’indice adatto.
- Tipi di indci
- Unique
- Index (normal)
- Columnstore =>
- Un indice che cerca di raggruppare tutti i dati di una colonna nel minor numero di page.
- Columnstore vs RowStore :
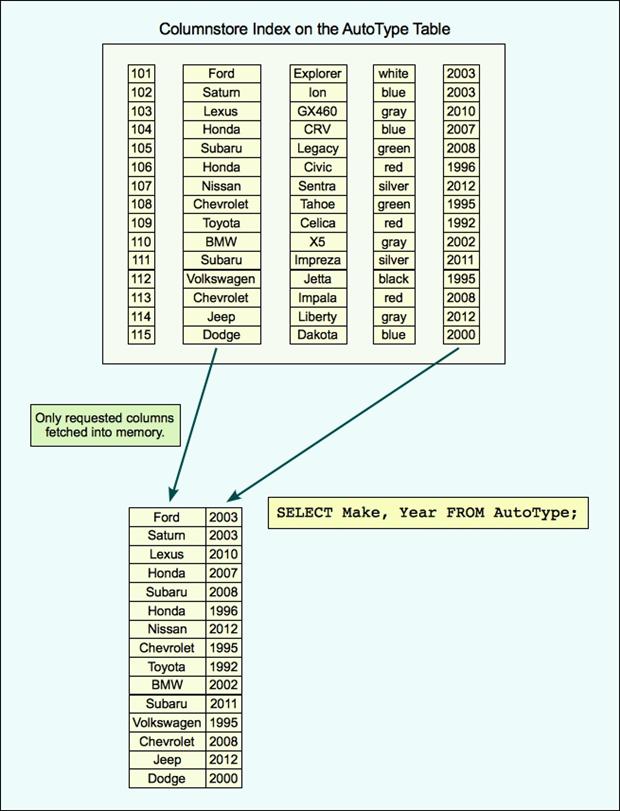
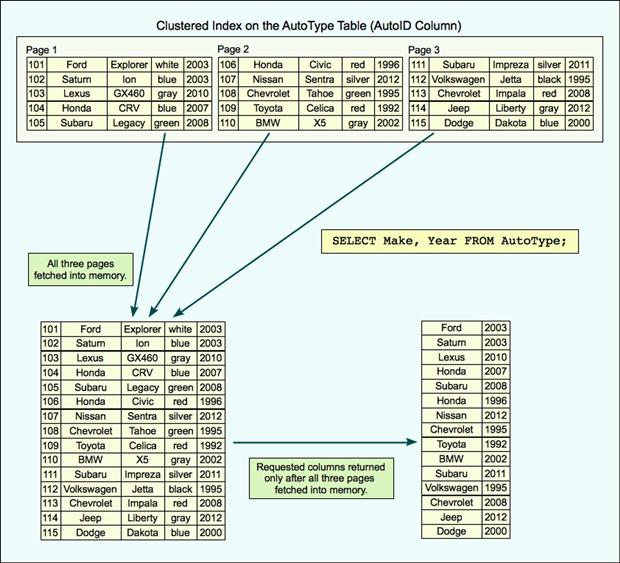
- Hanno un limite di 900 byte
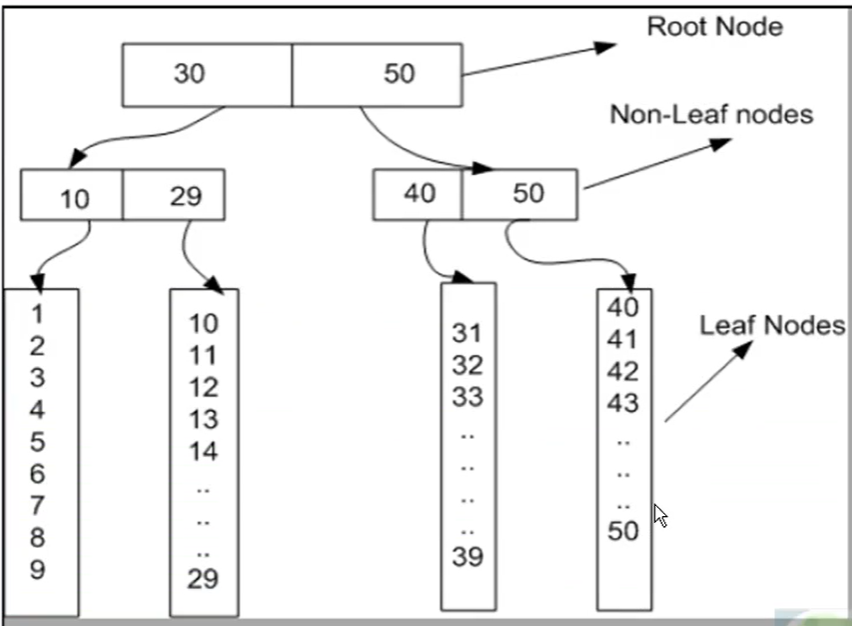
- B-Tree structure
- Quando viene creato un indice allora viene creata una nuova struttura detta’ B-tree’ dove vengono memorizzate le corrispondenze tra gli indici e i dati della tabella.
- Permette di mantenere l’ordine dei dati, permetterne la ricerca, l’accesso sequenziale, l’inserzione e l’eliminazione in un tempo logaritmico (T(n) = O(log n)).
- E’ una struttura dati autobilanciata.
- I record della tabella vengono organizzati in
- Root node
- Un nodo radice è una struttura dati che punta a un range di nodi ‘ non-leaf’.
- Non-leaf node
- Un nodo ‘non-leaf’ è una struttura dati che punta a un range nodi ‘foglia’.
- Leaf node
- Un ‘nodo foglia’ contiene i dati veri e propri della tabella a cui l’indice appartiene.
- Root node
- Quando viene creato un indice allora viene creata una nuova struttura detta’ B-tree’ dove vengono memorizzate le corrispondenze tra gli indici e i dati della tabella.
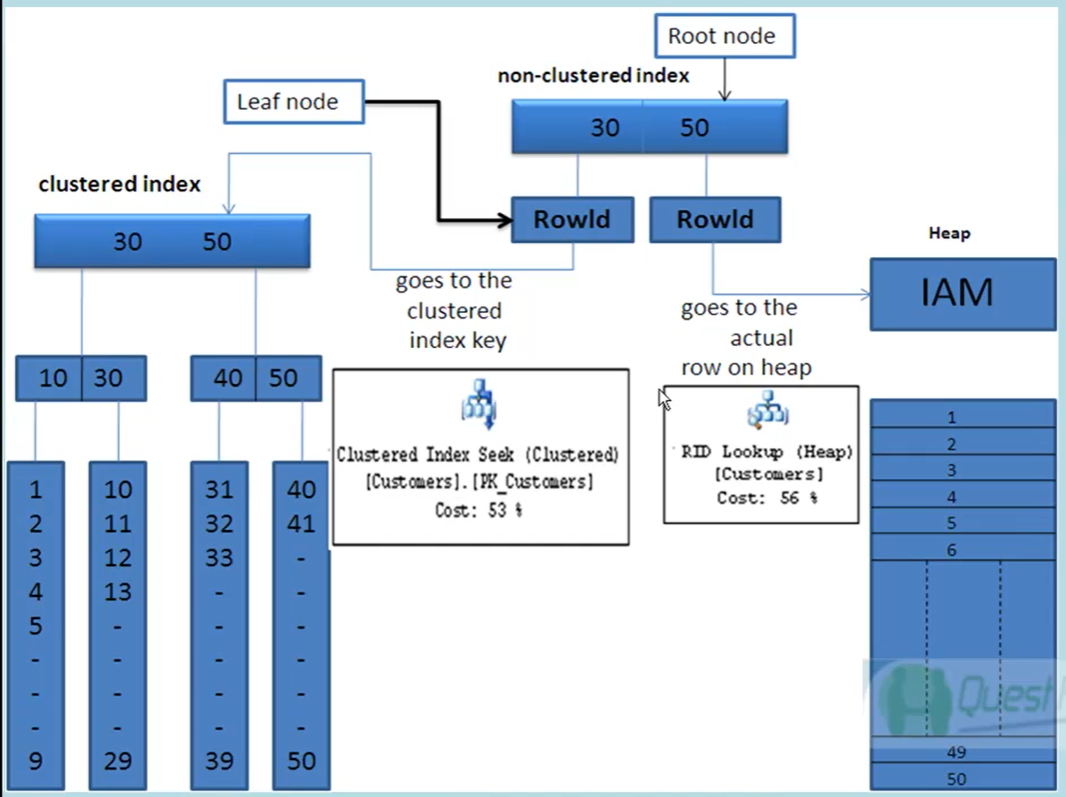
- Indici Clustered vs Non clustered =>
- In una tabella può esserci un solo indice clustered.
- Un indice clustered (solitamente la PK) permette di memorizzare fisicamente i dati presenti nella tabella secondo il campo/campi dell’indice.
- Clustered Index
- Nodi ‘non-leaf’ => Index Page.
- Nodo foglia => Puntatore ai dati fisici della tabella.
- L’indice cluster controlla l’ordinamento delle pagine di dati memorizzate nell’hard disk, comprese tutte le colonne nella tabella (non solo le colonne facenti parte dell’indice).
- Non-clustered Index =>
- Nodi ‘non-leaf’ => Index Page + Tabella di lookup con il campo indicizzato + indice clustered ( + rowid, se non ho un indice clustered).
- Nodo foglia => RowID
- Nel caso di tabella senza incide clustered il RowID punta all’heap stesso e viene ricercato scorrendo l’heap riga per riga.
- Nel caso di tabella con indice clustered il RowID contiene la chiave dell’indice clustered che serve per recuperare direttamente nella tabella la riga indicizzata.
- Tabella heap :
- Tabella senza nessun indice clustered .
- I dati sono fisicamente presenti nella tabella senza un ordine preciso. E’ necessario usare ORDER BY.
- Seek vs Scan :
- Seek
- Recupera direttamente le righe selezionate.
- Eseguito con WHERE.
- Quindi non necessita di scorre righe non richieste.
- < CPU;
- < I/0;
- Scan
- Necessita di scorrere tutte le righe della tabella (richieste o meno) o di un indice
- Eseguito con SELECT.
- E’ il meccanismo meno efficiente per recuperare dei dati.
- > CPU.
- > I/0.
- Seek
Execution Plan

- Index e table access =>
- Table Scan
- Se una tabella non ha indici (né clustered, né non clustered) allora è necessario per ogni query leggere direttamente i dati nella tabella stessa.
- Attenzione: se la tabella ha poche linee, anche se ho degli indici, il motore di Sql Server preferisce usare TABLE SCAN perchè più efficiente di una SCAN su un indice.
- Table Scan
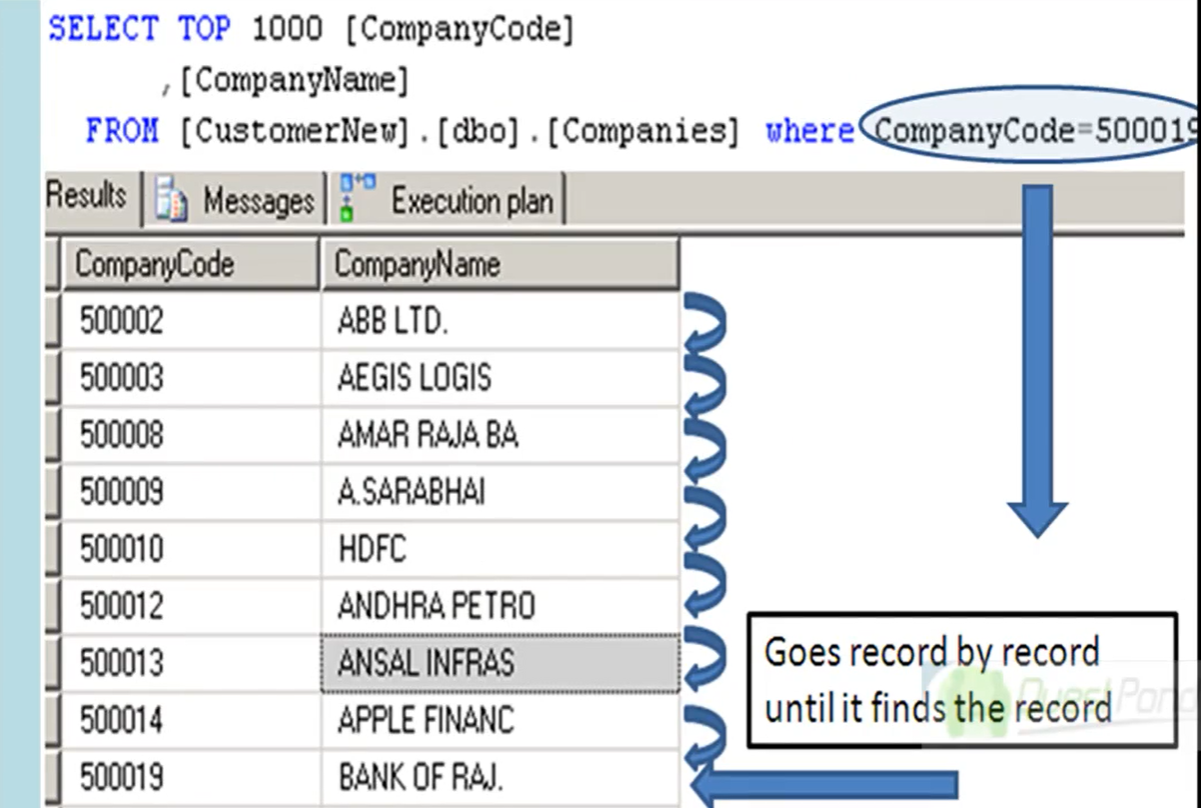
-
- Full Table Scan
- E’ un Table Scan dove si scorre l’intera tabella.
- Index Scan
- Se una tabella ha una colonna con un indice non-clustered e abbiamo bisogno di recuperare tutte le righe di quella colonna.
- Clustered Index Scan
- Se una tabella ha un indice clustered e la query é scritta per recuperare i dati in base a tale indice.
- Index Seek (o Seek scan)
- Necessita aver creato almeno un ‘Index’;
- Il search engine fa un uso efficace dell’indice e lo utilizza per trovare le righe di cui ha bisogno senza scorrerlo tutto;
- E’ utilizzato se ho delle clausole where su un indice non clustered.
- Se ho un WHERE
- Clustered Index Seek
- Come Index Seek ma su un indice clustered.
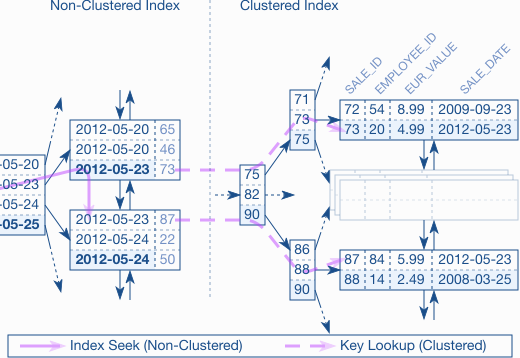
- Index Scan with Lookup =>
- Cosa é :
- E’ un operatore fisico che interviene dopo aver scorso il b-tree e aver raggiunto il nodo ‘leaf’ e permette di recuperare i dati della riga.
- Normalmente si effettua un Index Seek legato ad un indice non-clustered.
- L’intero indice è esaminato cercando di trovare ciò di cui ha bisogno.
- Key lookup (tabella con indice clustered)
- Una volta raggiunto il nodo ‘leaf’ si recupera la particolare riga tramite l’indice clustetered associato alla tabella
- Cosa é :
- Full Table Scan
-
-
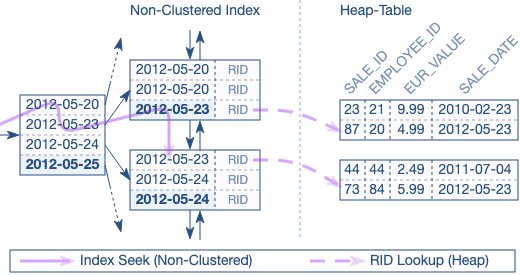
- RowID lookup o bookmark lookup (tabella senza indice clustered) :
- Una volta raggiunto il nodo ‘leaf’ si recupera la particolare riga tramite il RowID dalla tabella heap.
- Questo operatore si presenta spesso in caso di INNER JOIN, LEFT JOIN, RIGHT JOIN
- RowID lookup o bookmark lookup (tabella senza indice clustered) :
-
-
-
- Attenzione: E’ indizio di performance degradate.
- Può essere eliminato usando un covering index.
- Covering index :
- Evitano di fare un lookup (semplicemente un ‘index seek’) .
- Contengono tutte le colonne necessarie ad una specifica query e più query.
- Composite keys =>
- Si ottiene aggiungere all’indice non-clustered che crea il lookup il campo della tabella che è clusterizzato.
- E’ meglio non esagerare con questa tecnica perché può aumentare sensibilmente le dimensione dell’indice.
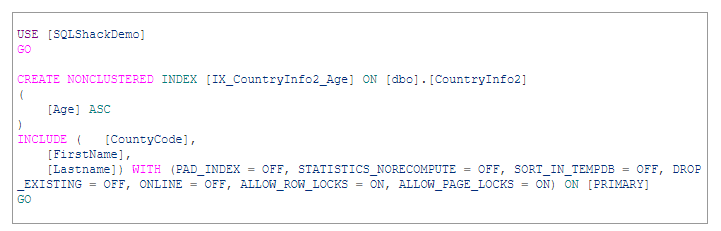
- Include keyword
- E’ possibile creare il non-clustered index includendo delle colonne (vedi sintassi in basso).
- Queste faranno parte solo del nodo ‘leaf’ (e non di tutto il b-tree come le colonne dell’indice stesso).
- Per motivi di spazio/performance non è possibile fare l’include di colonne del tipo
- Text, Ntext, Image
- Covering index :
-

- Join operations =>
- Nested Loop :
- Un loop dentro un altro loop.
- Per ogni riga di una prima tabella (outer table, presente in alto nel grafico dell’execution plan)
- Scorro tutte le righe della seconda tabella (inner table, presente in basso).
- Va bene se entrambe le tabelle hanno poche righe.
- Hash join :
- Tabelle che cambiano spesso di dati (transactional).
- Applico ad ogni riga della tabella outer una funzione di hash. Faccio lo stesso per la tabella inner. Poi comparo questi valori.
- Può essere usata solo se la join contiene un =
- E’ probabile se non ho creato indici.
- Merge join (le tabelle devono essere ordinate):
- Tabelle che cambiano spesso di dati (transactional)
- Per ogni riga di una tabella outer (ordinata) scorro le righe di una tabella inner (ordinata) finché non trovo il valore ricercato o uno superiore e passo alla riga successiva.
- E’ probabile per tabelle con indici (ch danno un ordine alle tabelle stesse)
- Nested Loop :
- Cose é :
- E’ generato dal query optimizer.
- Ci dice come la query viene eseguita del motore del DB (Db engine).
- 3 tipi
- Estimated execution plan.
- Actual execution plan.
- Cached execution plan.
- Solo per SELECT statement.
- Leggerlo da DX a SX.
- Linee guida =>

-
- Performance tuning advisor => attenzione perché può influire sulle performance in un ambiente di produzione.
- I/O Cost 0% => Significa che l’operatore lavora con dati in-memory.
- Table scan => Accettabile per tabelle con pochi dati.
- Index seek => Presenti per delle WHERE.
- Index scan => Buoni su delle tabelle che cambiano spesso i dati.
- Nested Loop => Entrambe le tabelle devono avere pochi records
- Merge Join => Per tabelle transazionali con indici sui campi che sto interrogando (entrambe le tabelle)
- Hast Join => Per tabelle transazionali senza indici sui campi che sto interrogando (almeno una delle 2 non ha indici)
- Adaptative join (>= Sql server 2017) =>
- E’ l’engine che decide se fare un Nested Loop (le tabelle hanno poche righe) o un Merge Join / Hash join
- Actual number of rows = Esistated rows => Ottimo sintomo
- Operatore con il più alto costo => Iniziare da tale operatore per migliorare la query
- (OLAP) Extimated excution mode = ‘Batch’ (Column Store Index) => Buono per query con SELECT
- Actual rebinds/rewinds => Devono avere valori bassi
- Lanciando la query
-
SET STATISTICS IO ON SET STATISTICS TIME ON
- Physical reads => Preferibile avere = 0
- Logical reads => Cercare di rendere il valore più basso possibile.
- Scan count => Preferebile 1.
- Memory Grant => Abilitare l’opzione Memory Grant (>= Sql Server 2017)
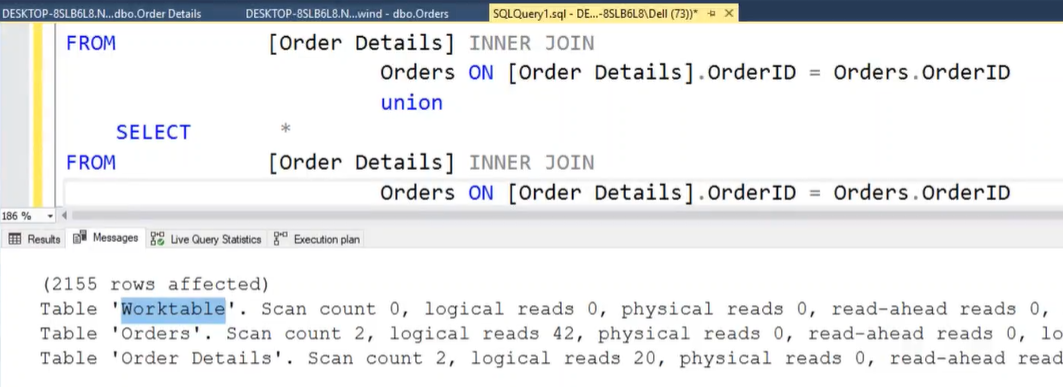
- Evitare ‘worktable’ e ‘workfile’ :
- Se viene visualizzata una linea con ‘worktable’ significa che l’engine ha creato una tabella temporanea per svolgere la nostra query (es: Union)
-
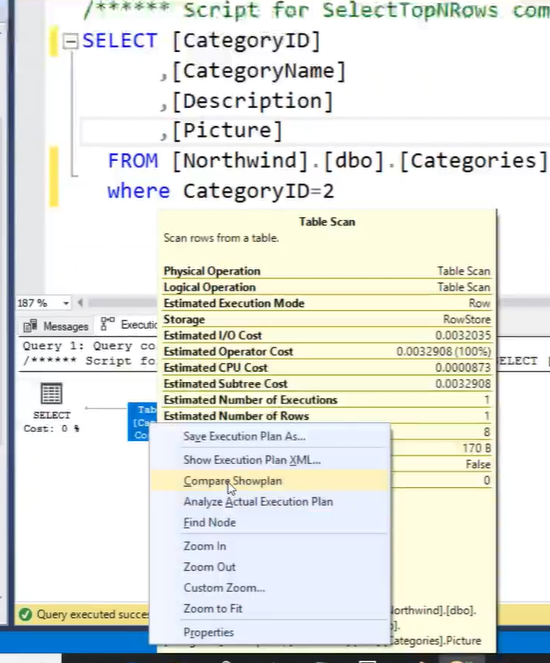
- Come confrontare 2 piani :
- Lanciare il primo execution plan e salvarlo
- Lanciare il secondo execution plan e fare click dx
- Cliccare su ‘Compare Showplan’ e selezionare il file dell’execution plan salvato
- ********** Expensive operators ********* :
- Spooling (Duplicate aggregation).
- Lazy Spool é da evitare.
- Nel caso il lazy spool sia dovuto alla ricorsione (e non alla doppia aggregazione) non é possibile da evitare.
- Eager Spool é accettabile.
- Hash Match (Unsorted date).
- Spesso cӎ un indice che manca.
- Viene usata una funzione su una data colonna
- Se aggiungo un indice allora l’engine usa ‘stream operator’ perché il campo risulta ordinato.
- Key lookup (Missing data).
- Controllare se bisogna creare un ‘covering index”, cioé aggiungere tramite <include> delle colonne agli indici già usati dalla query per evitare appunto di fare il lookup.
- Spooling (Duplicate aggregation).
- Grafico
- Table Spool (Eager spool)
- Significa che si sta usando TempDb (meglio cambiare la query e cerca di usare Windows Spool)
- Windows Spool
- Non chiarisce se stiamo usando TempDb o in-memory ma possiamo verificarlo attivando le statistiche IO e controllare quanti logical reads abbiamo (devono essere il minimo possibile, significa allora che il nostro sql statement sta lavorando ‘in-memory’)
- Row count Spool (Lazy Spool)
- Lazy Spool avviene quando abbiamo una doppia operazione di aggregazione (es: MAX su una GROUP BY)
- E’ da evitare come la peste!
- Table Spool (Eager spool)
Comandi
//COMANDI SQL
//leggere il valore attuale della primary key
DBCC CHECKIDENT ('Makes');
//risettare la primary key di una tabella
DBCC CHECKIDENT ('Makes', RESEED, 0);
DBCC ind('<my-db>', <my-table>, -1); //visualizzo quali e quante sono le pages interessate dalla <my-table>
DBCC traceon(3604) //aggiungo dei dettagli
DBCC page('<my-db>', <iamfid>, <iampid>, 3); //visualizzo le parti che voglio di una certa page
DBCC freeproccache
DBCC dropcleanbuffers //clear execution plan
//restituisce tutti gli indici associati a una tabella
sp_helpindex <nome_tabella>
//Forzare uso indice
select * from <table-name> with (Index(<index-name>))
//Visualizzo le statistiche delle operazioni di IO (logical read, physical read..)
set statistic io on
//visualizzo l'execution plan in formato testo
set showplan_text on/off
//visualizzo l'execution plan in formato xml
set showplan_xml on/off
//numero di piani presenti nella cache
select count(*) from sys.dm_exec_cached_plans
//numero di MB utilizzati dai piani presenti nella cache
select sum(size_in_bytes)/1024 from sys.dm_exec_cached_plans
//COMANDI SHELL
>C:\Users\<myuser>\sqllocaldb -i //visualizza le istanze del SQL Server Express LocalDB già presenti
//Type sql statement then type go //es: use mydb select * from table1
>sqlcmd [-U <user-name>] -S <server-name> //es: >sqlcmd -S 127.0.0.1 -U sa -P <my_pass>
//Display Options of Execution Plans
SET STATISTICS TIME is ON (row affected, elapsed time)
SET STATISTICS IO is ON (Scan counts, Logical reads , Physical reads, Read ahead)
SET STATISTICS PROFILE is ON
SET STATISTICS XML is ON
GO
...<my query>........
SET STATISTICS TIME is OFF
GO
//PATINDEX
SELECT PATINDEX('%BOB%', 'where did bob go?') --11
//CASE
select <select list>
case <value to compare>
when <value to match>
then <result1>
else <result2>
end -
SELECT <field1> CASE WHEN 'Italia' THEN 'IT' ELSE 'EE' END
FROM <table>
//TOP WITH TIES
//ritorna le prime 5 righe della tabella più eventuali righe duplicate (se ci sono tra le prime 5)
SELECT TOP 5 WITH TIES * FROM <table>
SELECT TOP (1) PERCENT * FROM <table>
//OFFSET - FETCH
SELECT *
FROM Characters
ORDER BY name
OFFSET 10 rows -- skip 10 rows
FETCH NEXT 5 ROWS ONLY -- visualizza solo 5 righe
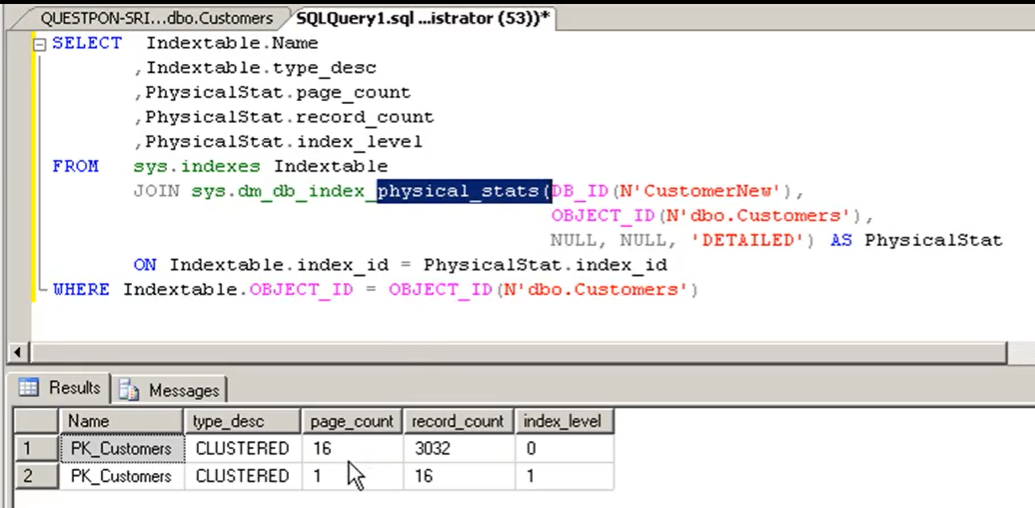
- Dimensione di un indice
Cursor
- Utilizzato quando si vogliono effettuare operazioni su una riga per volta e non su tutto il set di risultati.
- Quando viene dichiarato un CURSOR si ottiene una copia dei dati relativi allo STATEMENT presente nella dichiarazione nel TempDB
- Quindi le operazioni effettuate su un CURSOR sono effettuate nel TempDb.
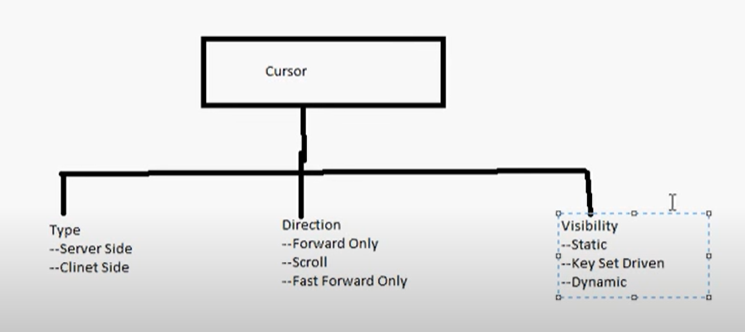
- Tipo di cursore

-
- Static (report, history data)
- Utilizzati solo per operazioni READ ONLY.
- Non si possono fare operazioni di modifica dei dati tramite questo tipo di cursore.
- Utilizzano molta spazio nel TempDb.
- Non si ha la visibilità su eventuali modifiche apportate allo stesso set di dati da un altro utente del DB.
-
DECLARE <cursor_name> CURSOR FORWARD_ONLY STATIC //just NEXT DECLARE <cursor_name> CURSOR SCROLL STATIC // NEXT, LAST, PRIOR..
- Dynamic
-
- Ogni operazione effettuata nel CURSOR é realizzata direttamente nel set di dati originale (nel DB).
- NON utilizza TempDb.
- Sono più veloci
-
DECLARE <cursor_name> CURSOR DYNAMIC ... UPDATE <table> SET <field1> = <value1> WHERE CURRENT OF <cursor_name> ...
-
- Ket set driven
- Solo l’ID della riga viene copiato nel TempDb (e non tutta la riga come nel caso Static)
- Le modifiche (UPDATE/DELETE) sulle righe presenti nel cursore fatte da altri utenti sono visibili nel cursore.
- Le nuove righe aggiunte (INSERT) da altri utenti NON sono visibili nel cursore.
-
DECLARE <cursor_name> CURSOR SCROLL KEYSET ... UPDATE <table> SET <field1> = <value1> WHERE CURRENT OF <cursor_name> ...
- Static (report, history data)
-
//CURSOR SYNTAX -- un cursor é una sorta di scatola dove metto il mio result set -- e in cui posso scorrerlo (solo in avanti) e farci le operazioni necessarie -- é necessario fare OPEN e leggere i dati riga per riga -- il cursore é memorizzato nel tempDb DECLARE CURSOR (declare variables for each result set column) OPEN (execute the statement, populate the cursor) FETCH INTO (single row only) CLOSE free result set and locks DEALLOCATE all resources removed --CURSOR example DECLARE bank_cursor CURSOR FOR SELECT * FROM <table> OPEN bank_cursor FETCH NEXT FROM bank_cursor -- vado alla nuova riga del cursore --FETCH LAST FROM bank_cursor -- vado all'ultima riga --FETCH PRIOR FROM bank_cursor -- vado alla precedente riga --FETCH ABSOLUTE 2 FROM bank_cursor -- vado alla riga numero 2 del cursore --FETCH RELATIVE 3 FROM bank_cursor -- vado 3 righe dopo alla riga corrente WHILE @@FETCH_STATUS=0 FETCH NEXT FROM bank_cursor CLOSE bank_cursor DEALLOCATE bank_cursor
Use cases
- Visualizzare il prezzo del giorno precedente
-
-- esempio 1 WITH PreviousDay AS ( SELECT date, price, row_number() over (partition by 1 order by date) rn FROM OrderTable ) SELECT p1.date, p1.price, p2.price FROM Previousday p1 LEFT JOIN Previousday p2 ON p1.RN = p2.RN ORDER BY Date -- esempio 2 SELECT date, price, LAG(price) OVER (ORDER By date) PreviousPrice FROM OrderTable ORDER BY Table
-
- Mettere una lista di valori in una variabile :
-
//COALESCE (es: mettere una lista di valori in una variabile) IF OBJECT_ID('TempDB.dbo.#MyTempTable') IS NOT NULL DROP TABLE #MyTempTable CREATE TABLE #MyTempTable(FCT_DT Date) INSERT INTO #MyTempTable VALUES ('01/01/2020'), ('02/01/2020'), ('03/01/2020') DECLARE @Pippo varchar(4000); SELECT @Pippo = COALESCE(@Pippo + ', ', '') + CAST(FCT_DT As varchar) FROM #MyTempTable PRINT @Pippo; //2020-01-01, 2020-02-01, 2020-03-01
-
- Eliminare righe duplicate :
-
//table Duplicates(BirthDate, FirstName, LastName, Address, City, State) WITH RemoveDuplicates AS ( SELECT BirthDate, FirstName, LastName, Address, City, State, ROW_NUMBER() OVER (PARTITION BY BirthDate, FirstName, LastName, Address, City, State ORDER BY BirthDate) RN FROM Duplicates ) -- SELECT * FROM RemoveDuplicates DELETE FROM RemoveDuplicates WHERE RN <> 1 //Elimino tutte le righe doppi
-
- CTE di tipo ricorsivo :
- E’ possibile creare una query con WITH e UNION ALL in modo da definire
- un primo membro che sarà lo statement di base.
- un secondo membro che userà il primo in modo ricorsivo.
-
//syntax WITH cte_name AS ( CTE_query_definition -- anchor member definition UNION ALL -- split anchor CTE_recursive_query_definition -- recursive member ) SELECT * FROM cte_name //esempio //visualizzo tutte le date del mese corrente WITH dates_tab (date_field) as ( -- 2023-05-01 SELECT DATEFROMPARTS(YEAR(GETDATE()), MONTH(GETDATE()), 1) AS date_field UNION ALL -- 2023-05-02 .. 2023-05-31 SELECT DATEADD(day, 1, date_field) FROM dates_tab WHERE date_field < EOMONTH(GETDATE()) ) SELECT date_field FROM dates_tab OPTION (maxrecursion 32767) -- interrompe l'esecuzione in caso di loop infinito
- E’ possibile creare una query con WITH e UNION ALL in modo da definire
- Pivot Transform :
![]()
-
-
//Nel caso in futuro si abbia un nuovo 'TransactionType' //é necessario modificare manualmente la query' SELECT FactDate, CustomerName, COALESCE(Voice, 0.0000) Net_Voice, COALESCE(Data, 0.0000) Net_Data, COALESCE(SMS, 0.0000) Net_SMS FROM data_table PIVOT ( SUM(NetAmout) FOR TransactionType IN (Voice, Data, SMS) ) AS pvt
-
- Merge statement :
-
MERGE table1 t1 USING table2 t2 ON t1.field1 = t2.field1 -- t1.field1 is equal to t2.field1 WHEN MATCHED [AND additional condition] THEN --update statement UPDATE SET field1 = t2.field1 -- t1.field1 is different from t2.field1 WHEN NOT MATCHED [AND additional condition] THEN --insert statement INSERT(field1, field2, ..) VALUES(t2.field1, t2.field2, ..);
-
- Dynamic SQL
- sp_executesql(string)
- EXEC(string)
-
DECLARE @FCT_DT DATE = '06/05/2016' DECLARE @table VARCHAR(50) = 'Product' DECLARE @strFactDate VARCHAR(8) = Convert(varchar, @FCT_DT, 112) DECLARE @newtable NVARCHAR(MAX) = @table + '_' + @strFactDate DECLARE @sql NVARCHAR(MAX) DECLARE @cols NVARCHAR(MAX) = N'' --empty string DECLARE @debug INT = 1 IF OBJECT_ID(@newtable) IS NOT NULL BEGIN DECLARE @strNewtableDrop nvarchar(max) = 'DROP TABLE ' + QUOTENAME(@newtable) EXEC(@strNewtableDrop); END -- N' => It's declaring the string as nvarchar data type, rather than varchar SELECT @cols += N', [' + name + '] ' + system_type_name + case is_nullable when 1 then ' NULL' else ' NOT NULL' end FROM sys.dm_exec_describe_first_result_set('SELECT * FROM ' + @table, NULL, 1) -- tolgo i primi due caratteri dalla variabile @cols (= substring(1,lenght)) SET @cols = STUFF(@cols, 1, 2, N''); -- creo lo statement dinamico di creazione della nuova tabelle a partire dalla vecchia SET @sql = N'CREATE TABLE ' + @newtable + '(' + @cols + ')' --@newtable = @table_20160506 IF NOT EXISTS (SELECT 1 FROM sys.tables WHERE OBJECT_NAME(object_id) = @newtable) IF @DEBUG = 1 PRINT @SQL -- in debug mode visualizzo soltanto lo statement dinamico ELSE EXEC sp_executesql @sql -- eseguo lo statement costruito in modo dinamico
- OVER (Running total / Totale parziale)
- Window Functions – Analytical
- First_value, Last_value, Lag, Lead, Cume_dist, percent_rank
-
//visualizzare 2 colonne con il primo e l'ultimo prezzo di ogni mese,anno SELECT FIRST_VALUE(price) OVER (partition by MONTH(date), YAER(date) Order by date) FirstMonthPrice, LAST_VALUE(price) OVER (partition by MONTH(date), YAER(date) Order by date ROWS BETWEEN CURRENT ROW AND UNBOUNDEN FOLLOWING) LastMonthPrice FROM OrderTable ORDER BY DATE //
- Window Functions – Aggregate
- Sum, Min, Max, Count, Avg.
- Window Functions – Framing
- Range/Rows
- Preceding, Following
- Unbounded, Current
- Range/Rows
-
-- Di default OVER() utilizzata RANGE che implica l'utilizzo di 'tempDb' SELECT CustomerId, SalesOrderID, Total SUM(Total) OVER (PARTITION BY CustomerId ORDER BY SalesOrderID) AS RunningTotal -- Posso forzare OVER(à a utilizzare ROWS invece di RANGE -- In questo caso l'engine SQL farà la propria elaborazione 'InMemory' -- utilizzando cosi' meno risorse. SELECT CustomerId, SalesOrderID, Total SUM(Total) OVER (PARTITION BY CustomerId ORDER BY SalesOrderID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS RunningTotal
- Window Functions – Analytical
Connection Strings
-
//LocalDB "ConnectionStrings": { "DefaultConnection": "Server=(localdb)\\MSSQLLocalDB;Database=CookBook;Trusted_Connection=True" oppure "DefaultConnection": "Server=localhost\\sqlexpress;Database=CookBook;Trusted_Connection=True" } //Server locale "ConnectionStrings": { "DefaultConnection": "Server=<server-name> | .; Database=vega; User Id=sa; Password=Halifax1_;" } //Server remoto "ConnectionStrings": { "DefaultConnection": "Server=127.0.0.1; Database=vega; User Id=sa; Password=Halifax1_;" } //AttachedDB "ConnectionStrings": { "DefaultConnection": "Data Source=(LocalDb)\MSSQLLocalDB;AttachDbFilename=|DataDirectory|\aspnet-Vidly-20220328110027.mdf; Initial Catalog=aspnet-Vidly-20220328110027;Integrated Security=True" }
SQL Server Integration Services (SSIS)
- ETL tool di Windows.
- E’ necessario installare:
- Install the SQL Server.
- Install the SQL Server Data Tools.
- E’ un data warehousing tool usato per
- Estrazione dei dati
- Caricare i dati in un altro DB
- Trasformazione dei dati per pulirli, cumularli, fonderli
- Contiene tool grafici wizard workflow per
- Inviare mail.
- Realizzare invii ftp.
- Collegarsi a sorgenti dati.
- Realizza due operazioni principali
- Data integration
- Fornesce all’utente finale una versione unificata dei dati provenienti da più fonti distinte.
- I dati possono essere omogenei o eterogenei.
- Workflow
- Permette di eseguire dei task predeterminati in funzione di
- Un dato periodo.
- Dati in ingresso.
- Dati recuperati da query.
- Permette di eseguire dei task predeterminati in funzione di
- Data integration
- SSIS Packages
- Permettono di creare dei task sia di tipo ‘Data integration’ che ‘Workflow’
- 3 steps
- Operational Data (sorgente)
- ETL (processo a 4 fasi)
- Capture/Extract :
- Fase di recupero dei dati dalla sorgente. I dati possono essere i diversi formati (xml, flat file, DB)
- Scrub
- Fase di verifica della correttezza e consistenza dei dati.
- Transform:
- Fase di nuova modellizzazione dei dati secondo le specifiche indicate del’utente. Cambiare il numero o la posizione delle colonne.
- Load e Index
- Carica i nuovi dati nella destinazione e indica il numero di righe processate.
- Viene lanciata la fase di indicizzazione in modo di evidenziare i nuovi dati inseriti.
- Capture/Extract :
- Operational Data (destinazione)
- Un package é formato da 3 componenti
- Connessioni ai dati.
- Elementi di tipo control flow.
- Elementi di tipo data flow.
- SSIS Tasks
- In un package é possibile aggiungere dei task.
- Un task é una singola unita di lavoro.
Temporary Data (CTE, Temp Table, Temp variable)
- CTE (Common Table Expression) =>
- Sono creare in-memory (non é possibile creare PK o indici).
- E’ un set di dati temporaneo, tipicamente il risultato di una query complessa.
- Scope => Set di dati della query stessa.
- E’ definito usando il comando WITH.
- E’ possibile eliminare FISICAMENTE delle righe nel DB facendo un DELETE su una CTE.
- Aumenta la leggibilità di query complesse con molte sub-query.
-
;With CTE1(Address, Name, Age) --Column names for CTE, which are optional AS ( SELECT Addr.Address, Emp.Name, Emp.Age FROM Address Addr INNER JOIN EMP Emp ON Emp.EID = Addr.EID ) SELECT * FROM CTE1 -- Using CTE WHERE CTE1.Age > 50 ORDER BY CTE1.NAME - Utilizzo:
- Memorizzare il risultato di una subquery complessa per utilizzarlo in seguito.
- Creare query ricorsive.
- Temp Table (#nametable o ##nametable) =>
- Sono create nel database TempDb.
- Sono create a runtime ed é possibile effettuare ogni operazione tipica di una normale tabella.
- Creare constraints.
- Indici non-clustered.
- Local temporary table :
- Scope => La sessione corrente dello user corrente (quando la query window é chiusa, la temp table é persa).
-
CREATE TABLE #LocalTemp ( UserID int, Name varchar(50), Address varchar(150) ) GO INSERT INTO #LocalTemp values ( 1, 'Shailendra','Noida'); GO SELECT * FROM #LocalTemp; ---------------- IF OBJECT_ID('TempDB.dbo.#MyTempTable') IS NOT NULL DROP TABLE #MyTempTable CREATE TABLE #MyTempTable(FCT_DT Date) INSERT INTO #MyTempTable VALUES ('01/01/2020'), ('02/01/2020'), ('03/01/2020') SELECT * FROM #MyTempTable
- Global temporary table :
- Scope => Tutte le connessioni e tutti gli user correnti.
-
CREATE TABLE ##GlobalTemp ( UserID int, Name varchar(50), Address varchar(150) ) GO insert into ##GlobalTemp values ( 1, 'Shailendra','Noida'); GO Select * from ##GlobalTemp
- Temp Variable (@nametable) =>
- Sono create nel database TempDb.
- Agisce come una variabile in un particolare batch
- Scope => Batch in cui é definita.
- Permette la creazione della PK.
- Non permette la creazione di indici non-clustered.
-
GO DECLARE @TProduct TABLE ( SNo INT IDENTITY(1,1), ProductID INT, Qty INT ) --Insert data to Table variable @Product INSERT INTO @TProduct(ProductID,Qty) SELECT DISTINCT ProductID, Qty FROM ProductsSales ORDER BY ProductID ASC --Select data SELECT * FROM @TProduct --Next batch GO SELECT * FROM @TProduct --gives error in next batch
Risorse